python pdfkit 中文乱码问题的解决方案
使用python pdfkit生成pdf文件中遇到中文乱码问题
1.生成的文件名不能带有中文字符
2.生成的pdf内容中文为乱码
生成的文件名不能带有中文字符
解决方法:
我暂时想到的处理方式是先生成英文文件名,再将这个文件重命名为中文的文件名
#coding=utf8
import os
import pdfkit
from uuid import uuid1
ret = '<html><head><meta charset="UTF-8"></head><body><h1>测试pdf内容部分</h1></body></html>'.decode('utf8')
file_name = str(uuid1())
pdfkit.from_string(ret, file_name) # file_name不能带有中文 如果有会报错
file_name_new = '测试.pdf'
os.rename(file_name, file_name_new)
生成的pdf内容中文为乱码
原因1:
因为pdfkit生成pdf功能其实调用的是webkit的子模块wkhtmltopdf(通过命令行方式),所以pdfkit生成中文乱码其实是wkhtmltopdf中文乱码导致的;而wkhtmltopdf中文乱码是因为系统中不存在中文字体导致的
解决方法:
在系统中添加中文字体
我的本地电脑是ubuntu14.04的字体文件保存在/usr/share/fonts下(包含了中文字体文件具体哪一个我也不知道汗。),我的服务器是redhat系统(没有中文字体),所以在我的电脑上操作如下:
cd /usr/share/fonts zip -r fonts.zip ./* scp fonts.zip 服务器用户名@服务器ip:/usr/share/fonts
在服务器上操作如下:
cd /usr/share/fonts unzip fonts.zip fc-cache -fv fc-list # 查看新添加的字体
你需要找一台有安装了中文字体的电脑复制一份字体文件(就是/usr/share/fonts下的文件),然后如我以上操作就可以了。
原因2:
需要在html的字符集设置为utf8
<head><meta charset="UTF-8"></head>
补充:python写入html文件中文乱码-解决办法
使用open函数将爬虫爬取的html写入文件,有时候在控制台不会乱码,但是写入文件的html中的中文是乱码的
案例分析
看下面一段代码:
# 爬虫未使用cookie
from urllib import request
if __name__ == '__main__':
url = "http://www.renren.com/967487029/profile"
rsp = request.urlopen(url)
html = rsp.read().decode()
with open("rsp.html","w")as f:
# 将爬取的页面
print(html)
f.write(html)
看似没有问题,并且在控制台输出的html也不会出现中文乱码,但是创建的html文件中

解决方案
使用open方法的一个参数,名为encoding=” “,加入encoding=”utf-8”即可
# 爬虫未使用cookie
from urllib import request
if __name__ == '__main__':
url = "http://www.renren.com/967487029/profile"
rsp = request.urlopen(url)
html = rsp.read().decode()
with open("rsp.html","w",encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
运行结果
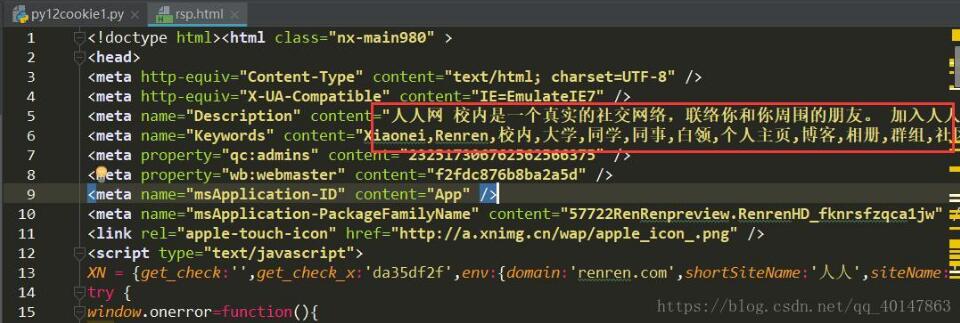
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

python 实现存储数据到txt和pdf文档及乱码问题的解决
第一.几种常用方法 读取TXT文档:urlopen() 读取PDF文档:pdfminer3k 第二.乱码问题 (1). from urllib.request import urlopen #访问wiki内容 html = urlopen("https://en.wikipedia.org/robots.txt") print(html.read()) 输出的结果中出现乱码原因: 计算机只能处理0和1两个数字,所以想要处理文本,必须把文本变成0和1这样的数字,最早的计算机使用八个0和1
-
彻底搞懂 python 中文乱码问题(深入分析)
前言 曾几何时 Python 中文乱码的问题困扰了我很多很多年,每次出现中文乱码都要去网上搜索答案,虽然解决了当时遇到的问题但下次出现乱码的时候又会懵逼,究其原因还是知其然不知其所以然.现在有的小伙伴为了躲避中文乱码的问题甚至代码中不使用中文,注释和提示都用英文,我曾经也这样干过,但这并不是解决问题,而是逃避问题,今天我们一起彻底解决 Python 中文乱码的问题. 基础知识ASCII 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关
-
Python request中文乱码问题解决方案
Python request获取网页中文乱码问题 r = requests.get("http://www.baidu.com") **r.text返回的是Unicode型的数据. 使用r.content返回的是bytes型的数据. 也就是说,如果你想取文本,可以通过r.text. 如果想取图片,文件,则可以通过r.content.** 方法1:使用r.text Requests 会自动解码来自服务器的内容.大多数 unicode 字符集都能被无缝地解码.请求发出后,Requests
-
python中文乱码的解决方法
乱码原因:源码文件的编码格式为utf-8,但是window的本地默认编码是gbk,所以在控制台直接打印utf-8的字符串当然是乱码了! 解决方法:1.print mystr.decode('utf-8').encode('gbk')2.比较通用的方法: 复制代码 代码如下: import systype = sys.getfilesystemencoding()print mystr.decode('utf-8').encode(type)
-
python pdfkit 中文乱码问题的解决方案
使用python pdfkit生成pdf文件中遇到中文乱码问题 1.生成的文件名不能带有中文字符 2.生成的pdf内容中文为乱码 生成的文件名不能带有中文字符 解决方法: 我暂时想到的处理方式是先生成英文文件名,再将这个文件重命名为中文的文件名 #coding=utf8 import os import pdfkit from uuid import uuid1 ret = '<html><head><meta charset="UTF-8"><
-
关于Ajax请求中传输中文乱码问题的解决方案
今天遇到一个问题,有关ajax 请求中传输中文,遇到乱码的问题. 如下代码: function UpdateFolderInfoByCustId(folderId, folderName, custId) { $.ajax({ type: "Post", contentType: "application/x-www-form-urlencoded; charset=utf-8", url: "http://localhost/CRM/Ashx/HandK
-
python 采集中文乱码问题的完美解决方法
近几日遇到采集某网页的时候大部分网页OK,少部分网页出现乱码的问题,调试了几日,终于发现了是含有一些非法字符造成的..特此记录 1. 在正常情况下..可以用 import chardet thischarset = chardet.detect(strs)["encoding"] 来获取该文件或页面的编码方式 或直接抓取页面的charset = xxxx 来获取 2. 遇到内容中有特殊字符时指定的编码一样会造成乱码..即内容中非法字符造成的,可以采用编码忽略非法字符的方式来处理. st
-
Python BeautifulSoup中文乱码问题的2种解决方法
解决方法一: 使用python的BeautifulSoup来抓取网页然后输出网页标题,但是输出的总是乱码,找了好久找到解决办法,下面分享给大家首先是代码 复制代码 代码如下: from bs4 import BeautifulSoupimport urllib2 url = 'http://www.jb51.net/'page = urllib2.urlopen(url) soup = BeautifulSoup(page,from_encoding="utf8")print soup
-
Javascript和Ajax中文乱码吐血版解决方案
今天弄了一天的Ajax中文乱码问题,Ajax的乱码问题分为两种: 1. JavaScript输出的中文乱码, 比如:alert("中文乱码测试"); 解决的办法比较简单,就是把jsp里所有的charset和pageEncoding的值都设置成相同的,一般是utf-8. 2. 这第二种就是Ajax从服务器端获得的数据出现乱码的问题.(我搜了n个小时试了n中方法才找到答案) 现在将我搜集的比较有效的方法都与大家分享:(我使用的开发环境是Eclipse,相信其他语言和开发环境都差不太多.)
-
MYSQL中文乱码问题的解决方案
目录 一.乱码的原因: 二.查看数据库的编码方式 三.解决的办法有俩种: 四.本人在项目遇到乱码问题是以下方法解决的 总结 一.乱码的原因: 1. client客户端的编码不是utf8 2.server端的编码不是utf8 3.database数据库的编码不是utf8 4.数据库的表的编码不是utf8 5.表中的列字段编码不是utf8 主要的原因在于前三个偏多. 二.查看数据库的编码方式 mysql>show variables like 'character%'; 此截图是解决之后的,查看哪个
-
C# newtonsoft.json中文乱码问号的解决方案
目录 C# newtonsoft.json中文乱码问号 C# NewtonJson使用技巧 C# newtonsoft.json中文乱码问号 发送方在序列化json时这样写,比如将gameinfo类序列化成json: string jsonstr=JsonConvert.SerializeObject(gameinfo, new JsonSerializerSettings() { StringEscapeHandling = StringEscapeHandling.EscapeNonAsci
-
python sqlobject(mysql)中文乱码解决方法
UnicodeEncodeError: 'latin-1' codec can't encode characters in position: 找了一天终于搞明白了,默认情况下,mysql连接的编码是latin-1,你需要指定使用什么编码方式: connectionForURI(mysql://user:password@localhost:3306/eflow?use_unicode=1&charset=utf8) Python mysql 中文乱码 的解决方法,有需要的朋友不妨看看. 先来
-
基于python 处理中文路径的终极解决方法
1 .据说python3就没有这个问题了 2 .u'字符串' 代表是unicode格式的数据,路径最好写成这个格式,别直接跟字符串'字符串'这类数据相加,相加之后type就是str,这样就会存在解码失误的问题. 别直接跟字符串'字符串'这类数据相加 别直接跟字符串'字符串'这类数据相加 别直接跟字符串'字符串'这类数据相加 unicode类型别直接跟字符串'字符串'这类数据相加 说四遍 3 .有些读取的方式偏偏是要读取str类型的路径,不是unicode类型的路径,那么我们把这个str.enco