Pandas统计计数value_counts()的使用
value_counts()方法返回一个序列Series,该序列包含每个值的数量(对于数据框中的任何列,value_counts()方法会返回该列每个项的计数)
value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列进行使用
语法
value_counts(values,
sort=True,
ascending=False,
normalize=False,
bins=None,
dropna=True)
参数说明
- sort: 是否要进行排序(默认进行排序,取值为True)
- ascending: 默认降序排序(取值为False),升序排序取值为True
- normalize: 是否要对计算结果进行标准化,并且显示标准化后的结果,默认是False
- bins: 可以自定义分组区间,默认是否
- dropna: 是否包括对NaN进行计数,默认不包括
import pandas as pd
import numpy as np
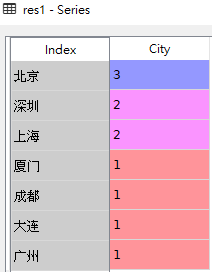
df = pd.DataFrame({'City': ['北京', '广州', '深圳', '上海', '大连', '成都', '深圳', '厦门', '北京', '北京', '上海', '珠海'],
'Revenue': [10000, 10000, 5000, 5000, 40000, 50000, 8000, 5000, 5000, 5000, 10000, 12000],
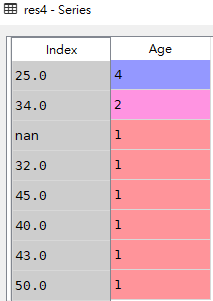
'Age': [50, 43, 34, 40, 25, 25, 45, 32, 25, 25, 34, np.nan]})
# 1.查看'City'这一列的计数结果(对给定列里面的每个值进行计数并进行降序排序,缺失值nan也会被排除)
# value_counts()并不是未带任何参数,而是所有参数都是默认的
res1 = df['City'].value_counts()
# 2.查看'Revenue'这一列的计数结果(采用升序的方式)
res2 = df['Revenue'].value_counts(ascending=True)
# 3.查看'Age'这一列的计数占比(使用标准化normalize=True)
res3 = df['Age'].value_counts(ascending=True,normalize=True)
# 4.查看'Age'这一列的计数结果(展示NaN值的计数)
res4 = df['Age'].value_counts(dropna=False)
# 5.查看'Age'这一列的计数结果(不展示NaN值的计数)
# res5 = df['Age'].value_counts()
res5 = df['Age'].value_counts(dropna=True)
df

res1
res2

res3
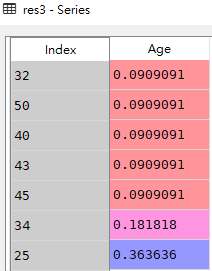
res4
res5

到此这篇关于Pandas统计计数value_counts()的使用的文章就介绍到这了,更多相关Pandas统计计数value_counts()内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas计数 value_counts()的使用
在pandas里面常用value_counts确认数据出现的频率. 1. Series 情况下: pandas 的 value_counts() 函数可以对Series里面的每个值进行计数并且排序. import pandas as pd df = pd.DataFrame({'区域' : ['西安', '太原', '西安', '太原', '郑州', '太原'], '10月份销售' : ['0.477468', '0.195046', '0.015964', '0.259654', '0.856
-

Pandas统计计数value_counts()的使用
value_counts()方法返回一个序列Series,该序列包含每个值的数量(对于数据框中的任何列,value_counts()方法会返回该列每个项的计数) value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列进行使用 语法 value_counts(values, sort=True, ascending=False, normalize=False, bins=None, dropna=True) 参数说明 sort: 是否要进行排序(
-
浅谈python中统计计数的几种方法和Counter详解
1) 使用字典dict() 循环遍历出一个可迭代对象中的元素,如果字典没有该元素,那么就让该元素作为字典的键,并将该键赋值为1,如果存在就将该元素对应的值加1. lists = ['a','a','b',5,6,7,5] count_dict = dict() for item in lists: if item in count_dict: count_dict[item] += 1 else: count_dict[item] = 1 2) 使用defaultdict() defaultdi
-
Pandas统计重复的列里面的值方法
pandas 代码如下: import pandas as pd import numpy as np salaries = pd.DataFrame({ 'name': ['BOSS', 'Lilei', 'Lilei', 'Han', 'BOSS', 'BOSS', 'Han', 'BOSS'], 'Year': [2016, 2016, 2016, 2016, 2017, 2017, 2017, 2017], 'Salary': [1, 2, 3, 4, 5, 6, 7, 8], 'Bon
-
pandas统计重复值次数的方法实现
本文主要介绍了pandas统计重复值次数的方法实现,分享给大家,具体如下: from pandas import DataFrame df = DataFrame({'key1':['a','a','b','b','a','a'], 'key2':['one','two','one','two','one','one'], 'data1':[1,2,3,2,1,1], # 'data2':np.random.randn(5) }) # 打印数据框 print(df) # data1 key1 k
-
Python实战基础之Pandas统计某个数据列的空值个数
目录 一.实战场景 二.主要知识点 三.菜鸟实战 1.创建 python 文件 2.运行结果 补充:Pandas检查是否有空值.处理空值 总结 一.实战场景 实战场景:Pandas 如何统计某个数据列的空值个数 二.主要知识点 文件读写 基础语法 Pandas numpy 三.菜鸟实战 马上安排! 1.创建 python 文件 """ 对如下DF,设置两个单元格的值 ·使用iloc 设置(3,B)的值是nan ·使用loc设置(8,D)的值是nan ""&
-
利用pandas进行大文件计数处理的方法
Pandas读取大文件 要处理的是由探测器读出的脉冲信号,一组数据为两列,一列为时间,一列为脉冲能量,数据量在千万级,为了有一个直接的认识,先使用Pandas读取一些 import pandas as pd data = pd.read_table('filename.txt', iterator=True) chunk = data.get_chunk(5) 而输出是这样的: Out[4]: 332.977889999979 -0.0164794921875 0 332.97790 -0.02
-
Pandas按周/月/年统计数据介绍
Pandas 按周.月.年.统计数据 介绍 将日期转为时间格式 并设置为索引 import pandas as pd data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额']) print(data) data['订单创建时间']=pd.to_datetime(data['订单创建时间']) data=data.set_index('订单创建时间') print(data) 按周.月.季度.年统计数据 import pandas a
-
Pandas 模糊查询与替换的操作
主要用到的工具:Pandas .fuzzywuzzy Pandas:是基于numpy的一种工具,专门为分析大量数据而生,它包含大量的处理数据的函数和方法, 以下为pandas中文API: 缩写和包导入 在这个速查手册中,我们使用如下缩写: df:任意的Pandas DataFrame对象 s:任意的Pandas Series对象 同时我们需要做如下的引入: import pandas as pd import numpy as np 导入数据 pd.read_csv(filename):从CSV
-
python数据处理67个pandas函数总结看完就用
目录 导⼊数据 导出数据 查看数据 数据选取 数据处理 数据分组.排序.透视 数据合并 不管是业务数据分析 ,还是数据建模.数据处理都是及其重要的一个步骤,它对于最终的结果来说,至关重要. 今天,就为大家总结一下 "Pandas数据处理" 几个方面重要的知识,拿来即用,随查随查. 导⼊数据 导出数据 查看数据 数据选取 数据处理 数据分组和排序 数据合并 # 在使用之前,需要导入pandas库 import pandas as pd 导⼊数据 这里我为大家总结7个常见用法. pd.Da