Seaborn数据分析NBA球员信息数据集
目录
- 1. 数据介绍
- 2. 案例演示
- 2.1 获取数据
- 2.2 查看数据基本信息
- 2.3 数据分析
- 2.3.1 效率值相关性分析
本案例使用 Jupyter Notebook进行案例演示,数据集为NBA球员信息数据集。本项目将进行完整的数据分析演示。
1. 数据介绍
- 数据集共有342个球员样本,38个特征,即342行×38列。
- 数据集主要信息如下表所示:
| 球员姓名 | 位置 | 身高 | 体重 | 年龄 | 球龄 | 上场次数 | 场均时间 | 进攻能力 | 防守能力 | 是否入选过全明星 | 球员薪金 |
|---|
- 本数据集主要可以用来做数据处理以及数据挖掘,进行数据可视化。
- 本小结,我们将对NBA球员数据集进行初步统计学分析,并且绘制出相关性热力图。
2. 案例演示
2.1 获取数据
导入相关库,并使用如下代码进行本地数据集获取。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 获取数据集
NBA = pd.read_csv("nba_2017_nba_players_with_salary.csv")
NBA.head()
运行结果:
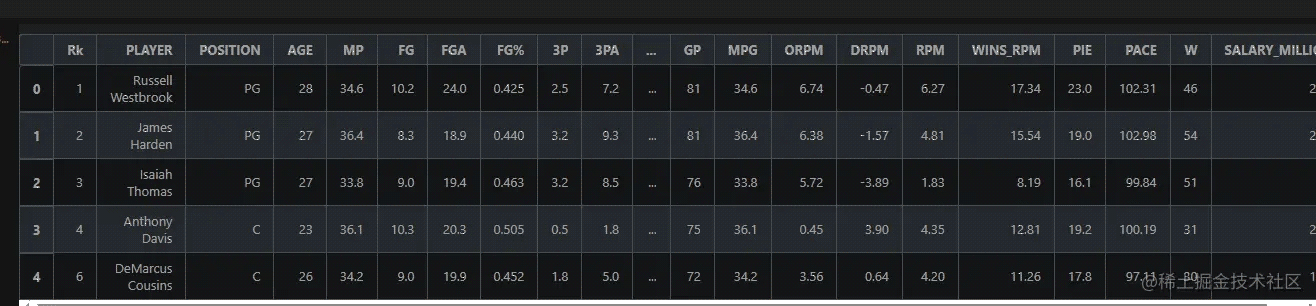
2.2 查看数据基本信息
先进行简单的统计学分析,查看标准差、中位数、方差等等信息。
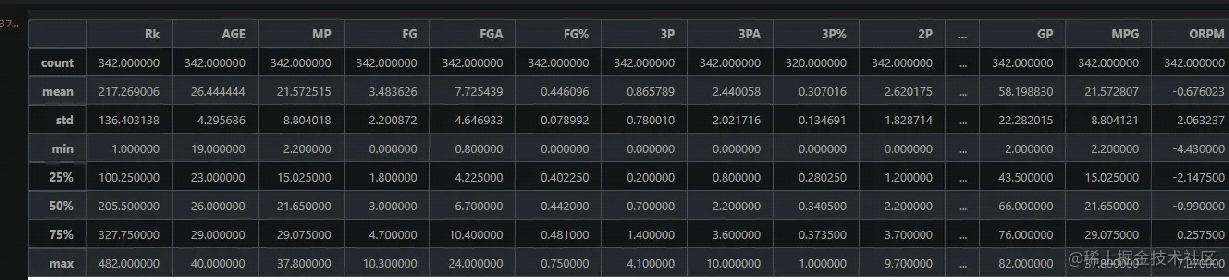
# 看一下数据有多少 NBA.shape # 查看基本统计信息 NBA.describe()
部分运行结果:
2.3 数据分析
2.3.1 效率值相关性分析
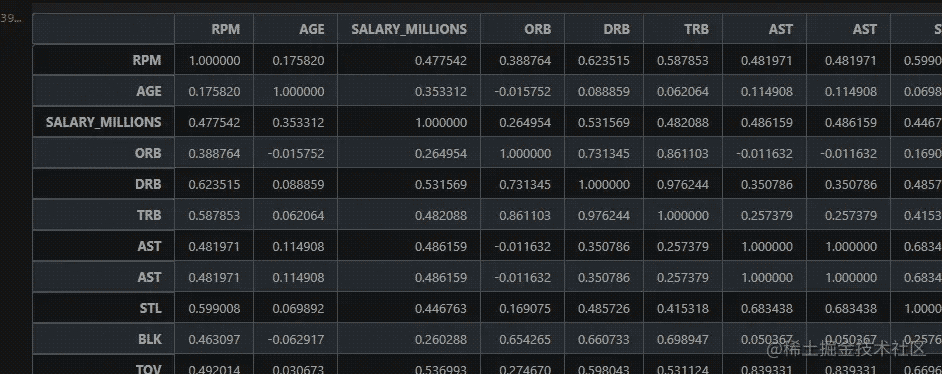
在众多数据中,有一项名为RPM,表示球员的效率值。该数据反映球员在场时对球队比赛获胜的贡献大小,最能反映球员的综合实力。我们可以看一下它与其他数据的相关性。
首先,我们取出几个有用的特征分析相关性,并绘制热力图。
# 2. 数据分析 ## 2.1 效率值相关性分析 NBA_1 = NBA.loc[:, ['RPM','AGE','SALARY_MILLIONS','ORB','DRB','TRB','AST','AST','STL','BLK','TOV','PF','POINTS','GP','MPG','ORPM','DRPM']] NBA_1.head()
然后,使用如下代码计算出相关性表。
# 计算相关性 # 获取两列之间的相关性 corr = NBA_1.corr() corr
部分运行结果如下图所示:
最后,使用刚才的相关性表,绘制出相关性关系热力图
# 调用热力图绘制相关性关系
plt.figure(figsize=(20,20),dpi=120)
sns.heatmap(corr, square=True, linewidths=0.1, annot=True)
# 保存图像
plt.savefig("./test.png")
# 颜色越深:相关性越弱
# 颜色越浅:相关性越强
运行结果如下图所示:

以上就是Seaborn数据分析NBA球员信息数据集的详细内容,更多关于Seaborn数据分析的资料请关注我们其它相关文章!
相关推荐
-

python挖掘蛋卷基金投资组合数据分析
目录 一.网页分析 1.打开网页 2.查看json 二.数据获取 1.观察json的结构 三.代码实现 1.基本操作 2.写一个可以重复使用的函数 3.完整代码 一.网页分析 1.打开网页 我们随意打开一个蛋卷基金上投资组合的网页,例如: 链接: https://danjuanapp.com/strategy/CSI1033 这里以Microsoft Edge浏览器为例 . 点击下载查看详图 2.查看json 选择“XHR”,发现有一个以基金编号命名的文件,单击它,查看请求标头. 点击下载查看详
-
kaggle+mnist实现手写字体识别
现在的许多手写字体识别代码都是基于已有的mnist手写字体数据集进行的,而kaggle需要用到网站上给出的数据集并生成测试集的输出用于提交.这里选择keras搭建卷积网络进行识别,可以直接生成测试集的结果,最终结果识别率大概97%左右的样子. # -*- coding: utf-8 -*- """ Created on Tue Jun 6 19:07:10 2017 @author: Administrator """ from keras.mo
-
Python数据分析Numpy中常用相关性函数
目录 摘要: 一.股票相关性分析 二.多项式 三.求极值的知识 摘要: NumPy中包含大量的函数,这些函数的设计初衷是能更方便地使用,掌握解这些函数,可以提升自己的工作效率.这些函数包括数组元素的选取和多项式运算等.下面通过实例进行详细了解. 前述通过对某公司股票的收盘价的分析,了解了某些Numpy的一些函数.通常实际中,某公司的股价被另外一家公司的股价紧紧跟随,它们可能是同领域的竞争对手,也可能是同一公司下的不同的子公司.可能因两家公司经营的业务类型相同,面临同样的挑战,需要相同的原料和资源
-
kaggle数据分析家庭电力消耗过程详解
目录 一.家庭电力消耗分析 1.背景描述 数据说明 2.数据来源 3.问题描述 二.数据加载 三.预测 1.Prophet介绍 2.模型介绍 3.Prophet优点 一.家庭电力消耗分析 1.背景描述 本数据集包含了一个家庭6个月的用电数据,收集于2007年1月至2007年6月.这些数据包括全球有功功率.全球无功功率.电压.全球强度.分项计量1(厨房).分项计量2(洗衣房)和分项计量3(电热水器和空调)等信息.该数据集共有260,640个测量值,可以为了解家庭用电情况提供重要的见解. 我们要感谢
-
JS数据分析数据去重及参数序列化示例
目录 列表去重 对象转为查询字符串 获取查询参数 列表去重 使用 Set 数据结构 const set = new Set([2, 8, 3, 8, 5]) 注:Set 数据结构认为对象永不相等,即使是两个空对象,在 Set 结构内部也是不等的 方法封装 const uniqueness = (data, key) => { const hash = new Map() return data.filter(item => !hash.has(item[key]) && has
-
使用pytorch完成kaggle猫狗图像识别方式
kaggle是一个为开发商和数据科学家提供举办机器学习竞赛.托管数据库.编写和分享代码的平台,在这上面有非常多的好项目.好资源可供机器学习.深度学习爱好者学习之用. 碰巧最近入门了一门非常的深度学习框架:pytorch,所以今天我和大家一起用pytorch实现一个图像识别领域的入门项目:猫狗图像识别. 深度学习的基础就是数据,咱们先从数据谈起.此次使用的猫狗分类图像一共25000张,猫狗分别有12500张,我们先来简单的瞅瞅都是一些什么图片. 我们从下载文件里可以看到有两个文件夹:train和t
-
Pandas数据分析之groupby函数用法实例详解
目录 正文 一.了解groupby 二.数据文件简介 三.求各个商品购买量 四.求各个商品转化率 五.转化率最高的30个商品及其转化率 小小の总结 正文 今天本人在赶学校课程作业的时候突然发现groupby这个分组函数还是蛮有用的,有了这个分组之后你可以实现很多统计目标. 当然,最主要的是,他的使用非常简单 本期我们以上期作业为例,单走一篇文章来看看这个函数可以实现哪些功能: (本期需要准备的行囊): jupyter notebook环境(anaconda自带) pandas第三方库 numpy
-
Seaborn数据分析NBA球员信息数据集
目录 1. 数据介绍 2. 案例演示 2.1 获取数据 2.2 查看数据基本信息 2.3 数据分析 2.3.1 效率值相关性分析 本案例使用 Jupyter Notebook进行案例演示,数据集为NBA球员信息数据集.本项目将进行完整的数据分析演示. 1. 数据介绍 数据集共有342个球员样本,38个特征,即342行×38列. 数据集主要信息如下表所示: 球员姓名 位置 身高 体重 年龄 球龄 上场次数 场均时间 进攻能力 防守能力 是否入选过全明星 球员薪金 本数据集主要可以用来做数据处理以及
-
使用Python实现NBA球员数据查询小程序功能
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于早起Python ,作者投稿君 一.前言 有时将代码转成带有界面的程序,会极大地方便使用,虽然在网上有很多现成的GUI系统,但是套用别人的代码,心里难免有些尴尬,所以本文将用Python爬虫结合wxpython模块构造一个NBA爬虫小软件 本文框架构造将分为二个部分讲解: 构建GUI界面举例套用爬虫框架 主要涉及的Python模块有 requests wx pymysql pand
-
详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class NbaprojectItem(scrapy.Item): # define the fields for yo
-
c语言获取直播吧最近一周nba比赛信息
就是用c语言的写的一个简单http请求,并分析其响应,原理很简单,主要是分析http响应,麻烦的是提取其中的比赛信息 复制代码 代码如下: #include <unistd.h>#include <stdio.h>#include <stdlib.h>#include <string.h>#include <signal.h>#include <errno.h>#include <sys/socket.h>#include
-
SpringBoot整合Mybatis与thymleft实现增删改查功能详解
首先我们先创建项目 注意:创建SpringBoot项目时一定要联网不然会报错 项目创建好后我们首先对 application.yml 进行编译 #指定端口号server: port: 8888#配置mysql数据源spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/nba?serverTimezone=Asia/Shanghai use
-
Python数据分析处理(三)--运动员信息的分组与聚合
目录 3.1 数据的爬取 3.2统计男篮.女篮运动员的平均年龄.身高.体重 3.3统计男篮运动员年龄.身高.体重的极差值 3.4 统计男篮运动员的体质指数 3.4.1添加体重指数 3.4.2计算bmi值并添加数据 3.1 数据的爬取 代码: import pandas as pd f = open('运动员信息表.csv') data=pd.read_csv(f,skiprows=0,header=0) print(data) 运行结果: 首先使用pd.read_csv(f,skiprows=0
-
小白如何入门Python? 制作一个网站为例
首先最重要的问题是为什么要学习python?这个问题这个将指导你如何学习Python和学习的方式. 以你最终想制作一个网站为例.从一个通用的学习资源列表开始不仅会消磨你的激情,而且你获得的知识很难应用,我曾经尝试过不通过上下文和具体应用来学习编程,但是我几乎没有获得任何有用的技能. 当我3年前学习python时,我想创建一个网站.这对于任何一个学习Pyhon人来说,不足为奇. 1.找到是什么激励你 找到并保持你的动机是关键-我高中睡了很多个的程序设计课,因为它只让我们记住了一堆语法.另一方面,当
-
Python实现数据清洗的示例详解
目录 前言 去掉信息不全的用户 描述 答案 修补缺失的用户数据 描述 答案 解决牛客网用户重复的数据 描述 答案 统一最后刷题日期的格式 描述 答案 将用户的json文件转换为表格形式 描述 答案 前言 Python实际针对数据分析的学习是库,用库来解决一系列的数据分析问题 去掉信息不全的用户 描述 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔): Nowcoder_ID:用户ID Level:等级 Achievement_value
-
基于MySQL到MongoDB简易对照表的详解
查询:MySQL:SELECT * FROM userMongo:db.user.find()MySQL:SELECT * FROM user WHERE name = 'starlee'Mongo:db.user.find({'name' : 'starlee'})插入:MySQL:INSERT INOT user (`name`, `age`) values ('starlee',25)Mongo:db.user.insert({'name' : 'starlee', 'age' : 25}
-
MongoDB 语法使用小结
他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型.Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引. 它的特点是高性能.易部署.易使用,存储数据非常方便. 1. MongoDB的获取和安装 (1)获取地址 http://www.mongodb.org/downloads 根据自己需要选择相应的版本,linux下可以使用wget 命令. (2)解压