一文解析ORACLE树结构查询
我们在日常程序设计中,经常会遇到树状结构的表示,例如组织机构、行政区划等等。这些在数据库中往往通过一张表进行展示。这里我们以一张简单的行政区划表为例进行展示,在实际使用过程中,可以为其添加其他描述字段以及层级。
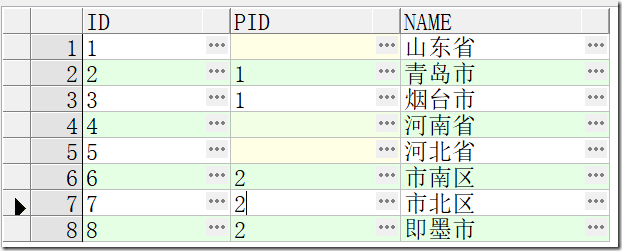
表中通过ID和PID关联,实现树状结构的存储。建表以及数据语句如下:
-- Create table create table TREETEST ( id NVARCHAR2(50), pid NVARCHAR2(50), name NVARCHAR2(50) )
insert into TREETEST (ID, PID, NAME) values ('1', null, '山东省');
insert into TREETEST (ID, PID, NAME) values ('2', '1', '青岛市');
insert into TREETEST (ID, PID, NAME) values ('3', '1', '烟台市');
insert into TREETEST (ID, PID, NAME) values ('4', null, '河南省');
insert into TREETEST (ID, PID, NAME) values ('5', null, '河北省');
insert into TREETEST (ID, PID, NAME) values ('6', '2', '市南区');
insert into TREETEST (ID, PID, NAME) values ('7', '2', '市北区');
insert into TREETEST (ID, PID, NAME) values ('8', '2', '即墨市');
那对于树状结构如何查询呢?Oracle提供递归查询的方式进行查询,基本语法如下:
SELECT [Column]….. FEOM [Table] WHERE Conditional1 START WITH Conditional2 CONNECT BY PRIOR Conditional3 ORDER BY [Column]
说明:
- 条件1---过滤条件,对全部返回的记录进行过滤。
- 条件2---根节点的限定条件,固然也可以放宽权限得到多个根节点,也就是获取多个树
- 条件3---链接条件,目的就是给出父子之间的关系是什么,根据这个关系进行递归查询(在上述表中就是ID=PID)
- 排序---对全部返回记录进行排序
下面我们结合具体实例来看:
1、查询山东省下面的所有子节点
SELECT * FROM TREETEST t START WITH t.PID=1 CONNECT BY PRIOR t.ID = t.PID
其中ID为1的为山东省节点,查询结果如下:

2、查询青岛市的下一级子节点(注意和上面区分,全部子节点和下一级子节点)

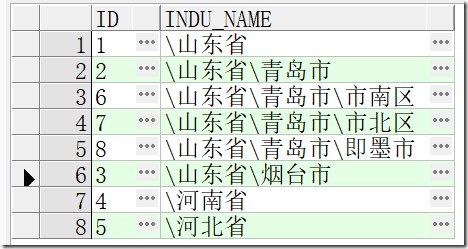
3、如果需要获取将山东省青岛市等连接起来显示,可以使用SYS_CONNECT_BY_PATH来实现
SELECT t.ID, SYS_CONNECT_BY_PATH(t.NAME, '\') AS INDU_NAME FROM TREETEST t START WITH t.PID IS NULL CONNECT BY PRIOR t.ID = t.PID
查询结果如下:
4、同理,也可以从下往上进行查询
SELECT * FROM TREETEST t START WITH t.ID=8 CONNECT BY t.ID = PRIOR t.PID

到此这篇关于一文解析ORACLE树结构查询的文章就介绍到这了,更多相关ORACLE树结构查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Oracle SQL树形结构查询
oracle中的select语句可以用START WITH...CONNECT BY PRIOR子句实现递归查询,connect by 是结构化查询中用到的,其基本语法是: 复制代码 代码如下: select * from tablename start with cond1 connect by cond2 where cond3; 简单说来是将一个树状结构存储在一张表里,比如一个表中存在两个字段: id,parentid那么通过表示每一条记录的parent是谁,就可以形成一个树状结构. 用上
-
Oracle递归树形结构查询功能
oracle树状结构查询即层次递归查询,是sql语句经常用到的,在实际开发中组织结构实现及其层次化实现功能也是经常遇到的. 概要:树状结构通常由根节点.父节点.子节点和叶节点组成,简单来说,一张表中存在两个字段,dept_id,par_dept_id,那么通过找到每一条记录的父级id即可形成一个树状结构,也就是par_dept_id(子)=dept_id(父),通俗的说就是这条记录的par_dept_id是另外一条记录也就是父级的dept_id,其树状结构层级查询的基本语法是: SELECT [
-

一文解析ORACLE树结构查询
我们在日常程序设计中,经常会遇到树状结构的表示,例如组织机构.行政区划等等.这些在数据库中往往通过一张表进行展示.这里我们以一张简单的行政区划表为例进行展示,在实际使用过程中,可以为其添加其他描述字段以及层级. 表中通过ID和PID关联,实现树状结构的存储.建表以及数据语句如下: -- Create table create table TREETEST ( id NVARCHAR2(50), pid NVARCHAR2(50), name NVARCHAR2(50) ) insert into
-
解析oracle对select加锁的方法以及锁的查询
解析oracle对select加锁的方法以及锁的查询一.oracle对select加锁方法 复制代码 代码如下: create table test(a number,b number);insert into test values(1,2);insert into test values(3,4);insert into test values(8,9);commit;---session 1 模拟选中一个号码SQL> select * from test where a =1 for up
-
解析Oracle 8i/9i的计划稳定性
正在看的ORACLE教程是:解析Oracle 8i/9i的计划稳定性.由Oralce8.1开始,Oracle增加了一个新的特性就是Stored Outlines,或者称为Plan Stability(计划稳定性).这个特性带来三个好处.首先,你可以优化开销很大的语句的处理.第二,如果有一些语句Oracle需要花费长时间来优化(而不是执行),你可以节省时间并且减少优化阶段的竞争.最后,它可以让你选择使用新的cursor_sharing参数而无需要担心因此而不采用优化的执行路径. 要知道如何使用存储
-
Python调用SQLPlus来操作和解析Oracle数据库的方法
先来看一个简单的利用python调用sqlplus来输出结果的例子: import os import sys from subprocess import Popen, PIPE sql = """ set linesize 400 col owner for a10 col object_name for a30 select owner, object_name from dba_objects where rownum<=10; ""&quo
-
Oracle分页查询的实例详解
Oracle分页查询的实例详解 1.Oracle分页查询: SELECT * FROM ( SELECT A.*, ROWNUM RN FROM (SELECT * FROM tab) A WHERE ROWNUM <= 40 ) WHERE RN >= 21; 这个分页比下面的执行时间少,效率高. 2. select * from (select c.*,rownum rn from tab c) where rn between 21 and 40 对比这两种写法,绝大多数的情况下,第一个
-
Oracle分页查询性能优化代码详解
对于数据库中表的数据的 Web 显示,如果没有展示顺序的需要,而且因为满足条件的记录如此之多,就不得不对数据进行分页处理.常常用户并不是对所有数据都感兴趣的,或者大部分情况下,他们只看前几页. 通常有以下两种分页技术可供选择. Select * from ( Select rownum rn,t.* from table t) Where rn>&minnum and rn<=&maxnum 或者 Select * from ( Select rownum rn,t.* fro
-
mysql、mssql及oracle分页查询方法详解
本文实例讲述了mysql.mssql及oracle分页查询方法.分享给大家供大家参考.具体分析如下: 分页查询在web开发中是最常见的一种技术,最近在通过查资料,有一点自己的心得 一.mysql中的分页查询 注: m=(pageNum-1)*pageSize;n= pageSize; pageNum是要查询的页码,pageSize是每次查询的数据量, 方法一: select * from table order by id limit m, n; 该语句的意思为,查询m+n条记录,去掉前m条,返
-
Oracle批量查询、删除、更新使用BULK COLLECT提高效率
BULK COLLECT(成批聚合类型)和数组集合type类型is table of 表%rowtype index by binary_integer用法笔记. 例1: 批量查询项目资金账户号为 "320001054663"的房屋账户信息并把它们打印出来 . DECLARE TYPE acct_table_type IS TABLE OF my_acct%ROWTYPE INDEX BY BINARY_INTEGER; v_acct_table acct_table_type; BE
-
用Oracle并行查询发挥多CPU的威力
正在看的ORACLE教程是:用Oracle并行查询发挥多CPU的威力.参数 让我们进一步看看CPU的数量是如何影响这些参数的. 参数fast_start_parallel_rollback Oracle并行机制中一个令人兴奋之处是在系统崩溃时调用并行回滚得能力.当Oracle数据库发生少有的崩溃时,Oracle能自动检测未完成的事务并回滚到起始状态.这被称为并行热启动,而Oracle使用基于cpu_count的fast_start_parallel_rollback参数来决定未完成事务的秉性程度
-
详解oracle分页查询的基础原理
本文从数据查询原理,以及分页实现的方法详细分析了oracle分页查询的基础知识,以下是本文内容: 原因一 oracle默认为每个表生成rowmun,rowid字段,这些字段我们称之为伪列 1 创建测试表 CREATE TABLE TEST( ID NUMBER, NAME VARCHAR2(20) ) 2 插入测试数据 INSERT INTO TEST VALUES (1,'张三'); INSERT INTO TEST VALUES (2,'李四'); INSERT INTO TEST VALU