Go逃逸分析示例详解
目录
- 引言大纲
- 逃逸分析
- 内存管理
- 栈
- 堆
- 堆和栈的对比
- 加锁
- 性能
- 缓存策略
- 逃逸分析优势
- 逃逸分析原则
- 逃逸分析举例
- 1.参数是interface类型
- 2. 变量在函数外部有引用
- 3. 变量内存占用较大
- 4. 变量大小不确定时
- 思考题
- 总结
引言大纲
这个月我会整理分享一系列后端工程师求职面试相关的文章,知识脉络图如下:
- JAVA/GO/PHP 面试常问的知识点
- DB:MySql PgSql
- Cache: Redis MemCache MongoDB
- 数据结构
- 算法
- 微服务&高并发
- 流媒体
- WEB3.0
- 源码分析
通过这一系列的文章,大家不仅能复习梳理后端开发相关的知识点,也可以了解目前的市场环境对服务端开发,尤其是对Go开发工程师的岗位要求,需要掌握哪些核心技术。
上一篇文章: 【狂刷面试题】GO常见面试题汇总我们介绍了:切片相关的知识点;深拷贝和浅拷贝的区别;new和make的区别;map的底层实现是hash,默认不支持排序,我们可以通过什么思路来实现map有序取值;值类型和引用类型的区别;GO语言中堆和栈的区别,什么数据会分配到堆中,什么变量会分配到栈中;
感兴趣的同学可以先看上一篇文章,能更好的理解这篇介绍的硬核知识点:逃逸分析。
逃逸分析
我们在之前有提到堆和栈的概念,要搞清楚GO的逃逸分析一定要先搞清楚堆栈的特点:
正如我们上面提到的,内存分配既可以分配到堆中,也可以分配到栈中。
那么什么样的数据会被分配到栈中,什么样的数据又会被分配到堆中呢?GO语言是如何进行内存分配的呢?其设计初衷和实现原理是什么呢?
我们先来了解一下内存管理、堆、栈的知识点:
内存管理
内存管理主要包括两个动作:分配与释放。逃逸分析就是服务于内存分配,为了更好理解逃逸分析,我们再来回顾一下堆栈的特点:
栈
在Go中,栈的内存是由编译器自动进行分配和释放,栈区往往存储着函数参数、局部变量和调用函数帧,它们随着函数的创建而分配,函数的退出而销毁。
一个goroutine对应一个栈,栈是调用栈(call stack)的简称。一个栈通常又包含了许多栈帧(stack frame),它描述的是函数之间的调用关系,每一帧对应一个尚未返回的函数调用,它本身也是以栈形式存放数据。
堆
与栈不同的是,应用程序在运行时只会存在一个堆。
我们可以简单理解为:我们在GO开发过程中要考虑的内存管理只是针对堆内存而言的。
程序在运行期间可以主动从堆上申请内存,这些内存通过Go的内存分配器分配,并由垃圾收集器回收。
堆和栈的对比
加锁
- 栈不需要加锁:栈是每个goroutine独有的,这就意味着栈上的内存操作是不需要加锁的。
- 堆有时需要加锁:堆上的内存,有时需要加锁防止多线程冲突
延伸知识点:为什么堆上的内存有时需要加锁?而不是一直需要加锁呢?
因为Go的内存分配策略学习了TCMalloc的线程缓存思想,他为每个处理器P分配了一个mcache,从mcache分配内存也是无锁的
性能
- 堆内存管理 性能差:对于程序堆上的内存回收,还需要通过标记清除阶段,例如Go采用的三色标记法。
- 栈内存管理 性能好:栈上的内存,它的分配与释放非常高效的。简单地说,它只需要两个CPU指令:一个是分配入栈,另外一个是栈内释放。只需要借助于栈相关寄存器即可完成。
缓存策略
- 栈缓存性能更好
- 堆缓存性能较差
原因是:栈内存能更好地利用CPU的缓存策略,因为栈空间相较于堆来说是更连续的。
逃逸分析优势
上面说了这么多堆和栈的知识点,目的是为了让大家更好的理解逃逸分析。
正如我们讲的,相比于把内存分配到堆中,分配到栈中优势更明显。
Go语言也是这么做的:Go编译器会尽可能将变量分配到到栈上。
但是,当编译器无法证明函数返回后,该变量没有被引用,那么编译器就必须在堆上分配该变量,以此避免悬挂指针(dangling pointer)。另外,如果局部变量非常大,也会将其分配在堆上。
Go是如何确定内存是分配到栈上还是堆上的呢?
答案就是:逃逸分析。
编译器通过逃逸分析技术去选择堆或者栈,逃逸分析的基本思想如下:检查变量的生命周期是否是完全可知的,如果通过检查,则在栈上分配。否则,就是所谓的逃逸,必须在堆上进行分配。
逃逸分析原则
Go语言虽然没有明确说明逃逸分析原则,但是有以下几点准则,是可以参考的。
- 不同于jvm的运行时逃逸分析,Go的逃逸分析是在编译期完成的:编译期无法确定的参数类型必定放到堆中;
- 如果变量在函数外部没有引用,则优先放到栈中;
- 如果变量在函数外部存在引用,则必定放在堆中;
- 如果变量占用内存较大时,则优先放到堆中;
逃逸分析举例
我们使用这个命令来查看逃逸分析的结果: go build -gcflags '-m -m -l'
1.参数是interface类型
package main
import "fmt"
func main() {
a := 666
fmt.Println(a)
}
运行结果

原因分析
因为Println(a ...interface{})的参数是interface{}类型,编译期无法确定其具体的参数类型,所以内存分配到堆中。

2. 变量在函数外部有引用
package main
func test() *int {
a := 10
return &a
}
func main() {
_ = test()
}
运行结果
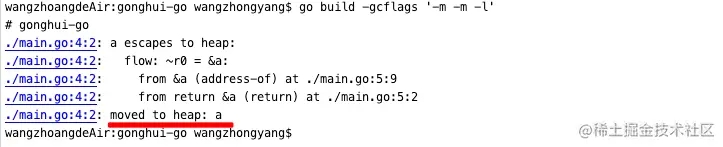
原因分析
变量a在函数外部存在引用。
我们来分析一下执行过程:当函数执行完毕,对应的栈帧就被销毁,但是引用已经被返回到函数之外。如果这时外部通过引用地址取值,虽然地址还在,但是这块内存已经被释放回收了,这就是非法内存。
在这种情况下必须分配到堆上。
3. 变量内存占用较大
package main
func test() {
a := make([]int, 10000, 10000)
for i := 0; i < 10000; i++ {
a[i] = i
}
}
func main() {
test()
}
运行结果

原因分析
我们定义了一个容量为10000的int类型切片,内存分配到了栈上。
我们再简单修改一下代码,将切片的容量和长度修改为1,再次查看逃逸分析的结果,我们发现,没有发生逃逸,内存默认分类到了栈上。
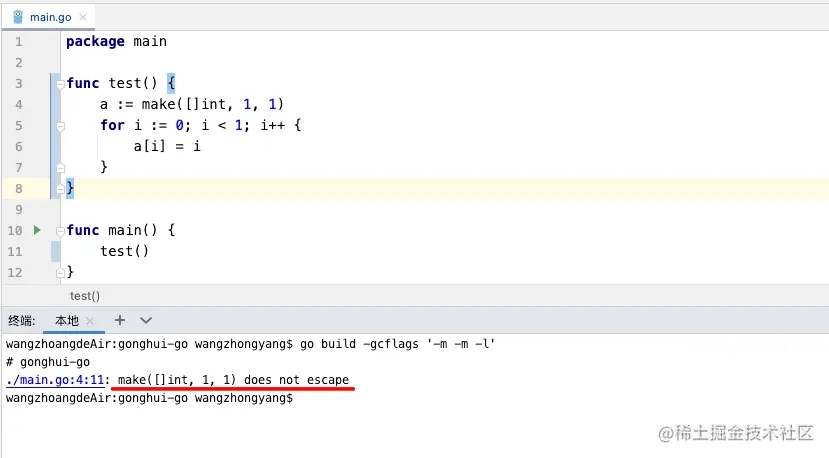
所以,当变量占用内存较大时,会发生逃逸分析,将内存分配到堆上。
4. 变量大小不确定时
我们再简单修改一下上面的代码:
package main
func test() {
l := 1
a := make([]int, l, l)
for i := 0; i < l; i++ {
a[i] = i
}
}
func main() {
test()
}
运行结果
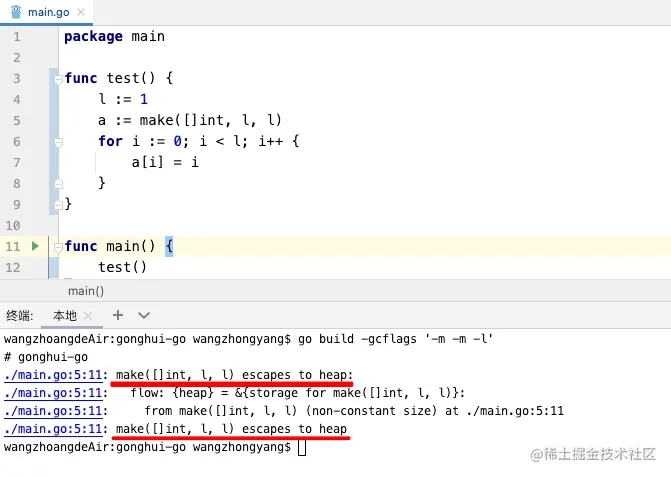
原因分析
我们通过控制台的输出结果可以很明显的看出:发生了逃逸,分配到了heap堆中。
原因是这样的:
我们虽然在代码段中给变量 l 赋值了1,但是编译期间只能识别到初始化int类型切片时,传入的长度和容量是变量l,编译器并不能确定变量l的值,所以发生了逃逸,会把内存分配到堆中。
思考题
好了,我们举了4个逃逸分析的经典案例,相信聪明的你已经理解了逃逸分析的作用和发生逃逸的场景。
我们来想一下,在理解逃逸分析的原理之后,在开发的过程中如何更好的编码,进而提高程序的效率,更好的利用内存呢?
如何实践?
理解逃逸分析一定能帮助我们写出更好的程序。知道变量分配在栈堆之上的差别后,我们就要尽量写出分配在栈上的代码。因为堆上的变量变少后,可以减轻内存分配的开销,减小GC的压力,提高程序的运行速度。
但是我们也要有过犹不及的指导思想。
我认为没有一成不变的开发模式,我们一定是在不断的需求变化,业务变化中求得平衡的:
举个日常开发中函数传参栗子:
有些场景下我们不应该传递结构体指针,而应该直接传递结构体。
为什么会这样呢?虽然直接传递结构体需要值拷贝,但是这是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。
当然这种做法不是绝对的,要根据场景去分析:
- 如果结构体较大,传递结构体指针更合适,因为指针类型相比值类型能节省大量的内存空间
- 如果结构体较小,传递结构体更适合,因为在栈上分配内存,可以有效减少GC压力
总结
通过本文的介绍,相信你一定加深了堆栈的理解;搞清楚逃逸分析的作用和原理之后能够指导我们写出更优雅的代码。
我们在日常开发中,要根据实际场景考虑,如何将内存尽量分配到栈中,减少GC的压力,提高性能。
如何找到应用开发效率,程序运行效率,对机器的压力及负载的平衡点,是程序员进阶之旅中的必修课。
以上就是Go逃逸分析示例详解的详细内容,更多关于Go逃逸分析的资料请关注我们其它相关文章!
相关推荐
-
浅谈Golang内存逃逸
目录 1.什么是内存逃逸 2.什么是逃逸分析 3.小结 4.逃逸分析案例 1.函数返回局部指针变量 2.interface类型逃逸 1.interface产生逃逸 2.指向栈对象的指针不能在堆中 3.闭包产生逃逸 4. 变量大小不确定及栈空间不足引发逃逸 5.总结 1.什么是内存逃逸 在一段程序中,每一个函数都会有自己的内存区域分配自己的局部变量,返回值,这些内存会由编译器在栈中进行分配,每一个函数会分配一个栈帧,在函数运行结束后销毁,但是有些变量我们想在函数运行结束后仍然使用,就需要把这个变量
-

GoLang 逃逸分析的机制详解
对于手动管理内存的语言,比如 C/C++,调用著名的malloc和new函数可以在堆上分配一块内存,这块内存的使用和销毁的责任都在程序员.一不小心,就会发生内存泄露,搞得胆战心惊. 但是 Golang 并不是这样,虽然 Golang 语言里面也有 new.Golang 编译器决定变量应该分配到什么地方时会进行逃逸分析.使用new函数得到的内存不一定就在堆上.堆和栈的区别对程序员"模糊化"了,当然这一切都是Go编译器在背后帮我们完成的.一个变量是在堆上分配,还是在栈上分配,是经过编译器的
-
Go语言中的逃逸分析究竟是什么?
目录 1.逃逸分析介绍 2.Go中内存分配在哪里? 3.Go与C++内存分配的区别 4.逃逸分析骚操作 5.逃逸分析引申示例说明 1.逃逸分析介绍 学计算机的同学都知道,在编译原理中,分析指针动态范围的方法称之为逃逸分析.通俗来讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了"逃逸". Go语言的逃逸分析是编译器执行静态代码分析后,对内存管理进行的优化和简化,它可以决定一个变量是分配到堆还栈上. 写过C/C++的小伙伴应该知道,使用比较经典的malloc和new函数可以
-
Go逃逸分析示例详解
目录 引言大纲 逃逸分析 内存管理 栈 堆 堆和栈的对比 加锁 性能 缓存策略 逃逸分析优势 逃逸分析原则 逃逸分析举例 1.参数是interface类型 2. 变量在函数外部有引用 3. 变量内存占用较大 4. 变量大小不确定时 思考题 总结 引言大纲 这个月我会整理分享一系列后端工程师求职面试相关的文章,知识脉络图如下: JAVA/GO/PHP 面试常问的知识点 DB:MySql PgSql Cache: Redis MemCache MongoDB 数据结构 算法 微服务&高并发 流媒体
-
Go语言基础闭包的原理分析示例详解
目录 一. 闭包概述 二. 代码演示 运行结果 代码说明 一. 闭包概述 闭包就是解决局部变量不能被外部访问的一种解决方案 闭包是把函数当作返回值的一种应用 二. 代码演示 总体思想为:在函数内部定义局部变量,把另一个函数当作返回值,局部变量对于返回值函数相当于全部变量,所以多次调用返回值函数局部变量的值跟随变化. // closure.go package main import ( "fmt" "strings" ) func main() { f := clo
-
python多线程编程方式分析示例详解
在Python多线程中如何创建一个线程对象如果你要创建一个线程对象,很简单,只要你的类继承threading.Thread,然后在__init__里首先调用threading.Thread的__init__方法即可 复制代码 代码如下: import threading class mythread(threading.Thread): def __init__(self, threadname): threading.Thread.__init__(self, name = thread
-
Sentinel熔断规则原理示例详解分析
目录 概述 熔断(降级)策略 慢调用比例 概念 测试 异常比例 概念 测试 异常数 概念 测试 概述 除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一. 由于调用关系的复杂性,如果调用链路中的某个资源不稳定,最终会导致请求发生堆积. Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时.异常比例升高.异常数堆积) 对这个资源的调用进行限制,让请求快速失败从而避免影响到其它的资源而导致级联错误. 当资源被降级后,在接下来的降级时间窗口之内
-
Sentinel热点规则示例详解分析
目录 概念 @SentinelResource 小试牛刀 TestController.java defaultFallback fallback 流量控制 熔断降级 热点参数限流 高级选项 概念 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制 热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流. 热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源
-
python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
php示例详解Constructor Prototype Pattern 原型模式
原型模式中主要角色 抽象原型(Prototype)角色:声明一个克隆自己的接口 具体原型(Concrete Prototype)角色:实现一个克隆自己的操作 当一个类大部分都是相同的只有部分是不同的时候,如果需要大量这个类的对象,每次都重复实例化那些相同的部分是开销很大的,而如果clone之前建立对象的那些相同的部分,就可以节约开销. 针对php的一种实现方式就是__construct()和initialize函数分开分别处理这个类的初始化,construct里面放prototype也就是公共的
-
java 与testng利用XML做数据源的数据驱动示例详解
java 与testng利用XML做数据源的数据驱动示例详解 testng的功能很强大,利用@DataProvider可以做数据驱动,数据源文件可以是EXCEL,XML,YAML,甚至可以是TXT文本.在这以XML为例: 备注:@DataProvider的返回值类型只能是Object[][]与Iterator<Object>[] TestData.xml: <?xml version="1.0" encoding="UTF-8"?> <
-
Python网络爬虫中的同步与异步示例详解
一.同步与异步 #同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> <-e_url-> <-f_url-> <-g_url-> <-h_url-> <--i_ur
-
Vue中的vue-resource示例详解
vue-resource特点 vue-resource插件具有以下特点: 1. 体积小 vue-resource非常小巧,在压缩以后只有大约12KB,服务端启用gzip压缩后只有4.5KB大小,这远比jQuery的体积要小得多. 2. 支持主流的浏览器 和Vue.js一样,vue-resource除了不支持IE 9以下的浏览器,其他主流的浏览器都支持. 3. 支持Promise API和URI Templates Promise是ES6的特性,Promise的中文含义为"先知",Pro