python高级搜索实现高效搜索GitHub资源
目录
- 搜索资源
- 通过 in 关键字搜索
- 通过 stars、fork 数量搜索
- 按照范围查询
- 按创建、更新时间搜索
- 搜索代码
- 按文件内容、路径搜索
- 在某个资源下搜索
- 按语言搜索
- 总结
文 | 某某白米饭
来源:Python 技术「ID: pythonall」
在程序员眼中全球最大同性交友网站 GitHub 上的优秀开源框架和教程数量是世上当之无愧的第一,如何高效的在 GitHub 上搜索就成为了每一位程序员必会的技能之一
搜索资源
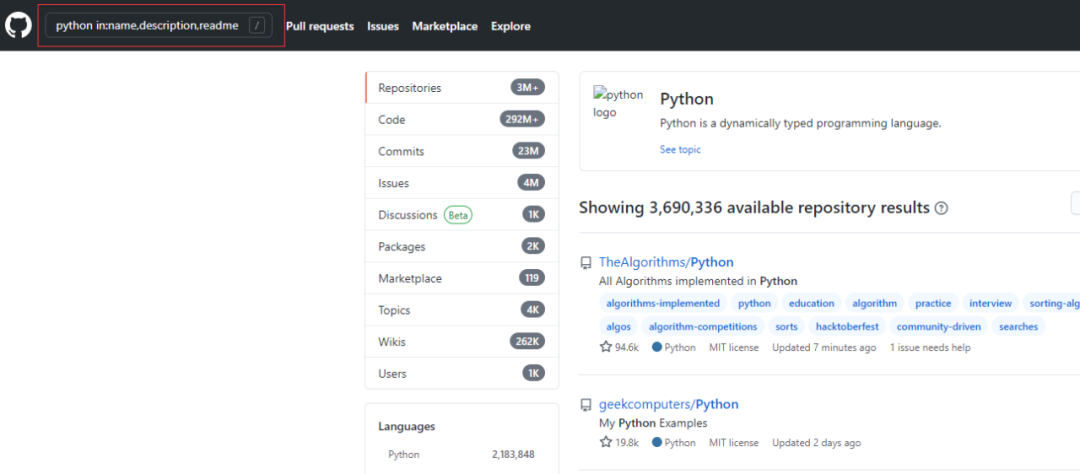
通过 in 关键字搜索
关键字 in 可以搜索出 GitHub 上的资源名称 name、说明 description 和 readme 文件中的内容
# 语法
关键字 in:
# 示例
python in:name,description,readme # 逗号分割表示或的意思
通过 stars、fork 数量搜索
搜索 GitHub 时用 star 数量和 fork 数量判断这个项目是否优秀的标准之一
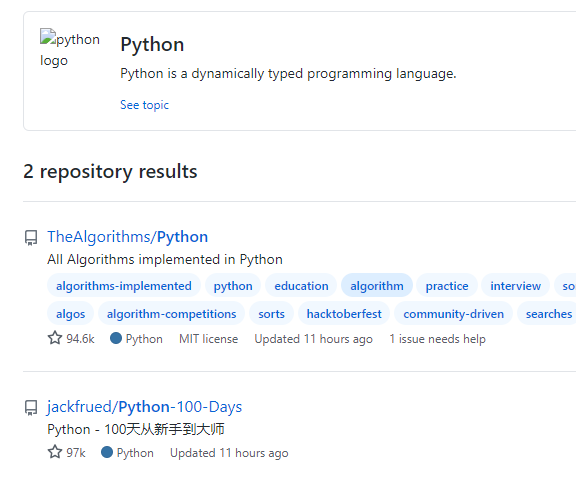
按照大于小于查询
# 语法
关键字 stars:>=数量 forks:>=数量
#示例
python in:name stars:>94000 forks:>2400
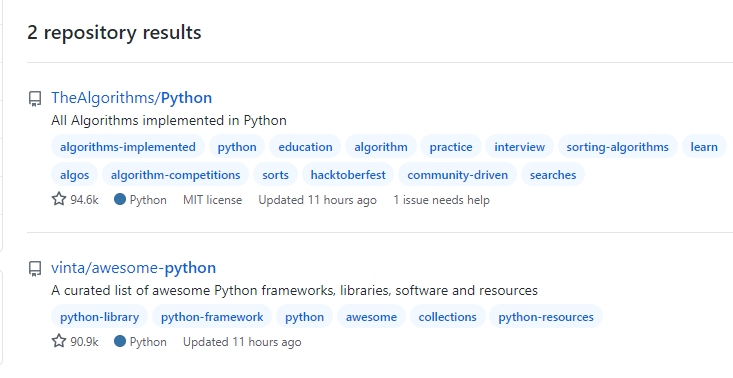
按照范围查询
star 数量和 fork 数量也可以按照一个范围取值搜索
#语法
关键字 stars:范围1..范围2
# 示例
python in:name stars:90000..95000
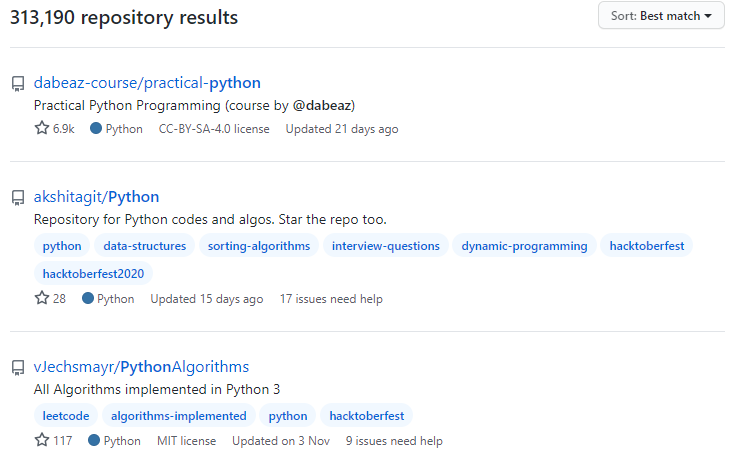
按创建、更新时间搜索
按创建、更新时间搜索可以把版本老旧的资源筛选出去
# 语法
# 创建时间
关键字 created:>=YYYY-MM-DD
# 更新时间
关键字 pushed:>=YYYY-MM-DD
# 示例
python in:name created:>=2020-01-01 pushed:>=2020-01-01
搜索代码
在 GitHub上搜索文件中的代码有一些限制
- 在需要搜索 fork 资源 时,只能搜索到 star 数量比父级资源多的 fork 资源,并需要加上 fork:true 查询
- 只有小于 384 KB 的文件可搜索
- 只有少于 500,000 个文件的仓库可搜索
- 除了 filename 搜索以外,搜索源代码时必须始终包括至少一个关键字
- 搜索结果最多可显示同一文件的两个分段,但文件内可能有更多结果
- 不能使用通配符
按文件内容、路径搜索
# 语法
# 文件内容
关键字 in:file
# 文件路径
关键字 in:path
# 示例
python in:file,path

在某个资源下搜索
# 语法
关键字 repo:资源
# 示例
python repo:JustDoPython/python-100-day
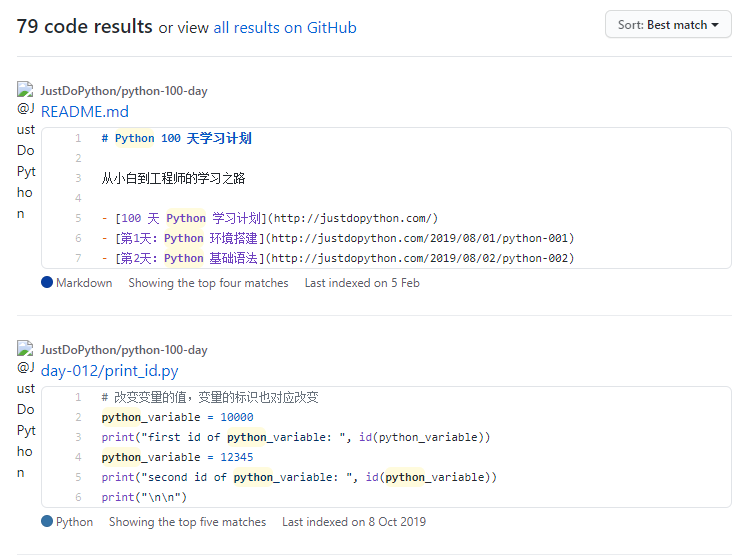
按语言搜索
# 语法 关键字 language:LANGUAGE # 示例 python language:javascript # 搜索 javascript 中的 python
按文件名、大小、扩展名搜索
# 语法 # 文件名 关键字 filename:FILENAME # 文件大小 关键字 size:>=大小 # 扩展名 关键字 extension:EXTENSION # 示例 python filename:aaa size:>10 extension:py

总结
在 GitHub 上高效搜索资源,您学废了吗?JustDoPython 项目也是一个优秀的开源代码,希望大家多多 star
参考
https://docs.github.com/cn/free-pro-team@latest/github
以上就是python高级搜索实现高效搜索GitHub资源的详细内容,更多关于python高效搜索GitHub资源的资料请关注我们其它相关文章!
相关推荐
-
使用Python快乐学数学Github万星神器Manim简介
高考在即,笔者想为孩子以后能够快乐学习数学.学习编程找到一个比较合适的项目,经过一番比较发现github上的万星项目manim(https://github.com/3b1b/manim)就非常好.它能够快速构建有关数学的动画,而且非常精确形象. 安装Manim 虽然manim已经支持Python3.7的,不过安装起来还是比较麻烦,我在ubantu18.04上直接使用安装的过程如下: 1.首先尝试直接使用pip install manimlib命令安装,但是会有以下报错 Cannot unin
-
python使用心得之获得github代码库列表
1.背景 项目需求,要求获得github的repo的api,以便可以提取repo的数据进行分析.研究了一天,终于解决了这个问题,虽然效率还是比较低下. 因为github的那个显示repo的api,列出了每个repo的详细信息,而且是json格式的.现在貌似还没有找到可以分析多个json格式数据的方法,所以用的是比较蠢得splite加re的方法.如果大家有更好的方法,不发留言讨论! 2.代码 import re import os def GetUrl(num): str = os.popen("
-
Python3以GitHub为例来实现模拟登录和爬取的实例讲解
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护. 1. 本节目标 本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态.个人信息等内容. 我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个 Repository,创建了哪个组织,推送了哪些代码.但是退出登录之后,我们就无法再看到这些信息. 如果希望爬取 GitH
-
使用 Python 玩转 GitHub 的贡献板(推荐)
细心的人都会发现GitHub个人主页有一个记录每天贡献次数的面板,我暂且称之为贡献面板.就像下图那个样子.只要当天在GitHub有提交记录,对应的小格子就会变成绿色,当天提交次数越多,颜色也会越深.因此我就有了一个大胆的想法.细心的你应该也发现了,我就是要讲如何搞出这个小:heart::heart:来.项目地址:https://github.com/YES-Lee/git_painter 原理 基本原理前面已经讲过,我们只需要控制项目提交的日期和次数,就能在贡献面板中填充出花样来.可能有朋友会问
-
在Pycharm中使用GitHub的方法步骤
Pycharm是当前进行python开发,尤其是Django开发最好的IDE.GitHub是程序员的圣地,几乎人人都在用. 本文假设你对pycharm和github都有一定的了解,并且希望在pycharm下直接使用github的版本控制功能. 废话不多说,下面图文详解,全是干货. 环境:pycharm 2016,git 2.8,github账户,windows7 一.配置Pycharm 不管你用哪种方法,进入pycharm的配置菜单. 选择上图中的version control.(这里插一句,不
-

python高级搜索实现高效搜索GitHub资源
目录 搜索资源 通过 in 关键字搜索 通过 stars.fork 数量搜索 按照范围查询 按创建.更新时间搜索 搜索代码 按文件内容.路径搜索 在某个资源下搜索 按语言搜索 总结 文 | 某某白米饭 来源:Python 技术「ID: pythonall」 在程序员眼中全球最大同性交友网站 GitHub 上的优秀开源框架和教程数量是世上当之无愧的第一,如何高效的在 GitHub 上搜索就成为了每一位程序员必会的技能之一 搜索资源 通过 in 关键字搜索 关键字 in 可以搜索出 GitHub 上
-
Python基于爬虫实现全网搜索并下载音乐
现在写一篇博客总是喜欢先谈需求或者本内容的应用场景,是的,如果写出来的东西没有任何应用价值,确实也没有实际意义.今天的最早的需求是来自于如何免费[白嫖]下载全网优质音乐,我去b站上面搜索到了一个大牛做过的一个歌曲搜素神器,界面是这样的: 确实很好用的,而且涵盖了互联网上面大多数主流的音乐网站,涉及到的版本也很多,可谓大而全,但是一个技术人的追求远远不会如此,于是我就想去了解其中背后的原理,因为做过网络爬虫的人都知道,爬虫只能爬取某一页或者某些页的网站资源,所以我很好奇它背后是怎么实现的? 笔者一
-
Python实现提取谷歌音乐搜索结果的方法
本文实例讲述了Python实现提取谷歌音乐搜索结果的方法.分享给大家供大家参考.具体如下: Python的简单脚本,用于提取谷歌音乐搜索页面中的歌曲信息,包括歌曲名,作者,专辑名,现在链接等,最多只提取10页结果. #! /usr/bin/env python #coding=utf-8 ''' Created on 2011-8-19 @author: yaoboyuan ''' from urllib import request,parse import re,sys def extrac
-
python仿evething的文件搜索器实例代码
今天看到everything搜索速度秒杀windows自带的文件管理器,所以特地模仿everything实现了文件搜索以及打开对应文件的功能,首先来一张搜索对比图. 这是evething搜索效果: 这是自己实现的效果: 主要功能就是python的os库的文件列表功能,sqllite创建表,插入数据以及模糊搜索,然后就是tkiner实现的界面功能.全部代码贴出来做一次记录,花费一天时间踩坑. # coding=utf-8 import tkinter as tk import tkinter.me
-
Python模拟百度自动输入搜索功能的实例
如下所示: # 访问百度,模拟自动输入搜索 # 代码中引入selenium版本为:3.4.3 # 通过Chrom浏览器访问发起请求 # Chrom版本:59 ,chromdriver:2.3 # 需要对应版本的Chrom和chromdriver # 请联系QQ:878799579 from selenium import webdriver # 引入Keys类包 发起键盘操作 from selenium.webdriver.common.keys import Keys import time
-
Python实现的本地文件搜索功能示例【测试可用】
本文实例讲述了Python实现的本地文件搜索功能.分享给大家供大家参考,具体如下: 偶尔需要搜索指定文件,不想每次都在windows下面去搜索,想用代码来实现搜索,而且能够收集搜索结果,于是有了下面的代码. # -*- coding:utf-8 -*- #! python2 import os def search_file(fileNmae, path): '''search a file in target directory :param fileNmae: file to be sear
-
OpenCV python sklearn随机超参数搜索的实现
本文介绍了OpenCV python sklearn随机超参数搜索的实现,分享给大家,具体如下: """ 房价预测数据集 使用sklearn执行超参数搜索 """ import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os import sys import tens
-
Python爬虫爬取百度搜索内容代码实例
这篇文章主要介绍了Python爬虫爬取百度搜索内容代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 搜索引擎用的很频繁,现在利用Python爬虫提取百度搜索内容,同时再进一步提取内容分析就可以简便搜索过程.详细案例如下: 代码如下 # coding=utf8 import urllib2 import string import urllib import re import random #设置多个user_agents,防止百度限制I
-
Python通过tkinter实现百度搜索的示例代码
本文主要介绍了Python通过tkinter实现百度搜索的示例代码,分享给大家,具体如下: """ 百度搜索可视化 """ import tkinter import win32api from selenium.webdriver import Chrome entry = None def callback(): global entry keywords = entry.get() if not keywords: win32api.Mes
-
Python学习之MRO方法搜索顺序
目录 为什么会讲 MRO? 什么是 MRO 注意 MRO 算法 什么是旧式类,新式类 想深入了解 C3 算法的可以看看官网 旧式类 MRO 算法 新式类 MRO 算法 新式 MRO 算法的问题 什么是单调性原则? C3 MRO 算法 简单了解下 C3 算法 merge 的运算方式 简单类 MRO 的计算栗子 单继承MRO 的计算栗子 多继承MRO 的计算栗子 多继承MRO 的计算栗子二 为什么会讲 MRO? 在讲多继承的时候,有讲到, 当继承的多个父类拥有同名属性.方法,子类对象调用该属性.方法