C/C++实现快速排序算法的两种方式实例
目录
- 介绍
- 流程如下
- 实现
- 方式一
- 方式二
- 总结
介绍
快速排序是对冒泡排序算法的一种改进,快速排序算法通过多次比较和交换来实现排序。
流程如下

(图片来自百度)
实现
以下有两种实现方式,说是两种,其实就是在交换元素时具体细节上有点不同罢了。
方式一
int Partition(int A[],int low,int high){
int pivot=A[low];//第一个元素作为基准
while(low<high){
while(low<high && A[high]>=pivot) high--;
A[low]=A[high];
while(low<high && A[low]<=pivot) low++;
A[high]=A[low];
}
A[low]=pivot;
return low;
}
void QuickSort(int A[],int low,int high){
if(low<high){
int pivotpos=Partition(A,low,high);
QuickSort(A,low,pivotpos-1);
QuickSort(A,pivotpos+1,high);
}
}
该方式,先把基准元素保存起来
如下图数组,把49看作基准元素,先移动high指针,当指向27时退出while循环,把27放到low位置


这时候,high位置就空出来一个,那么让low移动,移动到下图所示时,65>49,退出while循环,再将65放到high位置
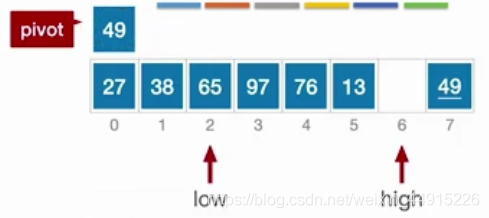
这样low这个位置又空出来了,再移动high,如此反复。

最后得到如下图的情况:

这样我们就按照“49”,把数组分为了左右两部分。
对左右两部分分别进行上述操作即可。

方式二
void Quick_sort(int left,int right,int arr[]){
if(left>=right)return;
int i,j,base,temp;
i=left,j=right;
base=arr[left];
while(i<j){
while(arr[j]>=base && i<j)j--;
while(arr[i]<=base && i<j)i++;
if(i<j){
temp=arr[i];
arr[i]=arr[j];
arr[j]=temp;
}
}
arr[left]=arr[i];
arr[i]=base;
Quick_sort(left,i-1,arr);
Quick_sort(i+1,right,arr);
}
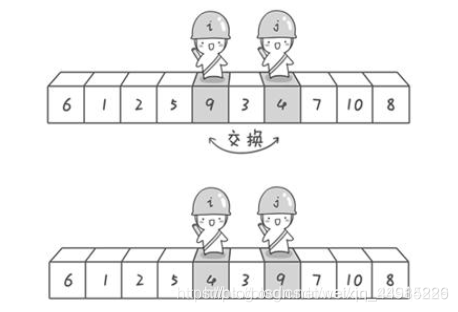
对于第二种方式,看下图即可很好理解。
高低指针不是轮流替换空余位置,而是同时找到不符合的元素,然后交换二者。
最后,高低指针相遇,再把基准元素与相遇位置上的元素交换即可。
(以下图片来自网络,侵删)



总结
到此这篇关于C/C++实现快速排序的两种方式的文章就介绍到这了,更多相关C/C++实现快速排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

c++快速排序详解
说一说快速排序 快速排序,实际中最常用的一种排序算法,速度快,效率高,在N*logN的同等级算法中效率名列前茅.· 基本思想:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分所有数据要小,然后再按此方法对这两部分数据分别进行快速排序.整个排序过程可以递归进行,以此达到整个数据变成有序序列. 将数列变成上述形式,这一步很关键,做好这一步,才能对主元左右的部分进行递归调用.以下是实现这一部分的代码: int partition_sort(int arr[],int l
-
C++快速排序的分析与优化详解
相信学过数据结构与算法的朋友对于快速排序应该并不陌生,本文就以实例讲述了C++快速排序的分析与优化,对于C++算法的设计有很好的借鉴价值.具体分析如下: 一.快速排序的介绍 快速排序是一种排序算法,对包含n个数的输入数组,最坏的情况运行时间为Θ(n2)[Θ 读作theta].虽然这个最坏情况的运行时间比较差,但快速排序通常是用于排序的最佳的实用选择.这是因为其平均情况下的性能相当好:期望的运行时间为 Θ(nlgn),且Θ(nlgn)记号中隐含的常数因子很小.另外,它还能够进行就地排序,在虚拟内存
-
C++归并法+快速排序实现链表排序的方法
本文主要介绍了C++归并法+快速排序实现链表排序的方法,分享给大家,具体如下: 我们可以试用归并排序解决: 对链表归并排序的过程如下. 找到链表的中点,以中点为分界,将链表拆分成两个子链表.寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2 步,慢指针每次移动 1步,当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点. 对两个子链表分别排序. 将两个排序后的子链表合并,得到完整的排序后的链表 上述过程可以通过递归实现.递归的终止条件是链表的节点个数小于或等于 1,即当链表为空或者链
-
c++ 快速排序算法【过程图解】
第一.算法描述 快速排序由C. A. R. Hoare在1962年提出,该算法是目前实践中使用最频繁,实用高效的最好排序算法, 快速排序算法是采用分治思想的算法,算法分三个步骤 1.从数组中抽出一个元素作为基数v(我们称之为划界元素),一般是取第一个.最后一个元素或中间的元素 2.将剩余的元素中小于v的移动到v的左边,将大于v元素移动到v的右边 3.对左右两个分区重复以上步骤直到所有元素都是有排序好. 第二.算法实现 /*序列划分函数*/ int partition(int a[], int p
-
C/C++实现双路快速排序算法原理
看了刘宇波的视频,讲双路快速排序的,原理讲的很直观,程序讲解也一看就懂.这里写一下自己的理解过程,也加深一下自己的理解. 首先说一下为什么需要双路排序,在有些带有许多重复数据的数组里,使用随机快速排序或者最简单的快速排序算法时,由于重复的数据会放在原来的索引位置不动,就回导致划分数组时划分的某一部分太长,起不到分段排序的效果,这样就导致算法退化成O(n^2)的复杂度.就像下图: 为了解决这个问题,双路快速排序采用的方法是对等于v的数也进行交换,原理如下所述: 首先选择一个数作为标志,放在数组的最
-
c++实现对输入数组进行快速排序的示例(推荐)
废话不多说,直接上代码 #include "stdafx.h" #include <iostream> #include <string> #include <vector> using namespace std; void quickSort(vector<int> &a, int, int); void swap(int &a, int&b); vector<string> split(strin
-
C++实现快速排序(Quicksort)算法
本文实例为大家分享了C++快速排序算法,供大家参考,具体内容如下 一.基本思想是: 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 二.方法1实现程序:左右两个方向扫描 // 快速排序:选第一个对象作为基准,按照该对象的排序码大小,将整个对象 // 序列划分为左右两个字序列: // 左侧子序列中所有对象的排序码都小于或等于基准对象的排序码: /
-
C/C++实现快速排序算法的思路及原理解析
快速排序 1. 算法思想 快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序. 2. 实现原理 2.1.设置两个变量 low.high,排序开始时:low=0,high=size-1. 2.2.整个数组找基准正确位置,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面 默认数组的第一个数为基准数据,赋值给key,即key=array[low]. 因为默认数组的第一个
-
C/C++实现三路快速排序算法原理
书接上文,上次讲到了双路快速排序,双路快速排序是将等于v(标志数)的数也进行交换,从而避免了在处理有大量重复数据的数组分组时的不平衡.而三路快速排序则是将等于v的数也分成一组,同样可以解决上述问题.其原理如下: 1.采用随机排序的方法将某个数作为分割数,放在数组开头,该数定义为v.将小于v的一段数组开头的数索引定义为lt,将需要遍历的数组的索引定义为i,将小于v的一段数组的索引定义为gt,数组的开头和结尾的索引分别为l和r.原理图如下: 2.对索引i进行维护,逐个比较索引i对应的数与v的关系.如
-
C/C++实现快速排序的方法
快速排序不会直接得到最终结果,只会把比k大和比k小的数分到k的两边.(你可以想象一下i和j是两个机器人,数据就是大小不一的石头,先取走i前面的石头留出回旋的空间,然后他们轮流分别挑选比k大和比k小的石头扔给对面,最后在他们中间把取走的那块石头放回去,于是比这块石头大的全扔给了j那一边,小的全扔给了i那一边.只是这次运气好,扔完一次刚好排整齐.)为了得到最后结果,需要再次对下标2两边的数组分别执行此步骤,然后再分解数组,直到数组不能再分解为止(只有一个数据),才能得到正确结果. -- 取自百度百科