C语言数据结构中树与森林专项详解
目录
- 树的存储结构
- 树的逻辑结构
- 双亲表示法(顺序存储)
- 孩字表示法(顺序+链式存储)
- 孩子兄弟表示法(链式存储)
- 森林
- 树的遍历
- 树的先根遍历(深度优先遍历)
- 树的后根遍历(树的深度优先遍历)
- 树的层序遍历(广度优先遍历)
- 森林的遍历
- 先序遍历森林
- 中序遍历森林
树的存储结构
树的逻辑结构
树是n(n≥0)个结点的有限集合,n=0时,称为空树,这是一种特殊情况。在任意--棵非空树中应满足:
1)有且仅有一个特定的称为根的结点。
2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集合T1,2....Tm,其中每个集合本身又是一-棵树,并且称为根结点的子树。
双亲表示法(顺序存储)
每个结点保存双亲的“指针”, 结点中保存父节点在数组的下标
优点:找父节点方便
缺点:找孩子不方便
删除元素方案一 ,数据删除后,parent 变为-1
删除元素方案二,数据删除后,将尾部数据填充到那
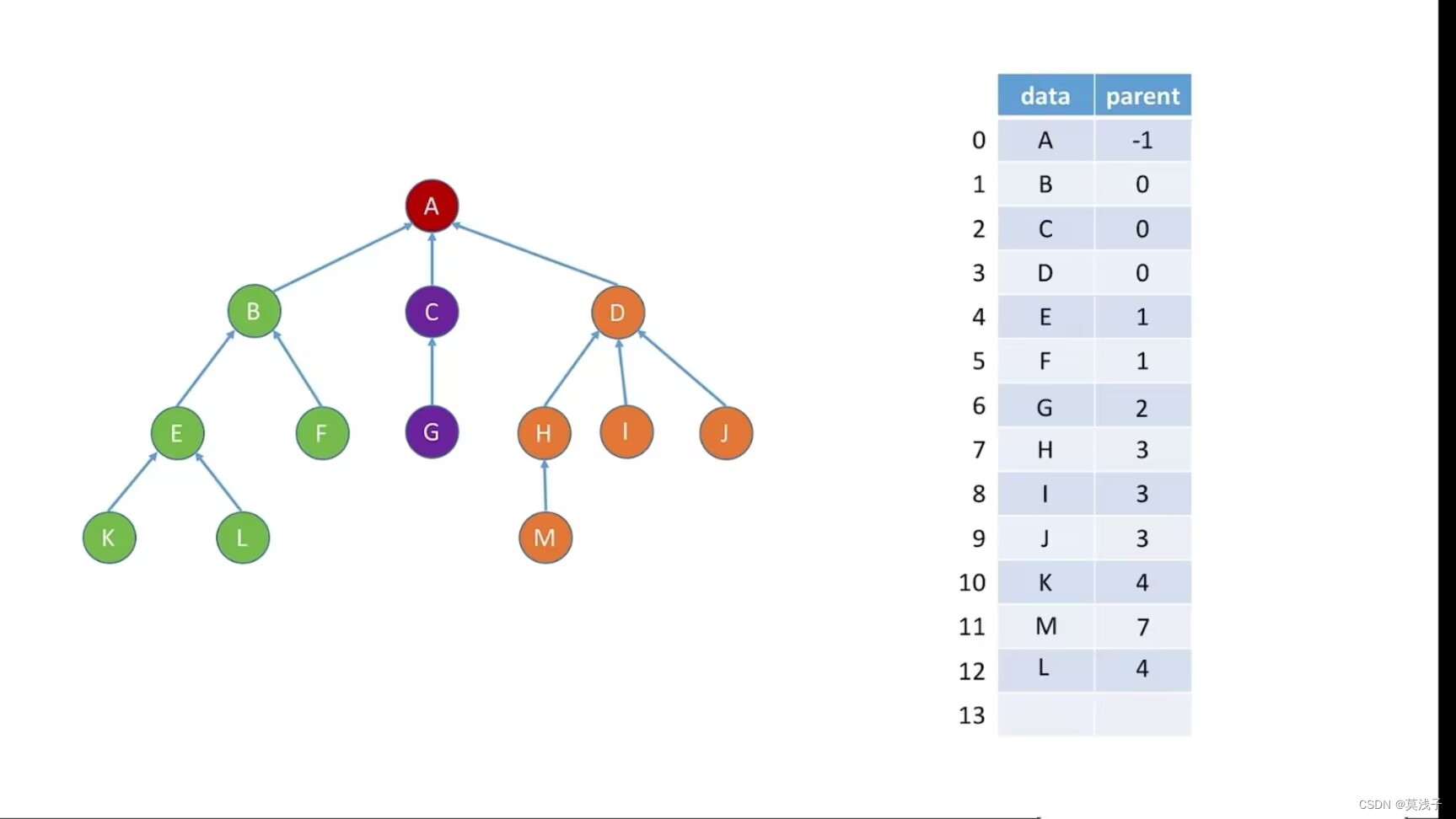
#define MAX_TREE_SIZE 100 //树中最多结点树
typedef struct{ //树的结点定义
Elemtype date; //数据元素
int parent; //双亲位置域
}PTNode;
typedef struct{ //树的类型定义
PTNode nodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点树
}PTree;
孩字表示法(顺序+链式存储)
顺序存储各个结点,每个结点保存孩子链表头指针
优点:找孩子方便
缺点:找双亲不方便

代码
#define MAX_TREE_SIZE 100 //树中最多结点树
typedef struct{ //树的结点定义
Elemtype date; //数据元素
int parent; //双亲位置域
}PTNode;
typedef struct{ //树的类型定义
PTNode nodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点树
}PTree;
struct CTNOde{
int child; //孩子结点在数组的位置
struct CTNode *next; //下一个孩子
}CTBox;
typedef struct {
CTBox nodes[MAX_TREE_SIZE];
int n,r; //结点树和根的位置
};
孩子兄弟表示法(链式存储)
优点:可以用二叉树的操作来处理树
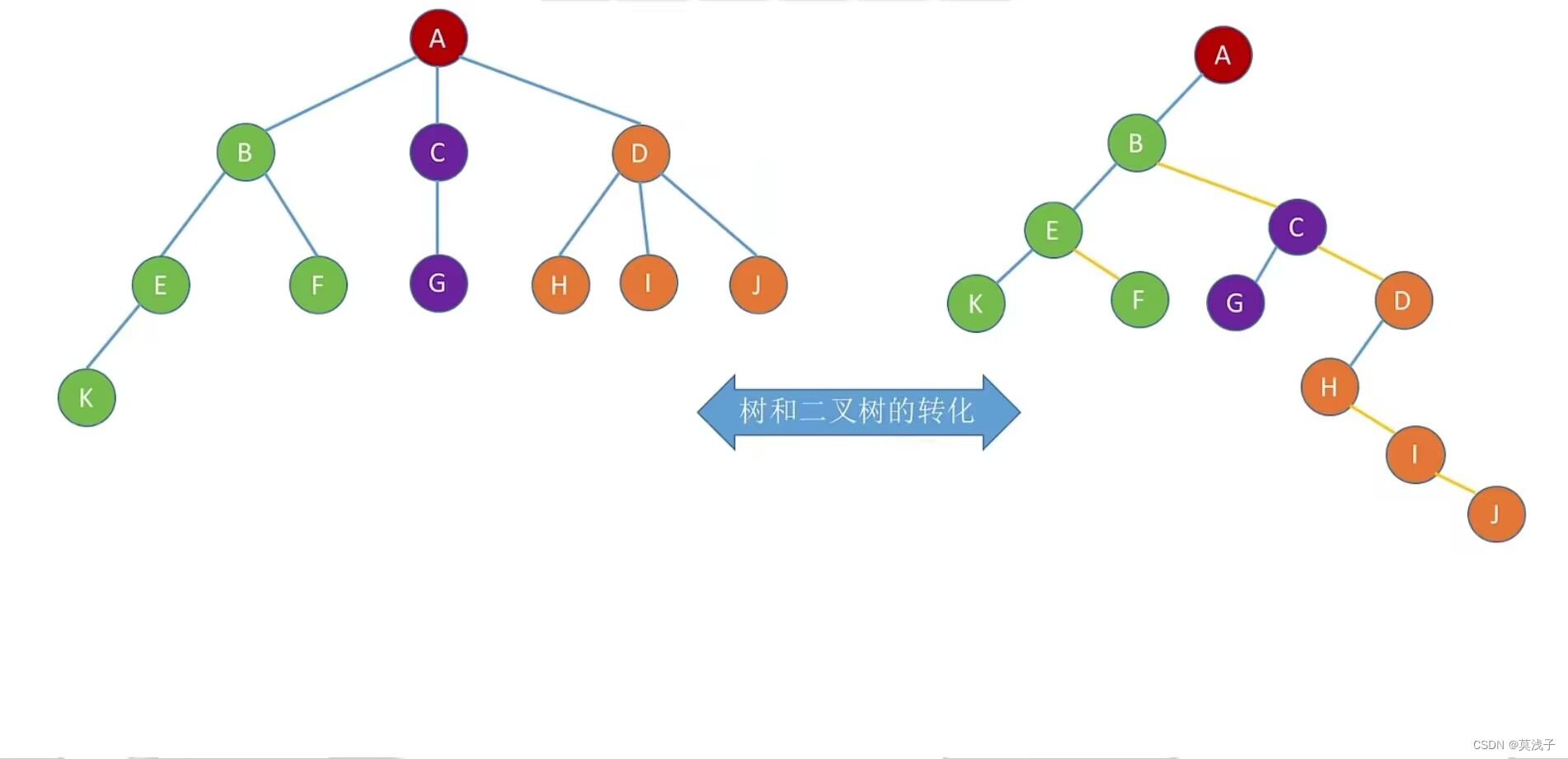
代码
//树的存储-孩子兄弟表示法
typedef struct CSDode{
Elemtype date; //数据域
struct CSDode *firstchild ,*nextsibling; //第一个孩子和右兄弟指针
}CSDode ,*CSTree;
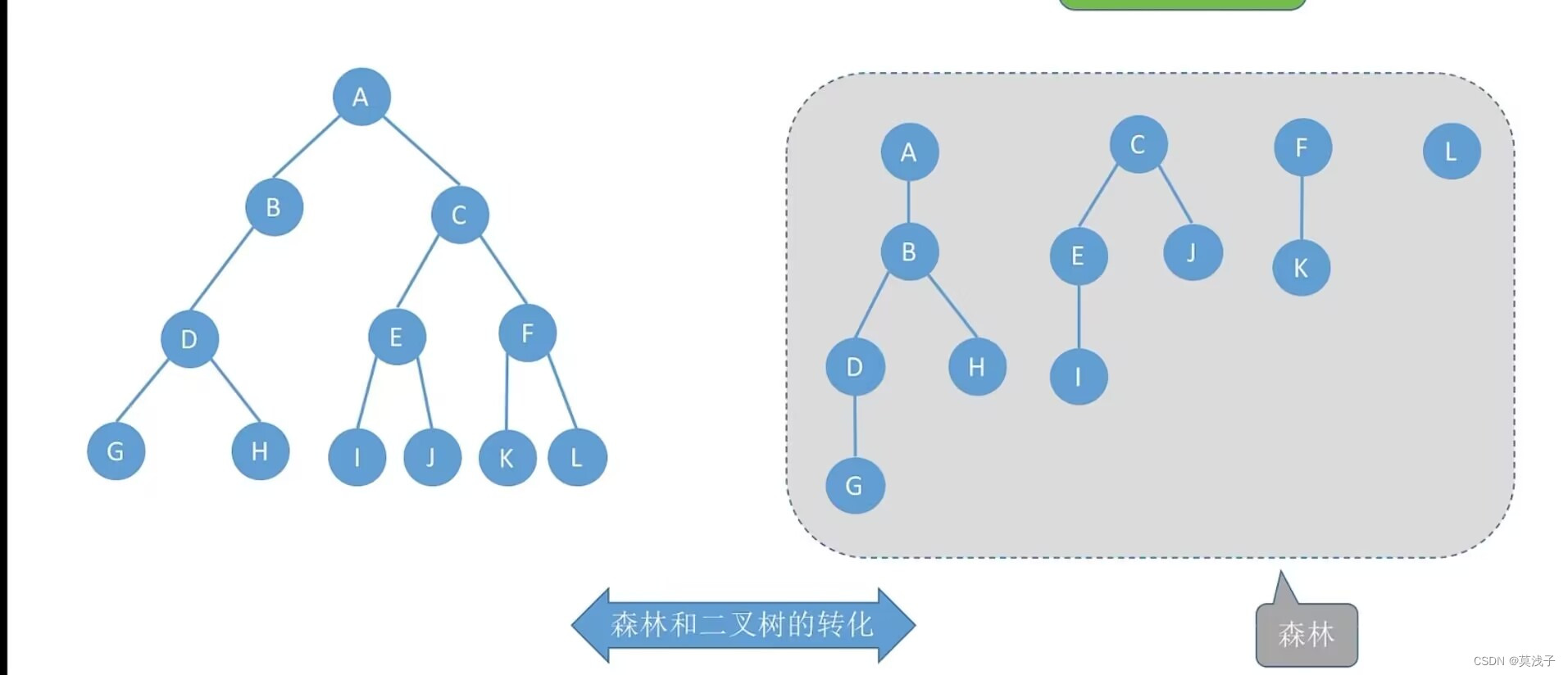
森林
森林是m(m>=0)棵互不相交的树集合
森林中各个树的根结点之间是为兄弟关系
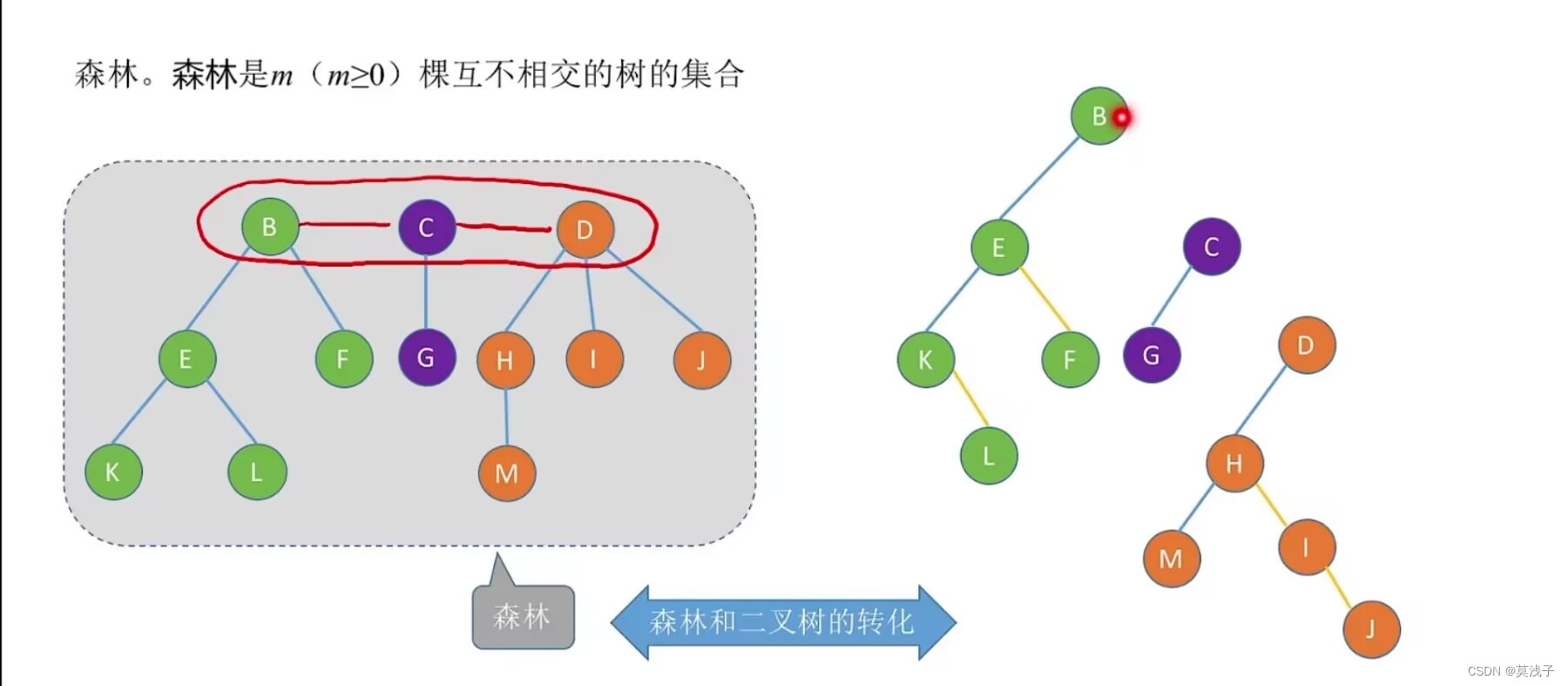
在二叉树中,如果是兄弟关系就在右边,如果是孩子就在左边,本质上,用二叉链表存储森林
树的遍历
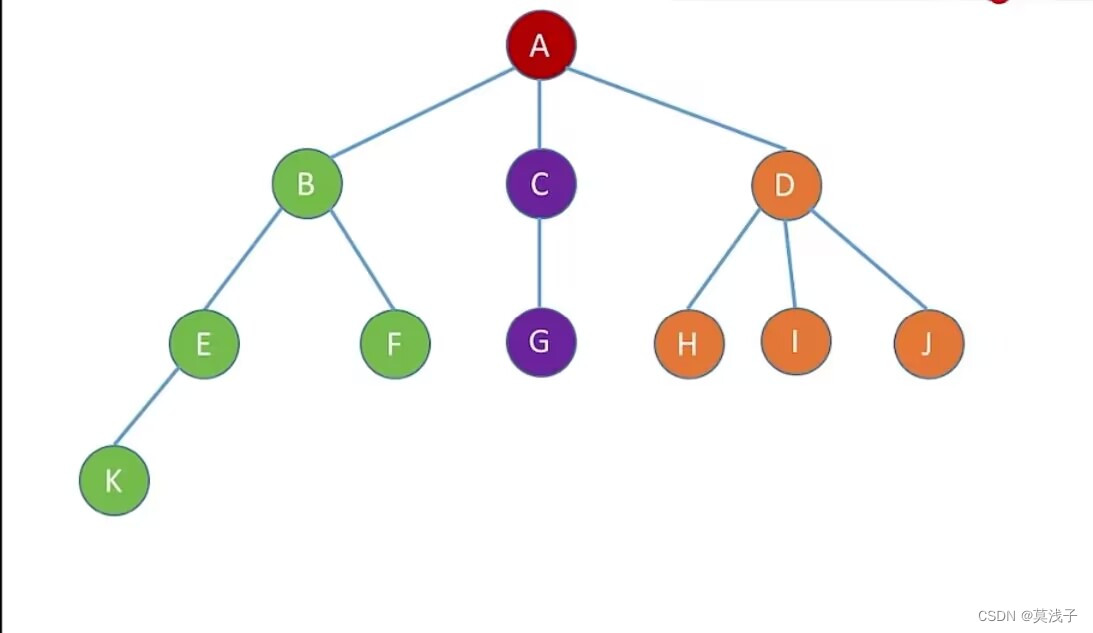
树的先根遍历(深度优先遍历)
先根遍历。若树非空,先访问根结点,在依次对没棵子树进行先根遍历。
上图这样一棵树的先根遍历顺序和二叉树的很像,按照二叉树的方法

//树的先根遍历
void PreOrder(TreeNode *R){
if(R!=NULL){
visit(R); //访问根结点
while(R还有下一个子树T)
PreOrder(T); //先根遍历下一棵子树
}
}
树的后根遍历(树的深度优先遍历)
若树非空,先依次对没棵子树进行后根遍历,最后在访问根结点
上图这样一棵树的后根遍历顺序和二叉树的很像,按照二叉树的方法

代码
//树的后根遍历
void PostOrder(TReeNode *R)
{
if(R != NULL){
while(R还有下一个子树T)
PodtOrder(T); //后根遍历下一棵子树
visit(R) //访问根结点
}
}
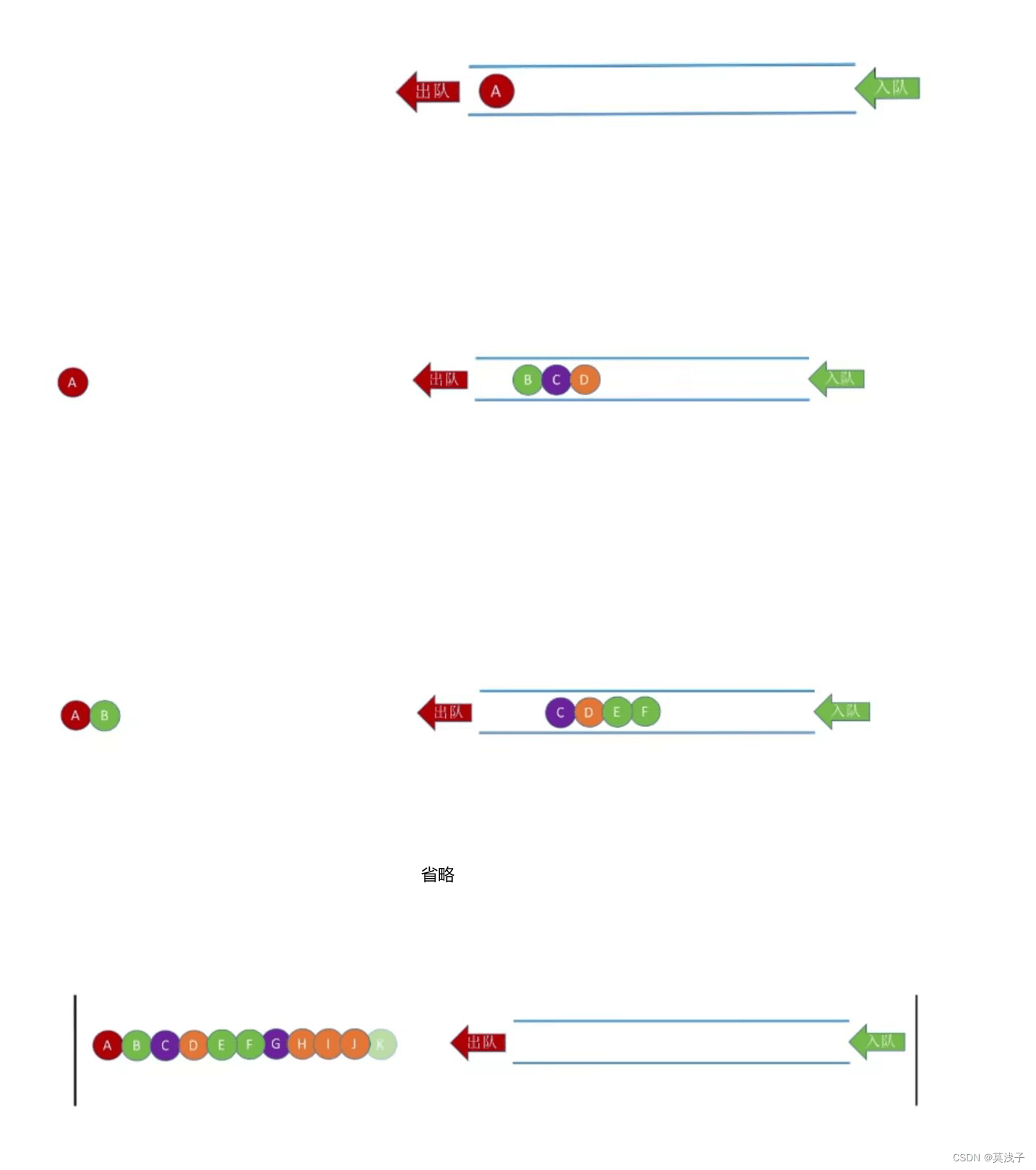
树的层序遍历(广度优先遍历)
层次遍历(用队列实现)
①若树非空,则根节点入队
②若队列非空,队头元素出队并访问,同时将该元素的孩子依次入队
③重复②直到队列为空
如图
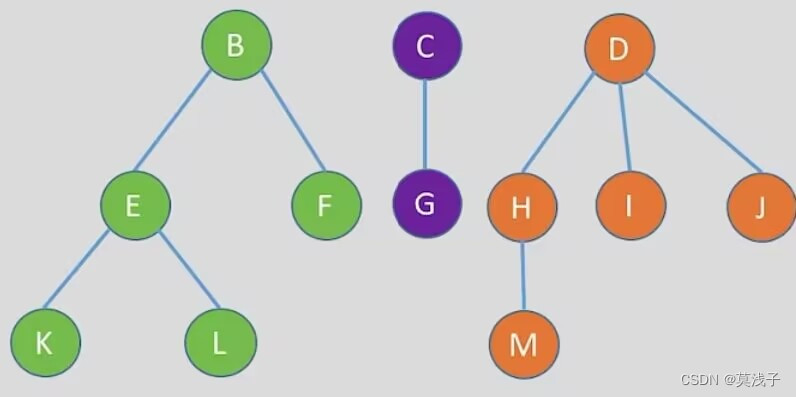
森林的遍历
森林。森林是m (m>0)棵互不相交的树的集合。每棵树去掉根节点后,其各个子树又组成森林。
先序遍历森林
效果等同于依次对各二叉树进行先序遍历
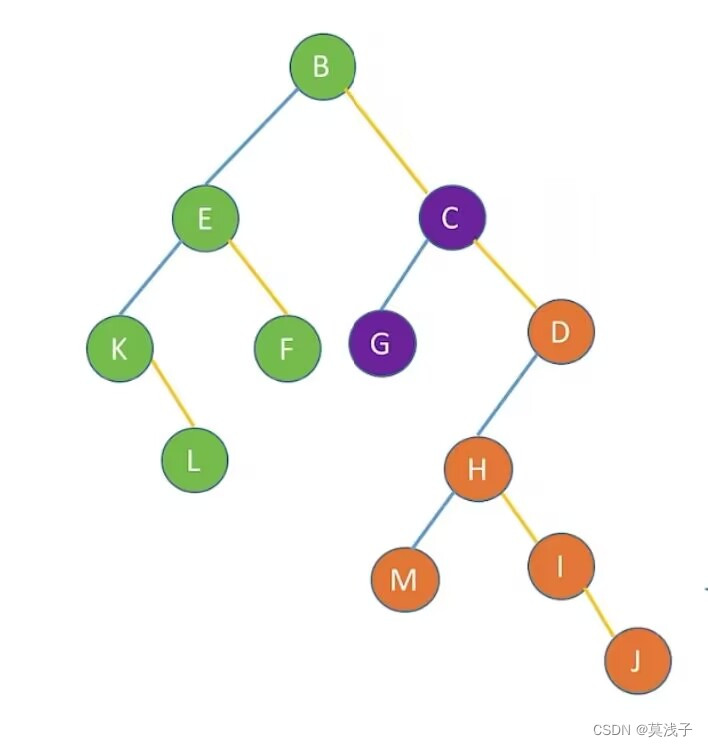
若森林为非空,则按如下规则进行遍历:
1.访问森林中第一棵树的根结点
2.先序遍历第一棵树中根结点的子树森林。
3.先序遍历除去第一棵树之后剩余的树构成的森林。
效果如下

中序遍历森林
效果等同于依次对二叉树进行中序遍历
若森林为非空,则按如下规则进行遍历:
中序遍历森林中第一棵树的根结点的子树森林。
访问第一棵树的根结点。
中序遍历除去第一棵树之后剩余的树构成的森林。
效果如下
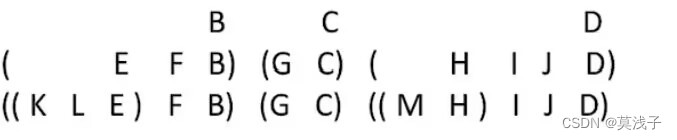
到此这篇关于C语言数据结构中树与森林专项详解的文章就介绍到这了,更多相关C语言树与森林内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言实例实现二叉搜索树详解
目录 有些算法题里有了这个概念,因为不知道这是什么蒙圈了很久. 先序遍历: root——>left——>right 中序遍历: left—— root ——>right 后序遍历 :left ——right——>root 先弄一个只有四个节点的小型二叉树,实际上这种小型二叉树应用不大. 二叉树的真正应用是二叉搜索树,处理海量的数据. 代码很简单,两种遍历的代码也差不多 #include<stdio.h> #include<stdlib.h> typedef
-

C语言线索二叉树基础解读
目录 线索二叉树的意义 线索二叉树的定义 线索二叉树结构的实现 二叉树的线索存储结构 二叉树的中序线索化 线索二叉树的中序遍历 总结 线索二叉树的意义 对于一个有n个节点的二叉树,每个节点有指向左右孩子的指针域.其中会出现n+ 1个空指针域,这些空间不储存任何事物,浪费着内存的资源. 对于一些需要频繁进行二叉树遍历操作的场合,二叉树的非递归遍历操作过程相对比较复杂,递归遍历虽然简单明了,但是会有额外的开销,对于操作的时间和空间都比较浪费. 我们可以考虑利用这些空地址,存放指向节点在某种遍历次序下
-
C语言二叉树的概念结构详解
目录 1.树的概念及结构(了解) 1.1树的概念: 1.2树的表示法: 2.二叉树的概念及结构 2.1二叉树的概念 2.2特殊的二叉树 2.2二叉树的性质 2.3二叉树的顺序存储 2.4二叉树的链式存储 3.二叉树链式结构的实现 3.1二叉树的前中后序遍历 3.2求二叉树的节点个数 3.3求二叉树的叶子节点个数 3.4销毁二叉树 1.树的概念及结构(了解) 1.1树的概念: 树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合.把它叫做树是因为它看起来像一棵倒挂的树
-
C语言树与二叉树基础全刨析
目录 一.树的概念和结构 1.1 树的概念 1.2 树的结构 & 相关名词解释 1.3 树的表示 1.4 树的应用 二.二叉树的概念 & 存储结构(重要) 2.1 二叉树的概念 2.2 特殊的二叉树 2.3 二叉树的性质 2.4 二叉树的存储结构 一.树的概念和结构 1.1 树的概念 树是一种非线性的数据结构,它是由 n(n>=0)个有限结点组成一个具有层次关系的集合.把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的. 有一个特殊的结点,称为根结点,根节点没有前
-
C语言数据结构中树与森林专项详解
目录 树的存储结构 树的逻辑结构 双亲表示法(顺序存储) 孩字表示法(顺序+链式存储) 孩子兄弟表示法(链式存储) 森林 树的遍历 树的先根遍历(深度优先遍历) 树的后根遍历(树的深度优先遍历) 树的层序遍历(广度优先遍历) 森林的遍历 先序遍历森林 中序遍历森林 树的存储结构 树的逻辑结构 树是n(n≥0)个结点的有限集合,n=0时,称为空树,这是一种特殊情况.在任意--棵非空树中应满足: 1)有且仅有一个特定的称为根的结点. 2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集合T
-
C语言数据在内存中的存储详解
目录 文章摘要 一.C语言的数据类型 数据类型基本分为: 二.隐式类型转换 1.什么是隐式类型转换 2.整型提升 3.类型转换 三.机器大小端 1.什么是大小端 2.大小端在截断的应用 3.判断当前机器的字节序是大端还是小端 四.整型在内存中的存储 1.原码.反码.补码 2.举例实践整型数据在内存的存储 总结 文章摘要 本文通过内存底层原理,帮你透彻了解数据存储进内存与从内存中读取的区别以及不同数据类型下数据计算.赋值的变化情况 要透彻理解这些,必须知道隐式类型转换以及机器大小端的概念,本文会对
-
C语言数据结构中约瑟夫环问题探究
目录 问题描述 基本要求 测试数据 实现思路1 实现思路2 结果 数据结构开讲啦!!! 本专栏包括: 抽象数据类型 线性表及其应用 栈和队列及其应用 串及其应用 数组和广义表 树.图及其应用 存储管理.查找和排序 将从简单的抽象数据类型出发,深入浅出地讲解复数 到第二讲线性表及其应用中会讲解,运动会分数统计,约瑟夫环,集合的并.交和差运算,一元稀疏多项式计算器 到最后一步一步学会利用数据结构和算法知识独立完成校园导航咨询的程序. 希望我们在学习的过程中一起见证彼此的成长. 问题描述 约瑟夫环问题
-
C语言数据结构中二分查找递归非递归实现并分析
C语言数据结构中二分查找递归非递归实现并分析 前言: 二分查找在有序数列的查找过程中算法复杂度低,并且效率很高.因此较为受我们追捧.其实二分查找算法,是一个很经典的算法.但是呢,又容易写错.因为总是考虑不全边界问题. 用非递归简单分析一下,在编写过程中,如果编写的是以下的代码: #include<iostream> #include<assert.h> using namespace std; int binaty_search(int* arr, size_t n, int x)
-
C语言 数据结构中求解迷宫问题实现方法
C语言 数据结构中求解迷宫问题实现方法 在学习数据结构栈的这一节遇到了求迷宫这个问题,拿来分享一下~ 首先求迷宫问题通常用的是"穷举求解" 即从入口出发,顺某一方向试探,若能走通,则继续往前走,否则原路返回,换另一个方向继续试探,直至走出去. 我们可以先建立一个8*8的迷宫其中最外侧为1的是墙 int mg[M+2][N+2]={ {1,1,1,1,1,1,1,1,1,1}, {1,0,0,1,0,0,0,1,0,1}, {1,0,0,1,0,0,0,1,0,1}, {1,0,0,0,
-
C语言数据结构中串的模式匹配
C语言数据结构中串的模式匹配 串的模式匹配问题:朴素算法与KMP算法 #include<stdio.h> #include<string.h> int Index(char *S,char *T,int pos){ //返回字串T在主串S中第pos个字符之后的位置.若不存在,则函数值为0. //其中,T非空,1<=pos<=StrLength(s). int i=pos; int j=1; while(i<=S[0]&&j<=T[0]){ i
-
C语言数据结构中数制转换实例代码
C语言数据结构中数制转换实例代码 数制转换是严蔚敏的数据结构那本书中的例子,但是那本书中的例子大都是用伪代码的形式写的,不是很容易理解和实现,对初学者造成了不小的困扰,在这里我们将其详尽的实现出来,以便初学者调试和运行,并从中有所收获. #include <stdlib.h> #include <stdio.h> #include<malloc.h> #define STACK_INIT_SIZE 10 //定义最初申请的内存的大小 #define STACK_INCR
-
C语言数据结构中堆排序的分析总结
目录 一.本章重点 二.堆 2.1堆的介绍(三点) 2.2向上调整 2.3向下调整 2.4建堆(两种方式) 三.堆排序 一.本章重点 堆 向上调整 向下调整 堆排序 二.堆 2.1堆的介绍(三点) 1.物理结构是数组 2.逻辑结构是完全二叉树 3.大堆:所有的父亲节点都大于等于孩子节点,小堆:所有的父亲节点都小于等于孩子节点. 2.2向上调整 概念:有一个小/大堆,在数组最后插入一个元素,通过向上调整,使得该堆还是小/大堆. 使用条件:数组前n-1个元素构成一个堆. 以大堆为例: 逻辑实现: 将
-
C语言关键字auto与register及static专项详解
目录 1.auto 2.register 3.static 1.auto 在解释 auto 之前,先来了解一下什么是局部变量. 在很多印象中,对局部变量的描述是:函数内定义的变量称为局部变量.并且下面这段代码也很好的解释了这句话: #include <stdio.h> void print() { int a = 10; printf("%d", a); } int main() { print(); printf("%d", a); return 0;
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<