TensorFlow2.X使用图片制作简单的数据集训练模型
Tensorflow内置了许多数据集,但是实际自己应用的时候还是需要使用自己的数据集,这里TensorFlow 官网也给介绍文档,官方文档。这里对整个流程做一个总结(以手势识别的数据集为例)。
1、 收集手势图片
数据集下载
方法多种多样了。我通过摄像头自己采集了一些手势图片。保存成如下形式,
以同样的形式在建立一个测试集,当然也可以不弄,在程序里处理。
2、构建数据集
导入相关的包
import tensorflow as tf from tensorflow import keras from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2 import os import pathlib import random import matplotlib.pyplot as plt
读取文件
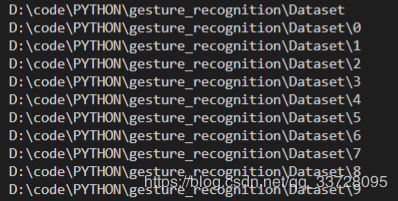
data_root = pathlib.Path('D:\code\PYTHON\gesture_recognition\Dataset')
print(data_root)
for item in data_root.iterdir():
print(item)
读取图片路径到list中
all_image_paths = list(data_root.glob('*/*'))
all_image_paths = [str(path) for path in all_image_paths]
random.shuffle(all_image_paths)
image_count = len(all_image_paths)
print(image_count) ##统计共有多少图片
for i in range(10):
print(all_image_paths[i])

label_names = sorted(item.name for item in data_root.glob('*/') if item.is_dir())
print(label_names) #其实就是文件夹的名字
label_to_index = dict((name, index) for index, name in enumerate(label_names))
print(label_to_index)
all_image_labels = [label_to_index[pathlib.Path(path).parent.name]
for path in all_image_paths]
print("First 10 labels indices: ", all_image_labels[:10])

预处理
def preprocess_image(image): image = tf.image.decode_jpeg(image, channels=3) image = tf.image.resize(image, [100, 100]) image /= 255.0 # normalize to [0,1] range # image = tf.reshape(image,[100*100*3]) return image def load_and_preprocess_image(path,label): image = tf.io.read_file(path) return preprocess_image(image),label
构建一个 tf.data.Dataset
ds = tf.data.Dataset.from_tensor_slices((all_image_paths, all_image_labels)) train_data = ds.map(load_and_preprocess_image).batch(16)
同样的方式在制作一个测试集,就可以用于模型训练和测试了。
总结
到此这篇关于TensorFlow2.X使用图片制作简单的数据集训练模型的文章就介绍到这了,更多相关TensorFlow数据集训练模型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解如何从TensorFlow的mnist数据集导出手写体数字图片
在TensorFlow的官方入门课程中,多次用到mnist数据集. mnist数据集是一个数字手写体图片库,但它的存储格式并非常见的图片格式,所有的图片都集中保存在四个扩展名为idx3-ubyte的二进制文件. 如果我们想要知道大名鼎鼎的mnist手写体数字都长什么样子,就需要从mnist数据集中导出手写体数字图片.了解这些手写体的总体形状,也有助于加深我们对TensorFlow入门课程的理解. 下面先给出通过TensorFlow api接口导出mnist手写体数字图片的python代码,再对代
-

详解tensorflow训练自己的数据集实现CNN图像分类
利用卷积神经网络训练图像数据分为以下几个步骤 1.读取图片文件 2.产生用于训练的批次 3.定义训练的模型(包括初始化参数,卷积.池化层等参数.网络) 4.训练 1 读取图片文件 def get_files(filename): class_train = [] label_train = [] for train_class in os.listdir(filename): for pic in os.listdir(filename+train_class): class_train.app
-
tensorflow实现加载mnist数据集
mnist作为最基础的图片数据集,在以后的cnn,rnn任务中都会用到 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data #数据集存放地址,采用0-1编码 mnist = input_data.read_data_sets('F:/mnist/data/',one_hot = Tr
-
TensorFlow车牌识别完整版代码(含车牌数据集)
在之前发布的一篇博文<MNIST数据集实现车牌识别--初步演示版>中,我们演示了如何使用TensorFlow进行车牌识别,但是,当时采用的数据集是MNIST数字手写体,只能分类0-9共10个数字,无法分类省份简称和字母,局限性较大,无实际意义. 经过图像定位分割处理,博主收集了相关省份简称和26个字母的图片数据集,结合前述博文中贴出的python+TensorFlow代码,实现了完整的车牌识别功能.本着分享精神,在此送上全部代码和车牌数据集. 车牌数据集下载地址(约4000张图片):tf_ca
-
Tensorflow 训练自己的数据集将数据直接导入到内存
制作自己的训练集 下图是我们数据的存放格式,在data目录下有验证集与测试集分别对应iris_test, iris_train 为了向伟大的MNIST致敬,我们采用的数据名称格式和MNIST类似 classification_index.jpg 图像的index都是5的整数倍是因为我们选择测试集的原则是每5个样本,选择一个样本作为测试集,其余的作为训练集和验证集 生成这样数据的过程相对简单,如果有需要python代码的,可以给我发邮件,或者在我的github下载 至此,我们的训练集,测试集,验证
-
Tensorflow之构建自己的图片数据集TFrecords的方法
学习谷歌的深度学习终于有点眉目了,给大家分享我的Tensorflow学习历程. tensorflow的官方中文文档比较生涩,数据集一直采用的MNIST二进制数据集.并没有过多讲述怎么构建自己的图片数据集tfrecords. 流程是:制作数据集-读取数据集--加入队列 先贴完整的代码: #encoding=utf-8 import os import tensorflow as tf from PIL import Image cwd = os.getcwd() classes = {'test'
-
TensorFlow2.X使用图片制作简单的数据集训练模型
Tensorflow内置了许多数据集,但是实际自己应用的时候还是需要使用自己的数据集,这里TensorFlow 官网也给介绍文档,官方文档.这里对整个流程做一个总结(以手势识别的数据集为例). 1. 收集手势图片 数据集下载 方法多种多样了.我通过摄像头自己采集了一些手势图片.保存成如下形式, 以同样的形式在建立一个测试集,当然也可以不弄,在程序里处理. 2.构建数据集 导入相关的包 import tensorflow as tf from tensorflow import keras fro
-
Python线性分类介绍
通过约束类的协方差相等,将贝叶斯分类器简化为线性分类器.比较生成模型和判别模型在挑战性分类任务中的性能. 在本实验课中:我们将比较线性分类的“生成建模”和“判别建模”方法.对于“生成”方法,我们将重新讨论我们在前面练习中使用的贝叶斯分类代码,但我们将限制系统具有相等的协方差矩阵,即一个协方差矩阵来表示所有类别,而不是每个类别都有其自己的协方差矩阵.在这种情况下,系统成为线性分类器.我们将把它与“判别式”方法进行比较,在这种方法中,我们使用感知器学习算法直接学习线性分类器参数. 在本笔记本中,我们
-
tensorflow saver 保存和恢复指定 tensor的实例讲解
在实践中经常会遇到这样的情况: 1.用简单的模型预训练参数 2.把预训练的参数导入复杂的模型后训练复杂的模型 这时就产生一个问题: 如何加载预训练的参数. 下面就是我的总结. 为了方便说明,做一个假设:简单的模型只有一个卷基层,复杂模型有两个. 卷积层的实现代码如下: import tensorflow as tf # PS:本篇的重担是saver,不过为了方便阅读还是说明下参数 # 参数 # name:创建卷基层的代码这么多,必须要函数化,而为了防止变量冲突就需要用tf.name_scope
-
Python文本特征抽取与向量化算法学习
本文为大家分享了Python文本特征抽取与向量化的具体代码,供大家参考,具体内容如下 假设我们刚看完诺兰的大片<星际穿越>,设想如何让机器来自动分析各位观众对电影的评价到底是"赞"(positive)还是"踩"(negative)呢? 这类问题就属于情感分析问题.这类问题处理的第一步,就是将文本转换为特征. 因此,这章我们只学习第一步,如何从文本中抽取特征,并将其向量化. 由于中文的处理涉及到分词问题,本文用一个简单的例子来说明如何使用Python的机器
-
利用Python进行数据可视化常见的9种方法!超实用!
前言 如同艺术家们用绘画让人们更贴切的感知世界,数据可视化也能让人们更直观的传递数据所要表达的信息. 我们今天就分享一下如何用 Python 简单便捷的完成数据可视化. 其实利用 Python 可视化数据并不是很麻烦,因为 Python 中有两个专用于可视化的库 matplotlib 和 seaborn 能让我们很容易的完成任务. Matplotlib:基于Python的绘图库,提供完全的 2D 支持和部分 3D 图像支持.在跨平台和互动式环境中生成高质量数据时,matplotlib 会很有帮助
-
pytorch神经网络从零开始实现多层感知机
目录 初始化模型参数 激活函数 模型 损失函数 训练 我们已经在数学上描述了多层感知机,现在让我们尝试自己实现一个多层感知机.为了与我们之前使用softmax回归获得的结果进行比较,我们将继续使用Fashion-MNIST图像分类数据集. import torch from torch import nn from d2l import torch as d2l batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnis
-
python学习与数据挖掘应知应会的十大终端命令
目录 1.wget 2.head 3.tail 4.wc 5.grep 6.cat 7.find 8.sort 9.nano 10.Variables IT界的每个人都应该知道终端(Terminal)的基本知识,数据科学家也不例外.有时,终端是你的全部,尤其是在将模型和数据管道部署到远程机器时. 让我们开始吧! 1.wget wget实用程序用于从远程服务器下载文件.你可以用它来下载数据集,只要你知道网址,可以使用wget命令下载它,我以如下url为例: https://raw.githubus
-
Python数据预处理常用的5个技巧
目录 前言 数据集 示例 1 示例 2 示例 3 示例 4 示例 5 总结 前言 我们知道数据是一项宝贵的资产,近年来经历了指数级增长.但是原始数据通常不能立即使用,它需要进行大量清理和转换. Pandas 是 Python 的数据分析和操作库,它有多种清理数据的方法和函数.在本文中,我将做5个示例来帮助大家掌握数据清理技能. 数据集 这是一个包含脏数据的示例数据框 让我们看看可以做些什么来使这个数据集变得干净. 第一列是多余的,应该删除: Date 没有标准: Name 写成姓氏.名字,并有大
-
MySQL 开窗函数
目录 (1)开窗函数的定义 (2)开窗函数的实际应用场景 结合order by关键词和limit关键词是可以解决很多的topN问题,比如从二手房数据集中查询出某个地区的最贵的10套房,从电商交易数据集中查询出实付金额最高的5笔交易,从学员信息表中查询出年龄最小的3个学员等.但是,如果需求变成从二手房数据集中查询出各个地区最贵的10套房,从电商数据集中查询出每月实付金额最高的5笔交易,从学员信息表中查询出各个科系下年龄最小的3个学员,该如何解决呢? 其实这类问题的核心就是,筛选出组内的topN,而
-
在 Python 中进行 One-Hot 编码
目录 1.介绍 2.什么是One-Hot编码? 3.实现-Pandas 4.实现-Scikit-Learn 5.One-hot编码在机器学习领域的应用 1.介绍 在计算机科学中,数据可以用很多不同的方式表示,自然而然地,每一种方式在某些领域都有其优点和缺点. 由于计算机无法处理分类数据,因为这些类别对它们没有意义,如果我们希望计算机能够处理这些信息,就必须准备好这些信息. 此操作称为预处理. 预处理的很大一部分是编码 - 以计算机可以理解的方式表示每条数据(该