Python如何自动获取目标网站最新通知

不管是一名学生,亦或是一名员工,我们都需要时刻注意学校或公司网站的通知,尽量做到即时获取最新消息。
大部分博客或数据资源网站都会有自己的RSS提示系统,便于将网站的最新信息及时推送给需要的用户,而用户也可以通过RSS阅读器来即时地获取到目标网站的最新内容。
由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统。
作为优秀的人儿,我们可以建立自己的RSS提示系统。
这里介绍了如何使用Python和常用的计算机小程序来构建一个RSS提示系统,做到定时自动检测目标网站发布的通知,并即时发送提示邮件。
本期文章设计RSS提示系统的主要思路是:
- 爬取目标网站内容,建立本地已有通知数据库;
- 模拟smtp服务器,建立邮件发送系统;
- 解析检测目标网站发布的通知,若有新内容,则更新数据库并发送提示邮件;
- 制定计划任务实现定时自动执行Python脚本程序。
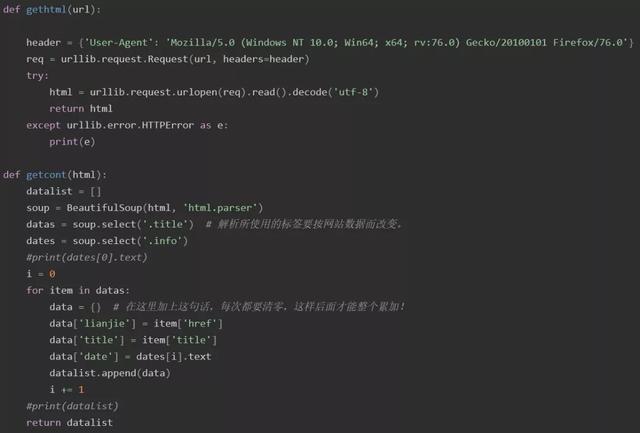
1.建立通知数据库
这一步的目的是爬取目标网站已经发布的通知的数据,并进行存储,从而建立与该目标网站内容相对应的本地数据库。
考虑到数据库中的数据将是辨别和获取一则新通知的唯一方法,因此所建立的数据库将存储每一条通知的标题、发布日期和访问链接。
第一步使用到的模块有urllib、BeautifulSoup和sqlite3模块。其中,通过urllib模块爬取目标网页html数据;通过BeautifulSoup模块解析网页数据、爬取网页内容;通过sqlite3模块建立目标网站已有通知数据库。
该步主要代码展示如下。
2.建立邮件发送系统
这一步的目的是使用Python标准库模块smtplib来访问网络,创建一个发送电子邮件的功能。
由于我们大部分人的计算机并没有建立自己的邮件服务器,因此需借助第三方服务器来模拟邮件发送。
常用的有谷歌邮件系统、网易邮件系统和QQ邮件系统,如QQ邮件系统的SMTP服务器和端口号分别为smtp.qq.com和465。
该步主要代码展示如下。
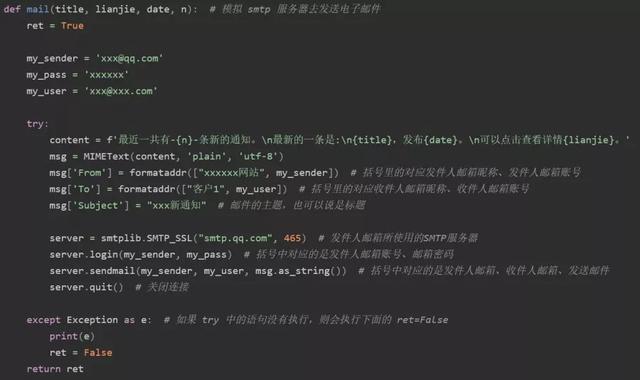
在这个示例中,使用了Python标准库中的email模块将电子邮件信息进行了格式化,主要包括邮件的主题与发件人、收件人邮箱昵称和邮件内容等信息。
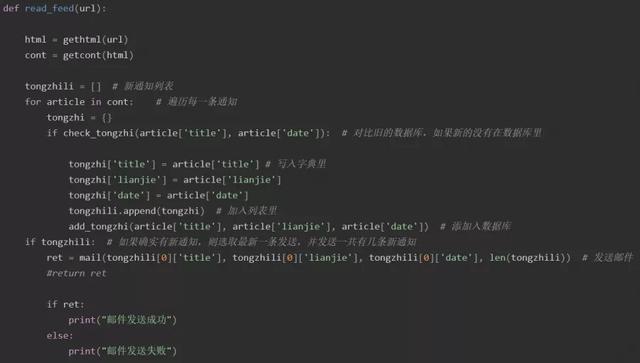
3.解析检测目标网站通知
前面两步,已经完成了目标网站已有通知数据库和邮件发送系统的建立,第三步要完成的工作,主要由两部分组成。
一是,利用第一步使用的urllib、BeautifulSoup模块解析目标网站内容数据,并与前面建立的数据库进行对比检测。
二是,若检测到目标网站有新的通知,则将新通知数据插入到数据库中,然后,发送提示电子邮件。
该步主要代码展示如下。
在这个示例中,只选取了最新的一条通知发送了电子邮件提示,具体邮件信息可自己设定。
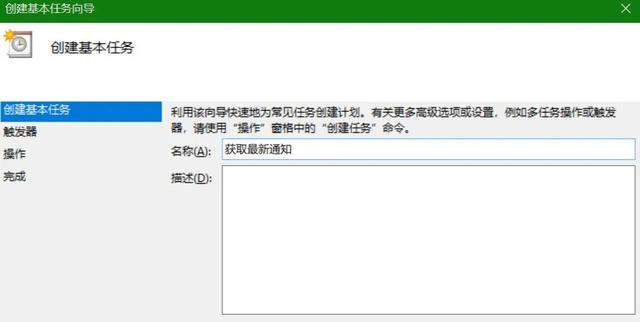
4.制定计划任务
前面三步,已经完成了使用Python获取目标网站最新通知,并发送提示电子邮件的脚本程序。
在这一步,将使用Windows自带的DOS命令框架和任务计划程序去每小时自动运行一次Python脚本,实现自动更新通知的目的。
首先,需要编写一个cmd命令文件,方便在DOS框架下执行Python脚本。
主要代码展示如下:
@echo off # 关闭回显 cd C:\demo # 找到Python脚本文件的路径 python Python.py # 执行Python脚本文件
最后,使用任务计划程序制定一个任务,可设定为每隔一小时自动运行一次cmd命令文件。
总结
到此这篇关于Python如何自动获取目标网站最新通知的文章就介绍到这了,更多相关python自动获取最新通知内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python之自动获取公网IP的实例讲解
0.预备知识 0.1 SQL基础 ubuntu.Debian系列安装: root@raspberrypi:~/python-script# apt-get install mysql-server Redhat.Centos 系列安装: [root@localhost ~]# yum install mysql-server 登录数据库 pi@raspberrypi:~ $ mysql -uroot -p -hlocalhost Enter password: Welcome to the Ma
-
Python 实现自动获取种子磁力链接方式
因为我闲来无事,所以准备找一部电影来看看. 然后我找到了种子搜索网站,可是这类网站的弹窗广告太多,搞得我很烦.所以我就想着自己用python写一个自动获取磁力链接的脚本. 整个大概写了半个小时. 代码如下 import requests import re from bs4 import BeautifulSoup url="*种子的网站*/" header={ "Accept":"text/html,application/xhtml+xml,appli
-
python实现自动获取IP并发送到邮箱
树莓派没有显示器,而不想设置固定IP,因为要随身携带外出,每个网络环境可能网段不一样.因此想用python写个脚本,让树莓派开机后自动获取本机ip,并且自动发送到我指定邮箱.(完整源码) 1.获取所有连接的网络接口,比如有线.wifi等接口 def get_ip_address(): #先获取所有网络接口 SIOCGIFCONF = 0x8912 SIOCGIFADDR = 0x8915 BYTES = 4096 sck = socket.socket(socket.AF_INET, socke
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
Python如何自动获取目标网站最新通知
不管是一名学生,亦或是一名员工,我们都需要时刻注意学校或公司网站的通知,尽量做到即时获取最新消息. 大部分博客或数据资源网站都会有自己的RSS提示系统,便于将网站的最新信息及时推送给需要的用户,而用户也可以通过RSS阅读器来即时地获取到目标网站的最新内容. 由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统. 作为优秀的人儿,我们可以建立自己的RSS提示系统. 这里介绍了如何使用Python和常用的计算机小程序来构建一个RSS提示系统,做到定时自动检测目标网站发布的通知,并
-
Python使用代理抓取网站图片(多线程)
一.功能说明:1. 多线程方式抓取代理服务器,并多线程验证代理服务器ps 代理服务器是从http://www.cnproxy.com/ (测试只选择了8个页面)抓取2. 抓取一个网站的图片地址,多线程随机取一个代理服务器下载图片二.实现代码 复制代码 代码如下: #!/usr/bin/env python#coding:utf-8 import urllib2import reimport threadingimport timeimport random rawProxyList = []ch
-
python自动获取微信公众号最新文章的实现代码
目录 微信公众号获取思路 采集实例 微信公众号获取思路 常用的微信公众号文章获取方法有搜狐.微信公众号主页获取和api接口等多个方法.听说搜狐最近不怎么好用了,之前用的api接口也频繁维护,所以用了微信公众平台来进行数据爬取.首先登陆自己的微信公众平台,没有账号的可以注册一个.进来之后找“图文信息”,就是写公众号的地方 点进去后就是写公众号文章的界面,在界面中找到“超链接” 的字段,在这里就可以对其他的公众号进行检索. 以“python”为例,输入要检索的公众号名称,在显示的公众号中选择要采集的
-
python网络爬虫之模拟登录 自动获取cookie值 验证码识别的具体实现
目录 1.爬取网页分析 2.验证码识别 3.cookie自动获取 4.程序源代码 chaojiying.py sign in.py 1.爬取网页分析 爬取的目标网址为:https://www.gushiwen.cn/ 在登陆界面需要做的工作有,获取验证码图片,并识别该验证码,才能实现登录. 使用浏览器抓包工具可以看到,登陆界面请求头包括cookie和user-agent,故在发送请求时需要这两个数据.其中user-agent可通过手动添加到请求头中,而cookie值需要自动获取. 分析完毕,实践
-
Python使用OPENCV的目标跟踪算法实现自动视频标注效果
先上效果 1.首先,要使用opencv的目标跟踪算法,必须要有opencv环境 使用:opencv==4.4.0 和 opencv-contrib-python==4.4.0.46,lxml 这三个环境包. 也可以使用以下方法进行下载 : pip install opencv-python==4.4.0 pip install opencv-contrib-python==4.4.0.4 pip install lxml 2.使用方法: (1):英文状态下的 "s" 是进行标注 (
-
Python获取基金网站网页内容、使用BeautifulSoup库分析html操作示例
本文实例讲述了Python获取基金网站网页内容.使用BeautifulSoup库分析html操作.分享给大家供大家参考,具体如下: 利用 urllib包 获取网页内容 #引入包 from urllib.request import urlopen response = urlopen("http://fund.eastmoney.com/fund.html") html = response.read(); #这个网页编码是gb2312 #print(html.decode("