python使用hdfs3模块对hdfs进行操作详解
之前一直使用hdfs的命令进行hdfs操作,比如:
hdfs dfs -ls /user/spark/ hdfs dfs -get /user/spark/a.txt /home/spark/a.txt #从HDFS获取数据到本地 hdfs dfs -put -f /home/spark/a.txt /user/spark/a.txt #从本地覆盖式上传 hdfs dfs -mkdir -p /user/spark/home/datetime=20180817/ ....
身为一个python程序员,每天操作hdfs都是在程序中写各种cmd调用的命令,一方面不好看,另一方面身为一个Pythoner这是一个耻辱,于是乎就挑了一个hdfs3的模块进行hdfs的操作,瞬间就感觉优雅多了:
hdfs 官方API:https://hdfs3.readthedocs.io/en/latest/api.html
>>> from hdfs3 import HDFileSystem
#链接HDFS
>>> hdfs = HDFileSystem(host='localhost', port=8020)
>>> hdfs.ls('/user/data')
>>> hdfs.put('local-file.txt', '/user/data/remote-file.txt')
>>> hdfs.cp('/user/data/file.txt', '/user2/data')
#文件读取
#txt文件全部读取
>>> with hdfs.open('/user/data/file.txt') as f:
... data = f.read(1000000)
#使用pandas读取1000行数据
>>> with hdfs.open('/user/data/file.csv.gz') as f:
... df = pandas.read_csv(f, compression='gzip', nrows=1000)
#写入文件
>>> with hdfs.open('/tmp/myfile.txt', 'wb') as f:
... f.write(b'Hello, world!')
#多节点连接设置
host = "nameservice1"
conf = {"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode113,namenode188",
"dfs.namenode.rpc-address.nameservice1.namenode113": "hostname_of_server1:8020",
"dfs.namenode.rpc-address.nameservice1.namenode188": "hostname_of_server2:8020",
"dfs.namenode.http-address.nameservice1.namenode188": "hostname_of_server1:50070",
"dfs.namenode.http-address.nameservice1.namenode188": "hostname_of_server2:50070",
"hadoop.security.authentication": "kerberos"
}
fs = HDFileSystem(host=host, pars=conf)
#API
hdfs = HDFileSystem(host='127.0.0.1', port=8020)
hdfs.cancel_token(token=None) #未知,求大佬指点
hdfs.cat(path) #获取指定目录或文件的内容
hdfs.chmod(path, mode) #修改制定目录的操作权限
hdfs.chown(path, owner, group) #修改目录所有者,以及用户组
hdfs.concat(destination, paths) #将指定多个路径paths的文件,合并成一个文件写入到destination的路径,并删除源文件(The source files are deleted on successful completion.成功完成后将删除源文件。)
hdfs.connect() #连接到名称节点 这在启动时自动发生。 LZ:未知作用,按字面意思,应该是第一步HDFileSystem(host='127.0.0.1', port=8020)发生的
hdfs.delegate_token(user=None)
hdfs.df() #HDFS系统上使用/空闲的磁盘空间
hdfs.disconnect() #跟connect()相反,断开连接
hdfs.du(path, total=False, deep=False) #查看指定目录的文件大小,total是否把大小加起来一个总数,deep是否递归到子目录
hdfs.exists(path) #路径是否存在
hdfs.get(hdfs_path, local_path, blocksize=65536) #将HDFS文件复制到本地,blocksize设置一次读取的大小
hdfs.get_block_locations(path, start=0, length=0) #获取块的物理位置
hdfs.getmerge(path, filename, blocksize=65536) #获取制定目录下的所有文件,复制合并到本地文件
hdfs.glob(path) #/user/spark/abc-*.txt 获取与这个路径相匹配的路径列表
hdfs.head(path, size=1024) #获取指定路径下的文件头部分的数据
hdfs.info(path) #获取指定路径文件的信息
hdfs.isdir(path) #判断指定路径是否是一个文件夹
hdfs.isfile(path) #判断指定路径是否是一个文件
hdfs.list_encryption_zones() #获取所有加密区域的列表
hdfs.ls(path, detail=False) #返回指定路径下的文件路径,detail文件详细信息
hdfs.makedirs(path, mode=457) #创建文件目录类似 mkdir -p
hdfs.mkdir(path) #创建文件目录
hdfs.mv(path1, path2) #将path1移动到path2
open(path, mode='rb', replication=0, buff=0, block_size=0) #读取文件,类似于python的文件读取
hdfs.put(filename, path, chunk=65536, replication=0, block_size=0) #将本地的文件上传到,HDFS指定目录
hdfs.read_block(fn, offset, length, delimiter=None) #指定路径文件的offset指定读取字节的起始点,length读取长度,delimiter确保读取在分隔符bytestring上开始和停止
>>> hdfs.read_block('/data/file.csv', 0, 13)
b'Alice, 100\nBo'
>>> hdfs.read_block('/data/file.csv', 0, 13, delimiter=b'\n')
b'Alice, 100\nBob, 200'
hdfs.rm(path, recursive=True) #删除指定路径recursive是否递归删除
hdfs.tail(path, size=1024) #获取 文件最后一部分的数据
hdfs.touch(path) #创建一个空文件
hdfs.walk(path) #遍历文件树
补充知识:HDFS命令批量创建文件夹和文件
批量创建测试文件夹:
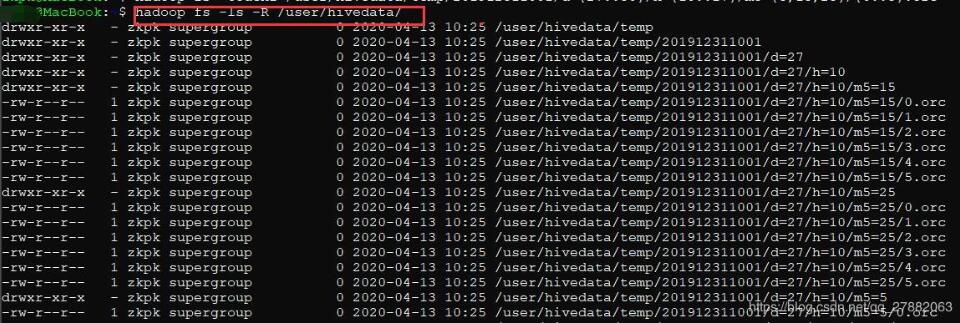
hadoop fs -mkdir -p /user/hivedata/temp/201912311001/d={27..30}/h={10..17}/m5={5,15,25}/
批量创建测试文件:
hadoop fs -touchz /user/hivedata/temp/201912311001/d={27..30}/h={10..17}/m5={5,15,25}/{0..5}.orc
最终效果:
hadoop fs -ls -R /user/hivedata/
以上这篇python使用hdfs3模块对hdfs进行操作详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python访问hdfs的操作
pip install hdfs python 读取hdfs目录或文件 import hdfs client =hdfs.Client("http://10.10.1.4:50070") fileDir="/user/hive/warehouse/house.db/dm_house/dt=201800909" try: status=client.status(fileDir,False) if status: print (status) rst=client.d
-
Python API 操作Hadoop hdfs详解
http://pyhdfs.readthedocs.io/en/latest/ 1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client--创建集群连接 > from hdfs import * > client = Client("http://s100:50070") 其他参数说明: classhdfs.client.Client(url, ro
-
完美解决python针对hdfs上传和下载的问题
当我们使用python的hdfs包进行上传和下载文件的时候,总会出现如下问题 requests.packages.urllib3.exceptions.NewConnectionError:<requests.packages.urllib3.connection.HTTPConnection object at 0x7fe87cc37c50>: Failed to establish a new connection: [Errno -2] Name or service not known
-
python3.6.5基于kerberos认证的hive和hdfs连接调用方式
1. Kerberos是一种计算机网络授权协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证.具体请查阅官网 2. 需要安装的包(基于centos) yum install libsasl2-dev yum install gcc-c++ python-devel.x86_64 cyrus-sasl-devel.x86_64 yum install python-devel yum install krb5-devel yum install python-krbV pip insta
-
python使用hdfs3模块对hdfs进行操作详解
之前一直使用hdfs的命令进行hdfs操作,比如: hdfs dfs -ls /user/spark/ hdfs dfs -get /user/spark/a.txt /home/spark/a.txt #从HDFS获取数据到本地 hdfs dfs -put -f /home/spark/a.txt /user/spark/a.txt #从本地覆盖式上传 hdfs dfs -mkdir -p /user/spark/home/datetime=20180817/ .... 身为一个python程
-
Python反射和内置方法重写操作详解
本文实例讲述了Python反射和内置方法重写操作.分享给大家供大家参考,具体如下: isinstance和issubclass isinstance(obj,cls)检查是否obj是否是类 cls 的对象,类似 type() class Foo(object): pass obj = Foo() isinstance(obj, Foo) issubclass(sub, super)检查sub类是否是 super 类的派生类 class Foo(object): pass class Bar(Fo
-
Python中sys模块功能与用法实例详解
本文实例讲述了Python中sys模块功能与用法.分享给大家供大家参考,具体如下: sys-系统特定的参数和功能 该模块提供对解释器使用或维护的一些变量的访问,以及与解释器强烈交互的函数.它始终可用. sys.argv 传递给Python脚本的命令行参数列表.argv[0]是脚本名称(依赖于操作系统,无论这是否是完整路径名).如果使用-c解释器的命令行选项执行命令,argv[0]则将其设置为字符串'-c'.如果没有脚本名称传递给Python解释器,argv[0]则为空字符串. 要循环标准输入或命
-

python飞机大战pygame游戏框架搭建操作详解
本文实例讲述了python飞机大战pygame游戏框架搭建操作.分享给大家供大家参考,具体如下: 目标 明确主程序职责 实现主程序类 准备游戏精灵组 01. 明确主程序职责 回顾 快速入门案例,一个游戏主程序的 职责 可以分为两个部分: 游戏初始化 游戏循环 根据明确的职责,设计 PlaneGame 类如下: 提示 根据 职责 封装私有方法,可以避免某一个方法的代码写得太过冗长 如果某一个方法编写的太长,既不好阅读,也不好维护! 游戏初始化 -- init() 会调用以下方法: 游戏循环 --
-
Python利用ElementTree模块处理XML的方法详解
前言 最近因为工作的需要,在使用 Python 来发送 SOAP 请求以测试 Web Service 的性能,由于 SOAP 是基于 XML 的,故免不了需要使用 python 来处理 XML 数据.在对比了几种方案后,最后选定使用 xml.etree.ElementTree 模块来实现. 这篇文章记录了使用 xml.etree.ElementTree 模块常用的几个操作,也算是总结一下,免得以后忘记了.分享出来也方法需要的朋友们参考学习,下面话不多说了,来一起看看详细的介绍吧. 概述 对比其他
-
python爬虫 urllib模块反爬虫机制UA详解
方法: 使用urlencode函数 urllib.request.urlopen() import urllib.request import urllib.parse url = 'https://www.sogou.com/web?' #将get请求中url携带的参数封装至字典中 param = { 'query':'周杰伦' } #对url中的非ascii进行编码 param = urllib.parse.urlencode(param) #将编码后的数据值拼接回url中 url += p
-
Python使用smtplib模块发送电子邮件的流程详解
1.登录SMTP服务器 首先使用网上的方法(这里使用163邮箱,smtp.163.com是smtp服务器地址,25为端口号): import smtplib server = smtplib.SMTP('smtp.163.com', 25) server.login('j_hao104@163.com', 'password') Traceback (most recent call last): File "C:/python/t.py", line 192, in <modu
-
Python实现发送与接收邮件的方法详解
本文实例讲述了Python实现发送与接收邮件的方法.分享给大家供大家参考,具体如下: 一.发送邮件 这里实现给网易邮箱发送邮件功能: import smtplib import tkinter class Window: def __init__(self,root): label1 = tkinter.Label(root,text='SMTP') label2 = tkinter.Label(root,text='Port') label3 = tkinter.Label(root,text
-
Python基于plotly模块实现的画图操作示例
本文实例讲述了Python基于plotly模块实现的画图操作.分享给大家供大家参考,具体如下: import plotly plotly.tools.set_credentials_file(username='tianjixuetu', api_key='xxxxxxxx')#此处要去官网申请自己的api,#https://plot.ly/ssu/ #案例1 import plotly.plotly as py from plotly.graph_objs import * trace0 =
-
Python使用jsonpath-rw模块处理Json对象操作示例
本文实例讲述了Python使用jsonpath-rw模块处理Json对象操作.分享给大家供大家参考,具体如下: 这两天在写一个爬虫,需要从网站返回的json数据提取一些有用的数据. 向url发起请求,返回的是response,在python3中,response.content是二进制bytes类型的,需要用decode()转成unicode的str类型 #如果用的requests发的请求 import json response = requests.get(url,headers=self.