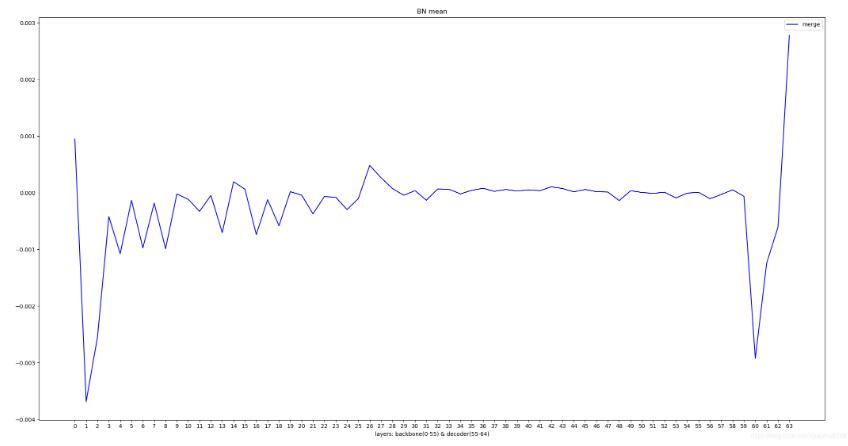
可视化pytorch 模型中不同BN层的running mean曲线实例
加载模型字典
逐一判断每一层,如果该层是bn 的 running mean,就取出参数并取平均作为该层的代表
对保存的每个BN层的数值进行曲线可视化
from functools import partial
import pickle
import torch
import matplotlib.pyplot as plt
pth_path = 'checkpoint.pth'
pickle.load = partial(pickle.load, encoding="latin1")
pickle.Unpickler = partial(pickle.Unpickler, encoding="latin1")
pretrained_dict = torch.load(pth_path, map_location=lambda storage, loc: storage, pickle_module=pickle)
pretrained_dict = pretrained_dict['state_dict']
means = []
for name, param in pretrained_dict.items():
print(name)
if 'running_mean' in name:
means.append(mean.numpy())
layers = [i for i in range(len(means))]
plt.plot(layers, means, color='blue')
plt.legend()
plt.xticks(layers)
plt.xlabel('layers')
plt.show()
补充知识:关于pytorch中BN层(具体实现)的一些小细节
最近在做目标检测,需要把训好的模型放到嵌入式设备上跑前向,因此得把各种层的实现都用C手撸一遍,,,此为背景。
其他层没什么好说的,但是BN层这有个小坑。pytorch在打印网络参数的时候,只打出weight和bias这两个参数。咦,说好的BN层有四个参数running_mean、running_var 、gamma 、beta的呢?一开始我以为是pytorch把BN层的计算简化成weight * X + bias,但马上反应过来应该没这么简单,因为pytorch中只有可学习的参数才称为parameter。上网找了一些资料但都没有说到这么细的,毕竟大部分用户使用时只要模型能跑起来就行了,,,于是开始看BN层有哪些属性,果然发现了熟悉的running_mean和running_var,原来pytorch的BN层实现并没有不同。这里吐个槽:为啥要把gamma和beta改叫weight、bias啊,很有迷惑性的好不好,,,
扯了这么多,干脆捋一遍pytorch里BN层的具体实现过程,帮自己理清思路,也可以给大家提供参考。再吐槽一下,在网上搜“pytorch bn层”出来的全是关于这一层怎么用的、初始化时要输入哪些参数,没找到一个pytorch中BN层是怎么实现的,,,
众所周知,BN层的输出Y与输入X之间的关系是:Y = (X - running_mean) / sqrt(running_var + eps) * gamma + beta,此不赘言。其中gamma、beta为可学习参数(在pytorch中分别改叫weight和bias),训练时通过反向传播更新;而running_mean、running_var则是在前向时先由X计算出mean和var,再由mean和var以动量momentum来更新running_mean和running_var。所以在训练阶段,running_mean和running_var在每次前向时更新一次;在测试阶段,则通过net.eval()固定该BN层的running_mean和running_var,此时这两个值即为训练阶段最后一次前向时确定的值,并在整个测试阶段保持不变。
以上这篇可视化pytorch 模型中不同BN层的running mean曲线实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
可视化pytorch 模型中不同BN层的running mean曲线实例
加载模型字典 逐一判断每一层,如果该层是bn 的 running mean,就取出参数并取平均作为该层的代表 对保存的每个BN层的数值进行曲线可视化 from functools import partial import pickle import torch import matplotlib.pyplot as plt pth_path = 'checkpoint.pth' pickle.load = partial(pickle.load, encoding="latin1")
-
浅谈pytorch中的BN层的注意事项
最近修改一个代码的时候,当使用网络进行推理的时候,发现每次更改测试集的batch size大小竟然会导致推理结果不同,甚至产生错误结果,后来发现在网络中定义了BN层,BN层在训练过程中,会将一个Batch的中的数据转变成正太分布,在推理过程中使用训练过程中的参数对数据进行处理,然而网络并不知道你是在训练还是测试阶段,因此,需要手动的加上,需要在测试和训练阶段使用如下函数. model.train() or model.eval() BN类的定义见pytorch中文参考文档 补充知识:关于pyto
-
Pytorch模型中的parameter与buffer用法
Parameter 和 buffer If you have parameters in your model, which should be saved and restored in the state_dict, but not trained by the optimizer, you should register them as buffers.Buffers won't be returned in model.parameters(), so that the optimize
-
pytorch中的model.eval()和BN层的使用
看代码吧~ class ConvNet(nn.module): def __init__(self, num_class=10): super(ConvNet, self).__init__() self.layer1 = nn.Sequential(nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2))
-
pytorch固定BN层参数的操作
背景: 基于PyTorch的模型,想固定主分支参数,只训练子分支,结果发现在不同epoch相同的测试数据经过主分支输出的结果不同. 原因: 未固定主分支BN层中的running_mean和running_var. 解决方法: 将需要固定的BN层状态设置为eval. 问题示例: 环境:torch:1.7.0 # -*- coding:utf-8 -*- import torch import torch.nn as nn import torch.nn.functional as F class
-
pytorch 模型可视化的例子
如下所示: 一. visualize.py from graphviz import Digraph import torch from torch.autograd import Variable def make_dot(var, params=None): """ Produces Graphviz representation of PyTorch autograd graph Blue nodes are the Variables that require gra
-
解决Keras 中加入lambda层无法正常载入模型问题
刚刚解决了这个问题,现在记录下来 问题描述 当使用lambda层加入自定义的函数后,训练没有bug,载入保存模型则显示Nonetype has no attribute 'get' 问题解决方法: 这个问题是由于缺少config信息导致的.lambda层在载入的时候需要一个函数,当使用自定义函数时,模型无法找到这个函数,也就构建不了. m = load_model(path,custom_objects={"reduce_mean":self.reduce_mean,"sli
-

pytorch模型保存与加载中的一些问题实战记录
目录 前言 一.torch中模型保存和加载的方式 1.模型参数和模型结构保存和加载 2.只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点 二.torch中模型保存和加载出现的问题 1.单卡模型下保存模型结构和参数后加载出现的问题 2.多卡机器单卡训练模型保存后在单卡机器上加载会报错 3.多卡训练模型保存模型结构和参数后加载出现的问题 三.正确的保存模型和加载的方法 总结 前言 最近使用pytorch训练模型,保存模型后再次加载使用出现了一些问题.记录一下解决方案! 一.torc
-
画pytorch模型图,以及参数计算的方法
刚入pytorch的坑,代码还没看太懂.之前用keras用习惯了,第一次使用pytorch还有些不适应,希望广大老司机多多指教. 首先说说,我们如何可视化模型.在keras中就一句话,keras.summary(),或者plot_model(),就可以把模型展现的淋漓尽致. 但是pytorch中好像没有这样一个api让我们直观的看到模型的样子.但是有网友提供了一段代码,可以把模型画出来,对我来说简直就是如有神助啊. 话不多说,上代码吧. import torch from torch.autog
-
pytorch 图像中的数据预处理和批标准化实例
目前数据预处理最常见的方法就是中心化和标准化. 中心化相当于修正数据的中心位置,实现方法非常简单,就是在每个特征维度上减去对应的均值,最后得到 0 均值的特征. 标准化也非常简单,在数据变成 0 均值之后,为了使得不同的特征维度有着相同的规模,可以除以标准差近似为一个标准正态分布,也可以依据最大值和最小值将其转化为 -1 ~ 1 之间 批标准化:BN 在数据预处理的时候,我们尽量输入特征不相关且满足一个标准的正态分布,这样模型的表现一般也较好.但是对于很深的网路结构,网路的非线性层会使得输出的结