C++解析obj模型文件方法介绍
目录
- 一、前言
- 二、中间文件
- 三、使用
- 四、完整代码
一、前言
tinyobjloader地址:
而tinyobjloader库只有一个头文件,可以很方便的读取obj文件。支持材质,不过不支持骨骼动画,vulkan官方教程便是使用的它。不过没有骨骼动画还是有很大的局限性,这里只是分享一下怎么读取材质和拆分网格。
二、中间文件
我抽象了一个ModelObject类表示模型数据,而一个ModelObject包含多个Sub模型,每个Sub模型使用同一材质(有的人称为图元Primitive或DrawCall)。最后我将其保存为文件,这样我的引擎便可直接解析ModelObject文件,而不是再去读obj、fbx等其他文件了。
这一节可以跳过,下一节是真正使用tinyobjloader库。
//一个文件会有多个ModelObject,一个ModelObject根据材质分为多个ModelSub
//注意ModelSub为一个材质,需要读取时合并网格
class ModelObject
{
friend class VK;
public:
//从源文件加载模型
static vector<ModelObject*> Create(string_view path_name);
void Load(string_view path_name);
//保存到文件
void SaveToFile(string_view path_name);
private:
vector<ModelObjectSub> _allSub; //下标减1 为材质,0为没有材质
vector<Vertex> _allVertex;//顶点缓存
vector<uint32_t> _allIndex;//索引缓存
vector<ModelObjectMaterial> _allMaterial;//所有材质
//------------------不同格式加载实现--------------------------------
//obj
static vector<ModelObject*> _load_obj(string_view path_name);
static vector<ModelObject*> _load_obj_2(string_view path_name);
};
ModelObjectSub只是表示在索引缓存的一段范围:
//模型三角形范围
struct ModelTriangleRange
{
ModelTriangleRange() :
_countTriangle{ 0 },
_offsetIndex{ 0 }
{}
size_t _countTriangle;
size_t _offsetIndex;
};
//子模型对象 范围
struct ModelObjectSub
{
ModelTriangleRange _range;
};
而ModelObjectMaterial表示模型材质:
//! 材质
struct Material
{
glm::vec4 _diffuseAlbedo;//漫反射率
glm::vec3 _fresnelR0; //菲涅耳系数
float _roughness; //粗糙度
};
//模型对象 材质
struct ModelObjectMaterial
{
//最后转为Model时,变为可以用的着色器资源
Material _material;
string _materialName;
//路径为空,则表示没有(VK加载时会返回0)
string _pathTexDiffuse;
string _pathTexNormal;
};
三、使用
首先引入头文件:
#define TINYOBJLOADER_IMPLEMENTATION #include <tiny_obj_loader.h>
接口原型,将obj文件变为多个ModelObject:
vector<ModelObject*> ModelObject::_load_obj_2(string_view path_name);
取得文件名,和文件所在路径(会自动加载路径下的同名mtl文件,里面包含了材质):
string str_path = string{ path_name };
string str_base = String::EraseFilename(path_name);
const char* filename = str_path.c_str();
const char* basepath = str_base.c_str();
基本数据:
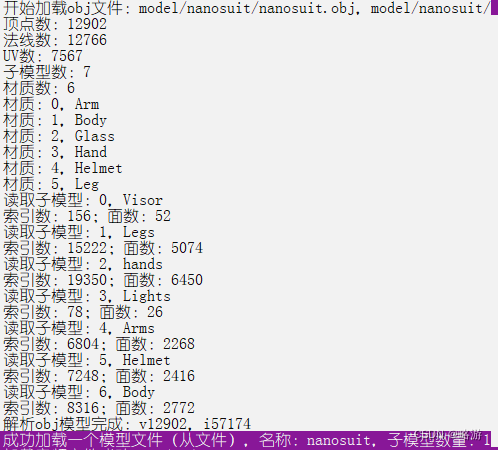
debug(format("开始加载obj文件:{},{}", filename, basepath));
bool triangulate = true;//三角化
tinyobj::attrib_t attrib; // 所有的数据放在这里
std::vector<tinyobj::shape_t> shapes;//子模型
std::vector<tinyobj::material_t> materials;//材质
std::string warn;
std::string err;
加载并打印一些信息:
bool b_read = tinyobj::LoadObj(&attrib, &shapes, &materials, &warn, &err, filename,
basepath, triangulate);
//打印错误
if (!warn.empty())
debug_warn(warn);
if (!err.empty())
debug_err(err);
if (!b_read)
{
debug_err(format("读取obj文件失败:{}", path_name));
return {};
}
debug(format("顶点数:{}", attrib.vertices.size() / 3));
debug(format("法线数:{}", attrib.normals.size() / 3));
debug(format("UV数:{}", attrib.texcoords.size() / 2));
debug(format("子模型数:{}", shapes.size()));
debug(format("材质数:{}", materials.size()));
这将打印以下数据:

由于obj文件只产生一个ModelObject,我们如下添加一个,并返回顶点、索引、材质等引用,用于后面填充:
//obj只有一个ModelObject vector<ModelObject*> ret; ModelObject* model_object = new ModelObject; std::vector<Vertex>& mo_vertices = model_object->_allVertex; std::vector<uint32_t>& mo_indices = model_object->_allIndex; vector<ModelObjectMaterial>& mo_material = model_object->_allMaterial; ret.push_back(model_object);
首先记录材质信息:
//------------------获取材质-------------------
mo_material.resize(materials.size());
for (size_t i = 0; i < materials.size(); ++i)
{
tinyobj::material_t m = materials[i];
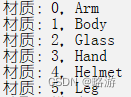
debug(format("材质:{},{}", i, m.name));
ModelObjectMaterial& material = model_object->_allMaterial[i];
material._materialName = m.name;
material._material._diffuseAlbedo = { m.diffuse[0], m.diffuse[1], m.diffuse[2], 1.0f };
material._material._fresnelR0 = { m.specular[0], m.specular[1], m.specular[2] };
material._material._roughness = ShininessToRoughness(m.shininess);
if(!m.diffuse_texname.empty())
material._pathTexDiffuse = str_base + m.diffuse_texname;
if (!m.normal_texname.empty())
material._pathTexNormal = str_base + m.normal_texname;
}
这将产生以下输出:
然后遍历shape,按材质记录顶点。这里需要注意的是,一个obj文件有多个shape,每个shape由n个三角面组成。而每个三角形拥有独立的材质编号,所以这里按材质分别记录,而不是一般的合并为整体:
//------------------获取模型-------------------
//按 材质 放入面的顶点
vector<vector<tinyobj::index_t>> all_sub;
all_sub.resize(1 + materials.size());//0为默认
for (size_t i = 0; i < shapes.size(); i++)
{//每一个子shape
tinyobj::shape_t& shape = shapes[i];
size_t num_index = shape.mesh.indices.size();
size_t num_face = shape.mesh.num_face_vertices.size();
debug(format("读取子模型:{},{}", i, shape.name));
debug(format("索引数:{};面数:{}", num_index, num_face));
//当前mesh下标(每个面递增3)
size_t index_offset = 0;
//每一个面
for (size_t j = 0; j < num_face; ++j)
{
int index_mat = shape.mesh.material_ids[j];//每个面的材质
vector<tinyobj::index_t>& sub_idx = all_sub[1 + index_mat];
sub_idx.push_back(shape.mesh.indices[index_offset++]);
sub_idx.push_back(shape.mesh.indices[index_offset++]);
sub_idx.push_back(shape.mesh.indices[index_offset++]);
}
}
按材质记录顶点的索引(tinyobj::index_t)后,接下来就是读取顶点的实际数据,并防止重复读取:
//生成子模型,并填入顶点
std::unordered_map<tinyobj::index_t, size_t, hash_idx, equal_idx>
uniqueVertices;//避免重复插入顶点
size_t i = 0;
for (vector<tinyobj::index_t>& sub_idx : all_sub)
{
ModelObjectSub sub;
sub._range._offsetIndex = i;
sub._range._countTriangle = sub_idx.size() / 3;
model_object->_allSub.push_back(sub);
for (tinyobj::index_t& idx : sub_idx)
{
auto iter = uniqueVertices.find(idx);
if (iter == uniqueVertices.end())
{
Vertex v;
//v
v._pos[0] = attrib.vertices[idx.vertex_index * 3 + 0];
v._pos[1] = attrib.vertices[idx.vertex_index * 3 + 1];
v._pos[2] = attrib.vertices[idx.vertex_index * 3 + 2];
// vt
v._texCoord[0] = attrib.texcoords[idx.texcoord_index * 2 + 0];
v._texCoord[1] = attrib.texcoords[idx.texcoord_index * 2 + 1];
v._texCoord[1] = 1.0f - v._texCoord[1];
uniqueVertices[idx] = mo_vertices.size();
mo_indices.push_back((uint32_t)mo_vertices.size());
mo_vertices.push_back(v);
}
else
{
mo_indices.push_back((uint32_t)iter->second);
}
++i;
}
}
debug(format("解析obj模型完成:v{},i{}", mo_vertices.size(), mo_indices.size()));
return ret;
上面用到的哈希函数:
struct equal_idx
{
bool operator()(const tinyobj::index_t& a, const tinyobj::index_t& b) const
{
return a.vertex_index == b.vertex_index
&& a.texcoord_index == b.texcoord_index
&& a.normal_index == b.normal_index;
}
};
struct hash_idx
{
size_t operator()(const tinyobj::index_t& a) const
{
return ((a.vertex_index
^ a.texcoord_index << 1) >> 1)
^ (a.normal_index << 1);
}
};
最后打印出来的数据如下:
对于材质的处理,漫反射贴图即是基本贴图,而法线(凹凸)贴图、漫反射率、菲涅耳系数、光滑度等需要渲染管线支持并与光照计算产生效果。
四、完整代码
可以此处获取最新的源码(我会改用Assimp,并添加骨骼动画、Blinn-Phong光照模型),也可以用后面的:传送门
如果有用,欢迎点赞、收藏、关注,我将更新更多C++相关的文章。
#define TINYOBJLOADER_IMPLEMENTATION
#include <tiny_obj_loader.h>
struct equal_idx
{
bool operator()(const tinyobj::index_t& a, const tinyobj::index_t& b) const
{
return a.vertex_index == b.vertex_index
&& a.texcoord_index == b.texcoord_index
&& a.normal_index == b.normal_index;
}
};
struct hash_idx
{
size_t operator()(const tinyobj::index_t& a) const
{
return ((a.vertex_index
^ a.texcoord_index << 1) >> 1)
^ (a.normal_index << 1);
}
};
float ShininessToRoughness(float Ypoint)
{
float a = -1;
float b = 2;
float c;
c = (Ypoint / 100) - 1;
float D;
D = b * b - (4 * a * c);
float x1;
x1 = (-b + sqrt(D)) / (2 * a);
return x1;
}
vector<ModelObject*> ModelObject::_load_obj_2(string_view path_name)
{
string str_path = string{ path_name };
string str_base = String::EraseFilename(path_name);
const char* filename = str_path.c_str();
const char* basepath = str_base.c_str();
bool triangulate = true;
debug(format("开始加载obj文件:{},{}", filename, basepath));
tinyobj::attrib_t attrib; // 所有的数据放在这里
std::vector<tinyobj::shape_t> shapes;//子模型
std::vector<tinyobj::material_t> materials;
std::string warn;
std::string err;
bool b_read = tinyobj::LoadObj(&attrib, &shapes, &materials, &warn, &err, filename,
basepath, triangulate);
//打印错误
if (!warn.empty())
debug_warn(warn);
if (!err.empty())
debug_err(err);
if (!b_read)
{
debug_err(format("读取obj文件失败:{}", path_name));
return {};
}
debug(format("顶点数:{}", attrib.vertices.size() / 3));
debug(format("法线数:{}", attrib.normals.size() / 3));
debug(format("UV数:{}", attrib.texcoords.size() / 2));
debug(format("子模型数:{}", shapes.size()));
debug(format("材质数:{}", materials.size()));
//obj只有一个ModelObject
vector<ModelObject*> ret;
ModelObject* model_object = new ModelObject;
std::vector<Vertex>& mo_vertices = model_object->_allVertex;
std::vector<uint32_t>& mo_indices = model_object->_allIndex;
vector<ModelObjectMaterial>& mo_material = model_object->_allMaterial;
ret.push_back(model_object);
//------------------获取材质-------------------
mo_material.resize(materials.size());
for (size_t i = 0; i < materials.size(); ++i)
{
tinyobj::material_t m = materials[i];
debug(format("材质:{},{}", i, m.name));
ModelObjectMaterial& material = model_object->_allMaterial[i];
material._materialName = m.name;
material._material._diffuseAlbedo = { m.diffuse[0], m.diffuse[1], m.diffuse[2], 1.0f };
material._material._fresnelR0 = { m.specular[0], m.specular[1], m.specular[2] };
material._material._roughness = ShininessToRoughness(m.shininess);
if(!m.diffuse_texname.empty())
material._pathTexDiffuse = str_base + m.diffuse_texname;
if (!m.normal_texname.empty())//注意这里凹凸贴图(bump_texname)更常见
material._pathTexNormal = str_base + m.normal_texname;
}
//------------------获取模型-------------------
//按 材质 放入面的顶点
vector<vector<tinyobj::index_t>> all_sub;
all_sub.resize(1 + materials.size());//0为默认
for (size_t i = 0; i < shapes.size(); i++)
{//每一个子shape
tinyobj::shape_t& shape = shapes[i];
size_t num_index = shape.mesh.indices.size();
size_t num_face = shape.mesh.num_face_vertices.size();
debug(format("读取子模型:{},{}", i, shape.name));
debug(format("索引数:{};面数:{}", num_index, num_face));
//当前mesh下标(每个面递增3)
size_t index_offset = 0;
//每一个面
for (size_t j = 0; j < num_face; ++j)
{
int index_mat = shape.mesh.material_ids[j];//每个面的材质
vector<tinyobj::index_t>& sub_idx = all_sub[1 + index_mat];
sub_idx.push_back(shape.mesh.indices[index_offset++]);
sub_idx.push_back(shape.mesh.indices[index_offset++]);
sub_idx.push_back(shape.mesh.indices[index_offset++]);
}
}
//生成子模型,并填入顶点
std::unordered_map<tinyobj::index_t, size_t, hash_idx, equal_idx>
uniqueVertices;//避免重复插入顶点
size_t i = 0;
for (vector<tinyobj::index_t>& sub_idx : all_sub)
{
ModelObjectSub sub;
sub._range._offsetIndex = i;
sub._range._countTriangle = sub_idx.size() / 3;
model_object->_allSub.push_back(sub);
for (tinyobj::index_t& idx : sub_idx)
{
auto iter = uniqueVertices.find(idx);
if (iter == uniqueVertices.end())
{
Vertex v;
//v
v._pos[0] = attrib.vertices[idx.vertex_index * 3 + 0];
v._pos[1] = attrib.vertices[idx.vertex_index * 3 + 1];
v._pos[2] = attrib.vertices[idx.vertex_index * 3 + 2];
// vt
v._texCoord[0] = attrib.texcoords[idx.texcoord_index * 2 + 0];
v._texCoord[1] = attrib.texcoords[idx.texcoord_index * 2 + 1];
v._texCoord[1] = 1.0f - v._texCoord[1];
uniqueVertices[idx] = mo_vertices.size();
mo_indices.push_back((uint32_t)mo_vertices.size());
mo_vertices.push_back(v);
}
else
{
mo_indices.push_back((uint32_t)iter->second);
}
++i;
}
}
debug(format("解析obj模型完成:v{},i{}", mo_vertices.size(), mo_indices.size()));
return ret;
}
到此这篇关于C++解析obj模型文件方法介绍的文章就介绍到这了,更多相关C++解析obj内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++可调用对象callable object深入分析
目录 为什么需要他 他究竟是啥 他怎样被使用呢 本作者一致的观点就是 在任何语言执行的时候先去思考汇编层面能不能做到 如果能做到 那么高级语言才能做到 无论你推出什么新特性 用户态汇编你都是绕不开的 比如你要调用函数 那么你必须要使用call指令 那么就必须要有函数地址 接下来我们来详细说说为什么c++11要推出这个新概念 以及他解决了什么问题 还有如何使用它 Tips:c++的设计哲学是你必须时刻清楚你自己在干什么 stl内部并不会给你执行任何的安全检查 程序直接崩溃也是完全有可能的 功力不够
-
C++解析obj模型文件方法介绍
目录 一.前言 二.中间文件 三.使用 四.完整代码 一.前言 tinyobjloader地址: 传送门 而tinyobjloader库只有一个头文件,可以很方便的读取obj文件.支持材质,不过不支持骨骼动画,vulkan官方教程便是使用的它.不过没有骨骼动画还是有很大的局限性,这里只是分享一下怎么读取材质和拆分网格. 二.中间文件 我抽象了一个ModelObject类表示模型数据,而一个ModelObject包含多个Sub模型,每个Sub模型使用同一材质(有的人称为图元Primitive或Dr
-
C++解析wav文件方法介绍
目录 一.前言 二.接口 三.具体步骤 四.完整源码 一.前言 一开始本来在网上找代码,不过改了好几个都不是很好用.因为很多wav文件的fmt块后面并不是data块,经常还带有其他块,正确的方法应该是按MSDN的方法,找到data块再读取. 二.接口 最后接口如下: class AudioReader { public: struct PCM { int _numChannel;//通道数 1,2 AL_FORMAT_MONO8,AL_FORMAT_STEREO8 int _bitPerSamp
-
Oracle RMAN自动备份控制文件方法介绍
RMAN(Recovery Manager)是一种用于备份(backup).还原(restore)和恢复(recover) 数据库的 Oracle 工具.RMAN只能用于ORACLE8或更高的版本中.它能够备份整个数据库或数据库部件,如表空间.数据文件.控制文件.归档文件以及Spfile参数文件.RMAN也允许您进行增量数据块级别的备份,增量RMAN备份是时间和空间有效的,因为他们只备份自上次备份以来有变化的那些数据块.而且,通过RMAN提供的接口,第三方的备份与恢复软件如veritas将提供更
-
oracle数据库导入TXT文件方法介绍
客户端连接数据库导入 1. 安装有oracle客户端,配好监听. 2. 以oracle数据库app用户的表user_svc_info为例 <span style="color:#3333ff;">CREATE TABLE USER_SVC_INFO( PHONE varchar2(20) NOT NULL, SVC_ID varchar2(32) NOT NULL, P_USERNAME varchar2(100) NULL, USER_STATUS number NOT
-
Python读写Excel文件方法介绍
一.读取excel 这里介绍一个不错的包xlrs,可以工作在任何平台.这也就意味着你可以在Linux下读取Excel文件. 首先,打开workbook: 复制代码 代码如下: import xlrd wb = xlrd.open_workbook('myworkbook.xls') 检查表单名字: 复制代码 代码如下: wb.sheet_names() 得到第一张表单,两种方式:索引和名字 复制代码 代码如下: sh = wb.sheet_by_index(0) sh = wb.sheet_by
-
oracle中通配符和运算符的使用方法介绍
用于where比较条件的有: 等于:=.<.<=.>.>=.<> 包含:in.not in exists.not exists 范围:between...and.not between....and 匹配测试:like.not like Null测试:is null.is not null 布尔链接:and.or.not 通配符: 在where子句中,通配符可与like条件一起使用.在Oracle中: %(百分号): 用来表示任意数量的字符,或者可能根本没有字符. _(
-
C#下解析HTML的两种方法介绍
在搜索引擎的开发中,我们需要对Html进行解析.本文介绍C#解析HTML的两种方法.AD: 在搜索引擎的开发中,我们需要对网页的Html内容进行检索,难免的就需要对Html进行解析.拆分每一个节点并且获取节点间的内容.此文介绍两种C#解析Html的方法. C#解析Html的第一种方法:用System.Net.WebClient下载Web Page存到本地文件或者String中,用正则表达式来分析.这个方法可以用在Web Crawler等需要分析很多Web Page的应用中.估计这也是大家最直接,
-
python中解析json格式文件的方法示例
前言 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于JavaScript(Standard ECMA-262 3rd Edition - December 1999)的一个子集. JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等).这些特性使JSON成为理想的数据交换语言.易于人阅读和编写,同时也易于机器解析和生成. 本文主要介
-
Java多线程中不同条件下编写生产消费者模型方法介绍
简介: 生产者.消费者模型是多线程编程的常见问题,最简单的一个生产者.一个消费者线程模型大多数人都能够写出来,但是一旦条件发生变化,我们就很容易掉进多线程的bug中.这篇文章主要讲解了生产者和消费者的数量,商品缓存位置数量,商品数量等多个条件的不同组合下,写出正确的生产者消费者模型的方法. 欢迎探讨,如有错误敬请指正 生产消费者模型 生产者消费者模型具体来讲,就是在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品.生产消费者模式
-
tensorflow模型文件(ckpt)转pb文件的方法(不知道输出节点名)
网上关于tensorflow模型文件ckpt格式转pb文件的帖子很多,本人几乎尝试了所有方法,最后终于成功了,现总结如下.方法无外乎下面两种: 使用tensorflow.python.tools.freeze_graph.freeze_graph 使用graph_util.convert_variables_to_constants 1.tensorflow模型的文件解读 使用tensorflow训练好的模型会自动保存为四个文件,如下 checkpoint:记录近几次训练好的模型结果(名称).