利用Python2下载单张图片与爬取网页图片实例代码
前言
一直想好好学习一下Python爬虫,之前断断续续的把Python基础学了一下,悲剧的是学的没有忘的快。只能再次拿出来滤了一遍,趁热打铁,通过实例来实践下,下面这篇文章主要介绍了关于Python2下载单张图片与爬取网页的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。
一、需求分析
1、知道图片的url地址,将图片下载到本地。
2、知道网页地址,将图片列表中的图片全部下载到本地。
二、准备工作
1、开发系统:win7 64位。
2、开发环境:python2.7。
3、开发工具:PyCharm。
4、浏览器:Chrome。
三、操作步骤
A.知道图片的url地址,将图片下载到本地。
a1、打开Chrome,随意找到一个图片网站。
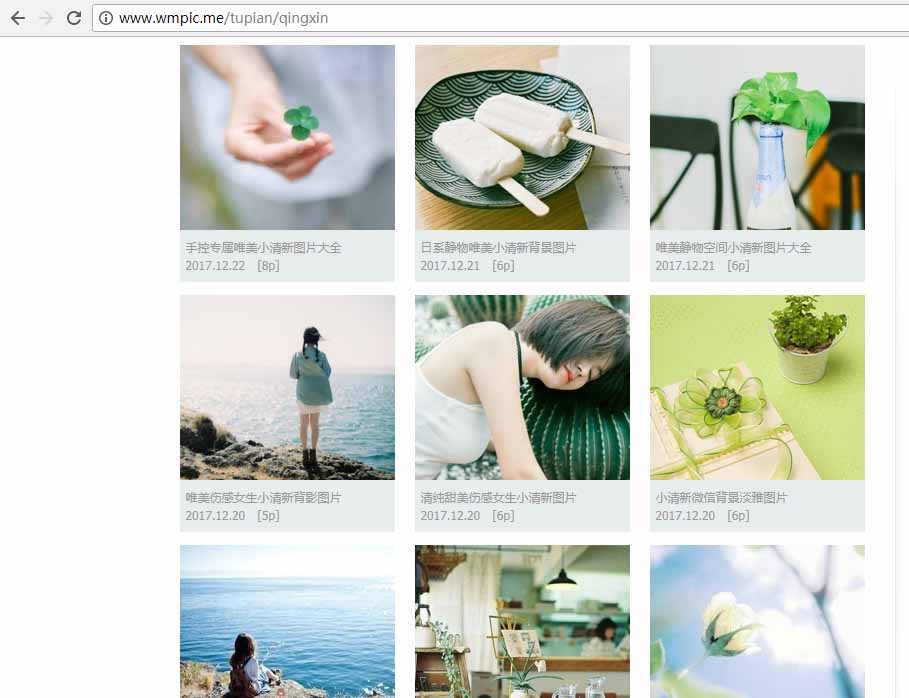
a2、打开开发者工具(f12键或者fn+f12键),选择第一张图片,可以看到它的src属性就是图片的地址,复制出来。

a3、编写代码。这里需要引用urllib库以及使用Python IO相关的知识。
# -*- coding:utf-8 -* ''' 知道图片地址,下载图片到本地 ''' import urllib #图片url地址 url = 'http://p1.wmpic.me/article/2017/12/22/1513930326_ciDepIns_215x185.jpg' #方法一 #获取图片数据 res = urllib.urlopen(url).read() #文件要保存的路径名和文件名 path = "e:\dlimg\pic2.jpg" #使用io写入图片 f = open(path , "wb") f.write(res) f.close() #方法二 res2 = urllib.urlretrieve(url , 'e:\dlimg\pic3.jpg')
B.知道网页地址,将图片列表中的图片全部下载到本地。
b1、还是以上面的网页为爬取对象,在该网页下,图片列表中有30张照片,获取每张图片的src属性值,再来下载即可。
b2、利用BeautifulSoup解析网页,利用标签选择器获取每张图片的src属性值。
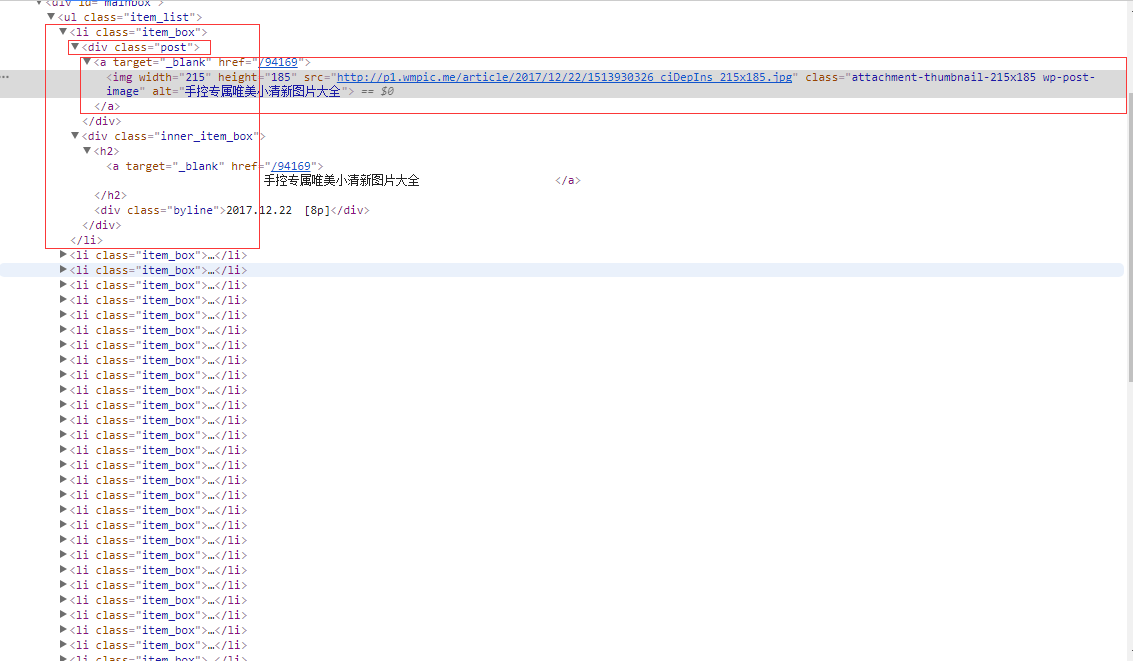
b3、编写代码。
# -*- coding: utf-8 -*-
import requests
import urllib
from bs4 import BeautifulSoup
url = 'http://www.wmpic.me/tupian/qingxin'
res = requests.get(url)
#使用BeautifulSoup解析网页
soup = BeautifulSoup(res.text , 'html.parser')
#通过标签选择器定位到图片位置(与css选择器差不多)
pic_list = soup.select('.item_box .post a img')
i = 0
for img_url in pic_list:
#获取每个img标签的src属性
url_list = img_url['src']
#保存路径,后面是文件名
save_path = 'E:\dlimg\\'+'downloadpic_'+str(i)+'.jpg'
#解析图片,写入到本地
pic_file = urllib.urlopen(url_list).read()
f = open(save_path, "wb")
f.write(pic_file)
f.close()
i = i+1
C.运行结果(红色框中pic2.jpg和pic3.jpg是A步骤运行结果,其余以downloadpic_*.jpg命名的图片是步骤B的运行结果)

总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
Python下载指定页面上图片的方法
本文实例讲述了Python下载指定页面上图片的方法.分享给大家供大家参考,具体如下: #!/usr/bin/python #coding:utf8 import re import urllib def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getImg(html): reg = r'src="(.*?\.jpg)" ' imgre = re.compile(reg) im
-
Python获取网页上图片下载地址的方法
本文实例讲述了Python获取网页上图片下载地址的方法.分享给大家供大家参考.具体如下: 这里获取网页上图片的下载地址是正在写的数据采集中的一段,代码如下: 复制代码 代码如下: #!/user/bin/python3 import urllib2 from HTMLParser import HTMLParser class MyHtmlParser(HTMLParser): links = [] def handle_starttag(self, tag, attrs):
-

Python爬取网页中的图片(搜狗图片)详解
前言 最近几天,研究了一下一直很好奇的爬虫算法.这里写一下最近几天的点点心得.下面进入正文: 你可能需要的工作环境: Python 3.6官网下载 本地下载 我们这里以sogou作为爬取的对象. 首先我们进入搜狗图片http://pic.sogou.com/,进入壁纸分类(当然只是个例子Q_Q),因为如果需要爬取某网站资料,那么就要初步的了解它- 进去后就是这个啦,然后F12进入开发人员选项,笔者用的是Chrome. 右键图片>>检查 发现我们需要的图片src是在img标签下的,于是先试着用
-
python实现下载指定网址所有图片的方法
本文实例讲述了python实现下载指定网址所有图片的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 #download pictures of the url #useage: python downpicture.py www.baidu.com import os import sys from html.parser import HTMLParser from urllib.request import urlopen from urllib.parse im
-
python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页.我使用的是学信网,好了,网站截图如下: 网站的代码如下: <form method="get" name="form1" id="form1" action="/cet/query"> <table border=&qu
-
python批量下载图片的三种方法
有三种方法,一是用微软提供的扩展库win32com来操作IE,二是用selenium的webdriver,三是用python自带的HTMLParser解析.win32com可以获得类似js里面的document对象,但貌似是只读的(文档都没找到).selenium则提供了Chrome,IE,FireFox等的支持,每种浏览器都有execute_script和find_element_by_xx方法,可以方便的执行js脚本(包括修改元素)和读取html里面的元素.不足是selenium只提供对py
-
浅谈Python爬取网页的编码处理
背景 中秋的时候,一个朋友给我发了一封邮件,说他在爬链家的时候,发现网页返回的代码都是乱码,让我帮他参谋参谋(中秋加班,真是敬业= =!),其实这个问题我很早就遇到过,之前在爬小说的时候稍微看了一下,不过没当回事,其实这个问题就是对编码的理解不到位导致的. 问题 很普通的一个爬虫代码,代码是这样的: # ecoding=utf-8 import re import requests import sys reload(sys) sys.setdefaultencoding('utf8') url
-
python实现爬虫下载美女图片
本次爬取的贴吧是百度的美女吧,给广大男同胞们一些激励 在爬取之前需要在浏览器先登录百度贴吧的帐号,各位也可以在代码中使用post提交或者加入cookie 爬行地址:http://tieba.baidu.com/f?kw=%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0 #-*- coding:utf-8 -*- import urllib2 import re import requests from lxml import etree 这些是要导入的库,代码并没有使用正则
-
Python实现批量下载图片的方法
本文实例讲述了Python实现批量下载图片的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/env python #-*-coding:utf-8-*-' #Filename:download_file.py import os,sys import re import urllib import urllib2 base_url = 'xxx' array_url = list() pic_url = list() inner_url = list() def get_a
-
python在多玩图片上下载妹子图的实现代码
复制代码 代码如下: # -*- coding:utf-8 -*-import httplibimport urllibimport stringimport redef getContent(): #从网站中获取所有内容 conn = httplib.HTTPConnection("tu.duowan.com") conn.request("GET", "/m/meinv/index.html") r = c