一文读懂python Scrapy爬虫框架
Scrapy是什么?
先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy是一个非常好用的爬虫框架,它不仅提供了一些开箱即用的基础组件,还提供了强大的自定义功能。
# Scrapy 安装
Scrapy 官网:https://scrapy.org/
各位同学的电脑环境应该和小编的相差不远(如果是使用 win10 的话) 安装过程需要10分钟左右
安装命令:
pip install scrapy
由于 Scrapy 依赖了大量的第三方的包,所以在执行上面的命令后并不会马上就下载 Scrapy ,而是会先不断的下载第三方包,包括并不限于以下几种:
- pyOpenSSL:Python 用于支持 SSL(Security Socket Layer)的包。
- cryptography:Python 用于加密的库。
- CFFI:Python 用于调用 C 的接口库。
- zope.interface:为 Python 缺少接口而提供扩展的库。
- lxml:一个处理 XML、HTML 文档的库,比 Python 内置的 xml 模块更好用。
- cssselect:Python 用于处理 CSS 选择器的扩展包。
- Twisted:为 Python 提供的基于事件驱动的网络引擎包。
- ……
如果安装不成功多试两次 或者 执行pip install --upgrade pip 后再执行 pip install scrapy
等待命令执行完成后,直接输入 scrapy 进行验证。
C:\Users\Administrator>scrapy Scrapy 2.4.0 - no active project Available commands: bench Run quick benchmark test ...
版本号可能会有差别,不用太在意
如果能正常出现以上内容,说明我们已经安装成功了。
理论上 Scrapy 安装出现各种问题才算正常情况
三、Scrapy创建项目
Scrapy 提供了一个命令来创建项目 scrapy 命令,在命令行上运行:
scrapy startproject jianshu
我们创建一个项目jianshu用来爬取简书首页热门文章的所有信息。
jianshu/ scrapy.cfg jianshu/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
spiders文件夹下就是你要实现爬虫功能(具体如何爬取数据的代码),爬虫的核心。在spiders文件夹下自己创建一个spider,用于爬取简书首页热门文章。
scrapy.cfg是项目的配置文件。
settings.py用于设置请求的参数,使用代理,爬取数据后文件保存等。
items.py 自己预计需要爬取的内容
middlewares.py自定义中间件的文件
pipelines.py 管道,保持数据
项目的目录就用网图来展示一下吧
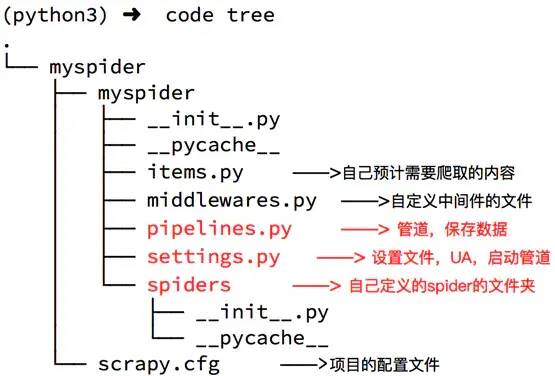
image Scrapy爬取简书首页热门文章
cd到Jianshu项目中,生成一个爬虫:
scrapy genspider jianshublog www.jianshu.com
这种方式生成的是常规爬虫
1)新建jianshuSpider
import scrapy class JianshublogSpider(scrapy.Spider): name = 'jianshublog' allowed_domains = ['www.jianshu.com'] start_urls = ['http://www.jianshu.com/'] def parse(self, response): pass
可以看到,这个类里面有三个属性 name 、 allowed_domains 、 start_urls 和一个parse()方法。
name,它是每个项目唯一的名字,用来区分不同的 Spider。
allowed_domains,它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
start_urls,它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。
parse,它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
到这里我们就清楚了,parse() 方法中的 response 是前面的 start_urls中链接的爬取结果,所以在 parse() 方法中,我们可以直接对爬取的结果进行解析。
修改USER_AGENT
打开settings.py 添加 UA 头信息
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36'
修改`parse`方法解析网页
我们打开简书首页 右键检查(ctrl+shift+I)发现所有的博客头条都放在类名.note-list .content 的div 节点里面
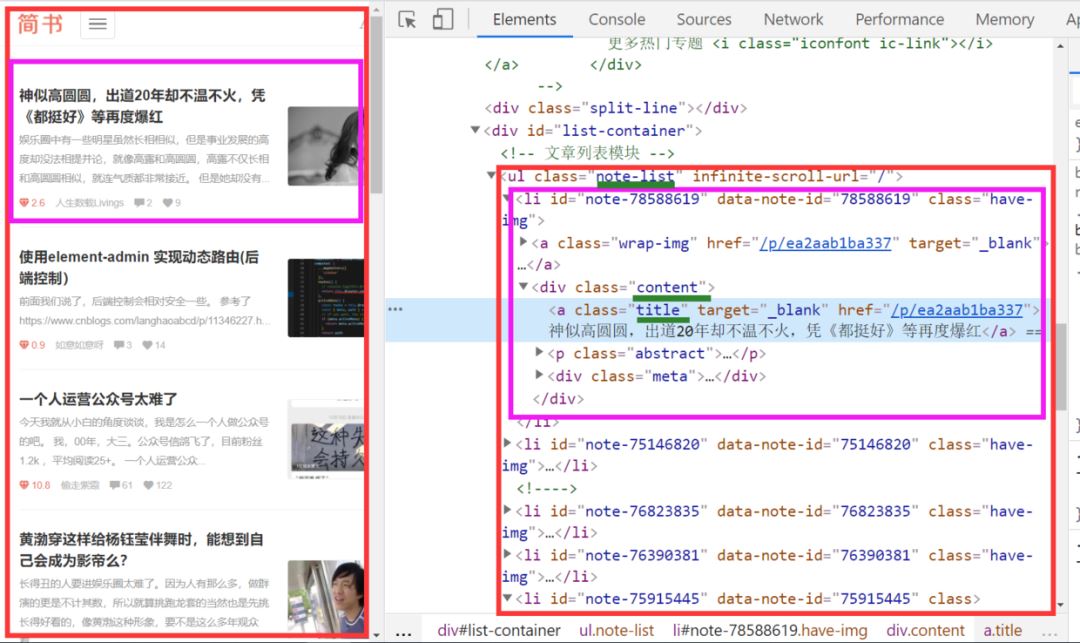
修改jianshublog.py代码如下
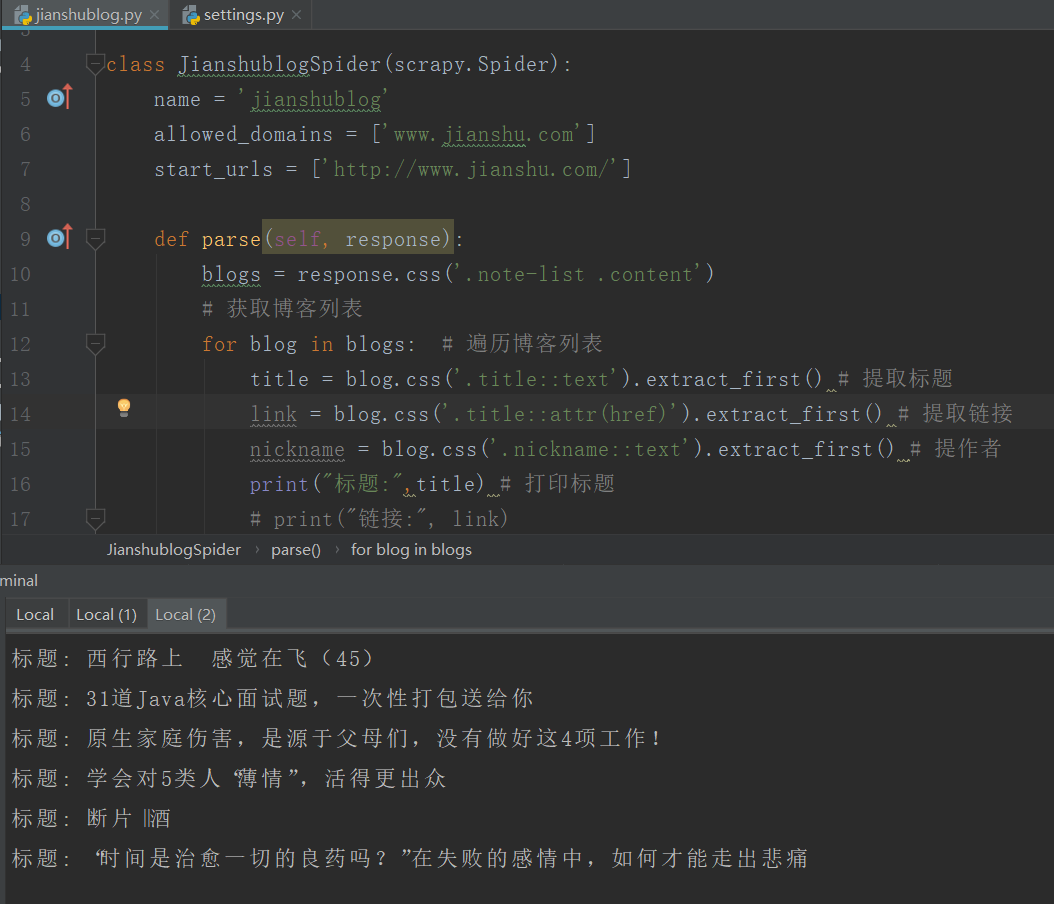
jianshublog.py
import scrapy
class JianshublogSpider(scrapy.Spider):
name = 'jianshublog'
allowed_domains = ['www.jianshu.com']
start_urls = ['http://www.jianshu.com/']
def parse(self, response):
blogs = response.css('.note-list .content')
# 获取博客列表
for blog in blogs: # 遍历博客列表
title = blog.css('.title::text').extract_first() # 提取标题
link = blog.css('.title::attr(href)').extract_first() # 提取链接
nickname = blog.css('.nickname::text').extract_first() # 提作者
print("标题:",title) # 打印标题
# print("链接:", link)
# print("作者:", nickname)
最后别忘了执行爬虫命令
scrapy crawl jianshublog
整个项目就完成啦
下一讲我们把文章数据爬取出来,存储在csv文件里面
到此这篇关于一文读懂python Scrapy爬虫框架的文章就介绍到这了,更多相关python Scrapy爬虫框架内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
Python抓取框架Scrapy爬虫入门:页面提取
前言 Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义.本文主要给大家介绍了关于Python抓取框架Scrapy之页面提取的相关内容,分享出来供大家参考学习,下面随着小编来一起学习学习吧. 在开始之前,关于scrapy框架的入门大家可以参考这篇文章:http://www.jb51.net/article/87820.htm 下面创建一个爬虫项目,以图虫网为例抓取图片. 一.内容分析 打开 图虫网,顶部菜单"发现" "
-
Python的Scrapy爬虫框架简单学习笔记
一.简单配置,获取单个网页上的内容. (1)创建scrapy项目 scrapy startproject getblog (2)编辑 items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy.item import
-
python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
一文读懂python Scrapy爬虫框架
Scrapy是什么? 先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. S
-
一文读懂Python 枚举
enum 是一组绑定到唯一常数值的符号名称,并且具备可迭代性和可比较性的特性.我们可以使用 enum 创建具有良好定义的标识符,而不是直接使用魔法字符串或整数,也便于开发工程师的代码维护. 创建枚举 我们可以使用 class 语法创建一个枚举类型,方便我们进行读写,另外,根据函数 API 的描述定义,我们可以创建一个 enum 的子类,如下: from enum import Enum class HttpStatus(Enum): OK = 200 BAD_REQUEST = 400 FORB
-
python Scrapy爬虫框架的使用
导读:如何使用scrapy框架实现爬虫的4步曲?什么是CrawSpider模板?如何设置下载中间件?如何实现Scrapyd远程部署和监控?想要了解更多,下面让我们来看一下如何具体实现吧! Scrapy安装(mac) pip install scrapy 注意:不要使用commandlinetools自带的python进行安装,不然可能报架构错误:用brew下载的python进行安装. Scrapy实现爬虫 新建爬虫 scrapy startproject demoSpider,demoSpide
-
一文读懂Python版本管理工具Pyenv使用
pyenv简单介绍 在日常运维中, 经常遇到这样的情况: 系统自带的Python是2.x,而业务部署需要Python 3.x 环境, 此时需要在系统中安装多个Python版本,但又不能影响系统自带的Python 版本,即需要实现Python的多版本环境共存, pyenv就是这样一个Python版本管理器, 可以同时管理多个python版本共存! 简单的说,pyenv 可以根据需求使用户在系统里安装和管理多个Python 版本: - 配置当前用户的python的版本; - 配置当前shell的py
-
windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档 1.找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架 2.
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
详解Python的爬虫框架 Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程(注:图片来自互联网). 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎
-
Python3环境安装Scrapy爬虫框架过程及常见错误
Windows •安装lxml 最好的安装方式是通过wheel文件来安装,http://www.lfd.uci.edu/~gohlke/pythonlibs/,从该网站找到lxml的相关文件.假如是Python3.5版本,WIndows 64位系统,那就找到lxml‑3.7.2‑cp35‑cp35m‑win_amd64.whl 这个文件并下载,然后通过pip安装. 下载之后,运行如下命令安装: pip3 install wheel pip3 install lxml‑3.7.2‑cp35‑cp3