Python基于BeautifulSoup和requests实现的爬虫功能示例
本文实例讲述了Python基于BeautifulSoup和requests实现的爬虫功能。分享给大家供大家参考,具体如下:
爬取的目标网页:http://www.qianlima.com/zb/area_305/
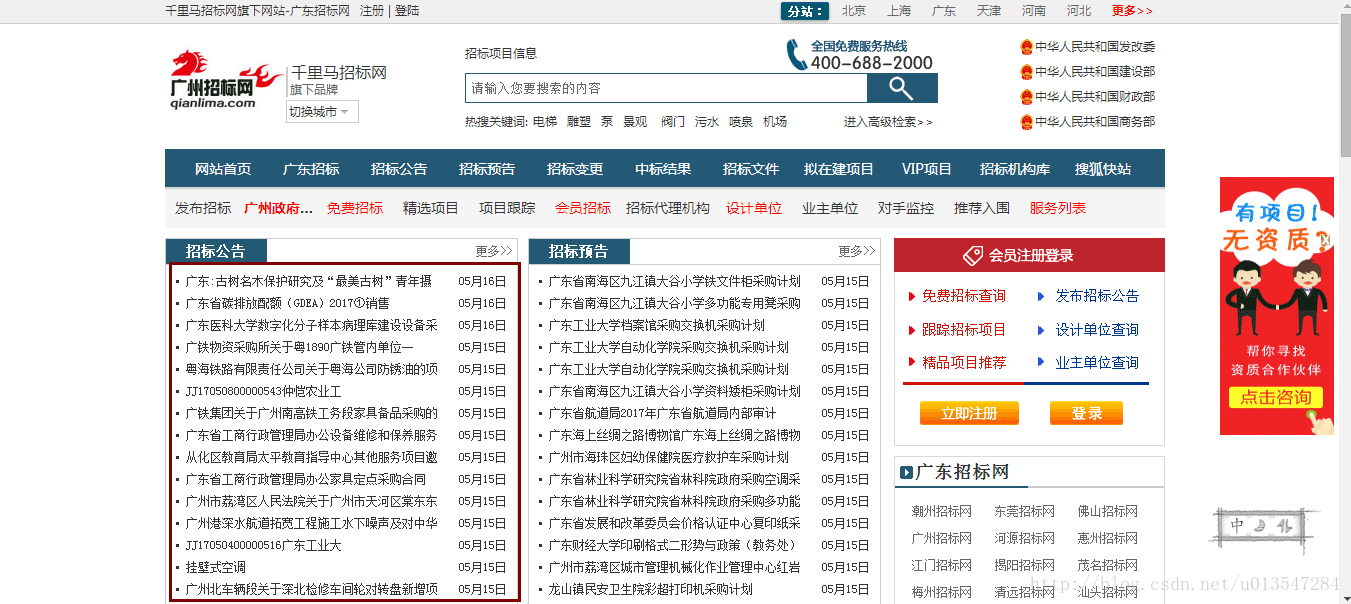
这是一个招投标网站,我们使用python脚本爬取红框中的信息,包括链接网址、链接名称、时间等三项内容。
使用到的Python库:BeautifulSoup、requests
代码如下:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
url = 'http://www.qianlima.com/zb/area_305/'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
headers = { 'User-Agent' : user_agent}
r = requests.get(url,headers=headers)#连接
content = r.text#获取内容,自动转码unicode
soup = BeautifulSoup(content,"lxml")
tags1 = soup.select('div .shixian_zhaobiao')
tag1 = tags1[0]
tag2 = tag1.find(name = 'dl')
tags2 = tag2.find_all(name = 'a')
tags3 = tag2.find_all(name = 'dd')
for tag in tags2:
print tag.get('href')
print tag.string
print tag.next_element.next_element.string
运行结果如下

更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
python用BeautifulSoup库简单爬虫实例分析
会用到的功能的简单介绍 1.from bs4 import BeautifulSoup #导入库 2.请求头herders headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36','referer':"www.mmjpg.com" } all_url = 'http://ww
-
python爬虫之BeautifulSoup 使用select方法详解
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家.具体如下: <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
Python HTML解析器BeautifulSoup用法实例详解【爬虫解析器】
本文实例讲述了Python HTML解析器BeautifulSoup用法.分享给大家供大家参考,具体如下: BeautifulSoup简介 我们知道,Python拥有出色的内置HTML解析器模块--HTMLParser,然而还有一个功能更为强大的HTML或XML解析工具--BeautifulSoup(美味的汤),它是一个第三方库.简单来说,BeautifulSoup最主要的功能是从网页抓取数据.本文我们来感受一下BeautifulSoup的优雅而强大的功能吧! BeautifulSoup安装 B
-
python3第三方爬虫库BeautifulSoup4安装教程
Python3安装第三方爬虫库BeautifulSoup4,供大家参考,具体内容如下 在做Python3爬虫练习时,从网上找到了一段代码如下: #使用第三方库BeautifulSoup,用于从html或xml中提取数据 from bs4 import BeautifulSoup 自己实践后,发现出现了错误,如下所示: 以上错误提示是说没有发现名为"bs4"的模块.即"bs4"模块未安装. 进入Python安装目录,以作者IDE为例, 控制台提示第三
-
Python爬虫包BeautifulSoup简介与安装(一)
先发官方文档的地址:官方文档 学习使用的书籍是Python网络数据采集(Ryan Mitchell著),大约是一些笔记的整理. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beauti
-

python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
Python爬虫beautifulsoup4常用的解析方法总结
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方法做个总结,方便查阅. 装载html文档 使用beautifulsoup的第一步是把html文档装载到beautifulsoup中,使其形成一个beautifulsoup对象. import requests from bs4 import BeautifulSoup url = "http://new.qq.com/o
-
Python使用requests及BeautifulSoup构建爬虫实例代码
本文研究的主要是Python使用requests及BeautifulSoup构建一个网络爬虫,具体步骤如下. 功能说明 在Python下面可使用requests模块请求某个url获取响应的html文件,接着使用BeautifulSoup解析某个html. 案例 假设我要http://maoyan.com/board/4猫眼电影的top100电影的相关信息,如下截图: 获取电影的标题及url. 安装requests和BeautifulSoup 使用pip工具安装这两个工具. pip install
-
python利用beautifulSoup实现爬虫
以前讲过利用phantomjs做爬虫抓网页 http://www.jb51.net/article/55789.htm 是配合选择器做的 利用 beautifulSoup(文档 :http://www.crummy.com/software/BeautifulSoup/bs4/doc/)这个python模块,可以很轻松的抓取网页内容 # coding=utf-8 import urllib from bs4 import BeautifulSoup url ='http://www.baidu.
-
Python爬虫包 BeautifulSoup 递归抓取实例详解
Python爬虫包 BeautifulSoup 递归抓取实例详解 概要: 爬虫的主要目的就是为了沿着网络抓取需要的内容.它们的本质是一种递归的过程.它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程. 让我们以维基百科为一个例子. 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来. # -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10: