Python实现多线程HTTP下载器示例
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件。
环境:windows/Linux + Python2.7.x
单线程
在介绍多线程之前首先介绍单线程。编写单线程的思路为:
1.解析url;
2.连接web服务器;
3.构造http请求包;
4.下载文件。
接下来通过代码进行说明。
解析url
通过用户输入url进行解析。如果解析的路径为空,则赋值为'/';如果端口号为空,则赋值为"80”;下载文件的文件名可根据用户的意愿进行更改(输入'y'表示更改,输入其它表示不需要更改)。
下面列出几个解析函数:
#解析host和path
def analyHostAndPath(totalUrl):
protocol,s1 = urllib.splittype(totalUrl)
host, path = urllib.splithost(s1)
if path == '':
path = '/'
return host, path
#解析port
def analysisPort(host):
host, port = urllib.splitport(host)
if port is None:
return 80
return port
#解析filename
def analysisFilename(path):
filename = path.split('/')[-1]
if '.' not in filename:
return None
return filename
连接web服务器
使用socket模块,根据解析url得到的host和port连接web服务器,代码如下:
import socket from analysisUrl import port,host ip = socket.gethostbyname(host) s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect((ip, port)) print "success connected webServer!!"
构造http请求包
根据解析url得到的path, host, port构造一个HTTP请求包。
from analysisUrl import path, host, port packet = 'GET ' + path + ' HTTP/1.1\r\nHost: ' + host + '\r\n\r\n'
下载文件
根据构造的http请求包,向服务器发送文件,抓取响应报文头部的"Content-Length"。
def getLength(self):
s.send(packet)
print "send success!"
buf = s.recv(1024)
print buf
p = re.compile(r'Content-Length: (\d*)')
length = int(p.findall(buf)[0])
return length, buf
下载文件并计算下载所用的时间。
def download(self):
file = open(self.filename,'wb')
length,buf = self.getLength()
packetIndex = buf.index('\r\n\r\n')
buf = buf[packetIndex+4:]
file.write(buf)
sum = len(buf)
while 1:
buf = s.recv(1024)
file.write(buf)
sum = sum + len(buf)
if sum >= length:
break
print "Success!!"
if __name__ == "__main__":
start = time.time()
down = downloader()
down.download()
end = time.time()
print "The time spent on this program is %f s"%(end - start)
多线程
抓取响应报文头部的"Content-Length"字段,结合线程个数,加锁分段下载。与单线程的不同,这里将所有代码整合为一个文件,代码中使用更多的Python自带模块。
得到"Content-Length":
def getLength(self):
opener = urllib2.build_opener()
req = opener.open(self.url)
meta = req.info()
length = int(meta.getheaders("Content-Length")[0])
return length
根据得到的Length,结合线程个数划分范围:
def get_range(self):
ranges = []
length = self.getLength()
offset = int(int(length) / self.threadNum)
for i in range(self.threadNum):
if i == (self.threadNum - 1):
ranges.append((i*offset,''))
else:
ranges.append((i*offset,(i+1)*offset))
return ranges
实现多线程下载,在向文件写入内容时,向线程加锁,并使用with lock代替lock.acquire( )...lock.release( );使用file.seek( )设置文件偏移地址,保证写入文件的准确性。
def downloadThread(self,start,end):
req = urllib2.Request(self.url)
req.headers['Range'] = 'bytes=%s-%s' % (start, end)
f = urllib2.urlopen(req)
offset = start
buffer = 1024
while 1:
block = f.read(buffer)
if not block:
break
with lock:
self.file.seek(offset)
self.file.write(block)
offset = offset + len(block)
def download(self):
filename = self.getFilename()
self.file = open(filename, 'wb')
thread_list = []
n = 1
for ran in self.get_range():
start, end = ran
print 'starting:%d thread '% n
n += 1
thread = threading.Thread(target=self.downloadThread,args=(start,end))
thread.start()
thread_list.append(thread)
for i in thread_list:
i.join()
print 'Download %s Success!'%(self.file)
self.file.close()
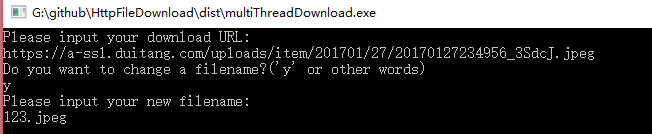
运行结果:

将(*.py)文件转化为(*.exe)可执行文件
当写好了一个工具,如何让那些没有安装Python的人使用这个工具呢?这就需要将.py文件转化为.exe文件。
这里用到Python的py2exe模块,初次使用,所以对其进行介绍:
py2exe是一个将Python脚本转换成windows上可独立执行的可执行文件(*.exe)的工具,这样,就可以不用装Python在windows上运行这个可执行程序。
接下来,在multiThreadDownload.py的同目录下,创建mysetup.py文件,编写:
from distutils.core import setup import py2exe setup(console=["multiThreadDownload.py"])
接着执行命令:Python mysetup.py py2exe
生成dist文件夹,multiTjhreadDownload.exe文件位于其中,点击运行即可:
demo下载地址:HttpFileDownload_jb51.rar
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python实现多线程抓取网页功能实例详解
本文实例讲述了Python实现多线程抓取网页功能.分享给大家供大家参考,具体如下: 最近,一直在做网络爬虫相关的东西. 看了一下开源C++写的larbin爬虫,仔细阅读了里面的设计思想和一些关键技术的实现. 1.larbin的URL去重用的很高效的bloom filter算法: 2.DNS处理,使用的adns异步的开源组件: 3.对于url队列的处理,则是用部分缓存到内存,部分写入文件的策略. 4.larbin对文件的相关操作做了很多工作 5.在larbin里有连接池,通过创建套接字,向目标站点
-
深入理解 Python 中的多线程 新手必看
示例1 我们将要请求五个不同的url: 单线程 import time import urllib2 defget_responses(): urls=[ 'http://www.baidu.com', 'http://www.amazon.com', 'http://www.ebay.com', 'http://www.alibaba.com', 'http://www.jb51.net' ] start=time.time() forurlinurls: printurl resp=urll
-

Python控制多进程与多线程并发数总结
一.前言 本来写了脚本用于暴力破解密码,可是1秒钟尝试一个密码2220000个密码我的天,想用多线程可是只会一个for全开,难道开2220000个线程吗?只好学习控制线程数了,官方文档不好看,觉得结构不够清晰,网上找很多文章也都不很清晰,只有for全开线程,没有控制线程数的具体说明,最终终于根据多篇文章和官方文档算是搞明白基础的多线程怎么实现法了,怕长时间不用又忘记,找着麻烦就贴这了,跟我一样新手也可以参照参照. 先说进程和线程的区别: 地址空间:进程内的一个执行单元;进程至少有一个线程;它们共
-
Python 多线程的实例详解
Python 多线程的实例详解 一)线程基础 1.创建线程: thread模块提供了start_new_thread函数,用以创建线程.start_new_thread函数成功创建后还可以对其进行操作. 其函数原型: start_new_thread(function,atgs[,kwargs]) 其参数含义如下: function: 在线程中执行的函数名 args:元组形式的参数列表. kwargs: 可选参数,以字典的形式指定参数 方法一:通过使用thread模块中的函数创
-
详解Python多线程Selenium跨浏览器测试
前言 在web测试中,不可避免的一个测试就是浏览器兼容性测试,在没有自动化测试前,我们总是苦逼的在一台或多台机器上安装N种浏览器,然后手工在不同的浏览器上验证主业务流程和关键功能模块功能,以检测不同浏览器或不同版本浏览器上,我们的web应用是否可以正常工作. 下面我们看看怎么利用python selenium进行自动化的跨浏览器测试. 什么是跨浏览器测试 跨浏览器测试是功能测试的一个分支,用以验证web应用能在不同的浏览器上正常工作. 为什么需要跨浏览器测试 通常情况下,我们都期望web类应用
-
python实现多线程抓取知乎用户
需要用到的包: beautifulsoup4 html5lib image requests redis PyMySQL pip安装所有依赖包: pip install \ Image \ requests \ beautifulsoup4 \ html5lib \ redis \ PyMySQL 运行环境需要支持中文 测试运行环境python3.5,不保证其他运行环境能完美运行 需要安装mysql和redis 配置 config.ini 文件,设置好mysql和redis,并且填写你的知乎帐号
-
Python 多线程Threading初学教程
1.1 什么是多线程 Threading 多线程可简单理解为同时执行多个任务. 多进程和多线程都可以执行多个任务,线程是进程的一部分.线程的特点是线程之间可以共享内存和变量,资源消耗少(不过在Unix环境中,多进程和多线程资源调度消耗差距不明显,Unix调度较快),缺点是线程之间的同步和加锁比较麻烦. 1.2 添加线程 Thread 导入模块 import threading 获取已激活的线程数 threading.active_count() 查看所有线程信息 threading.enumer
-
Python实现多线程HTTP下载器示例
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件. 环境:windows/Linux + Python2.7.x 单线程 在介绍多线程之前首先介绍单线程.编写单线程的思路为: 1.解析url: 2.连接web服务器: 3.构造http请求包: 4.下载文件. 接下来通过代码进行说明. 解析url 通过用户输入url进行解析.如果解析的路径为空,则赋值为'/':如果端口号为空,则赋值为"80":下载文件的文件名可根据用户的意愿进行更改(输入'y'表示更改,输入
-
python实现多线程网页下载器
本文为大家分享了python实现的一个多线程网页下载器,供大家参考,具体内容如下 这是一个有着真实需求的实现,我的用途是拿它来通过 HTTP 方式向服务器提交游戏数据.把它放上来也是想大家帮忙挑刺,找找 bug,让它工作得更好. keywords:python,http,multi-threads,thread,threading,httplib,urllib,urllib2,Queue,http pool,httppool 废话少说,上源码: # -*- coding:utf-8 -*- im
-
Android编程开发实现多线程断点续传下载器实例
本文实例讲述了Android编程开发实现多线程断点续传下载器.分享给大家供大家参考,具体如下: 使用多线程断点续传下载器在下载的时候多个线程并发可以占用服务器端更多资源,从而加快下载速度,在下载过程中记录每个线程已拷贝数据的数量,如果下载中断,比如无信号断线.电量不足等情况下,这就需要使用到断点续传功能,下次启动时从记录位置继续下载,可避免重复部分的下载.这里采用数据库来记录下载的进度. 效果图: 断点续传 1.断点续传需要在下载过程中记录每条线程的下载进度 2.每次下载开始之前先读取数据库
-
用python制作个音乐下载器
前言 某个夜深人静的夜晚,我打开了自己的文件夹,发现了自己写了许多似乎很无聊的代码.于是乎,一个想法油然而生:"生活已经很无聊了,不如再无聊一点叭". 说干就干,那就开一个专题,我们称之为kimol君的无聊小发明. 妙-啊~~~ 直奔主题!本文主题是用python做一个音乐下载器(MusicLover),直接上图: 想必看到这里,各位看官的脑海中已经脑补出各种JS解密,参数分析等等让初学者很头疼的东东了. 然而,我并不打算这么干~(小声嘀咕:"没想到吧") 本文很友
-
用python制作个视频下载器
前言 某个夜深人静的夜晚,夜微凉风微扬,月光照进我的书房~ 当我打开文件夹以回顾往事之余,惊现许多看似杂乱的无聊代码.我拍腿正坐,一个想法油然而生:"生活已然很无聊,不如再无聊些叭". 于是,我决定开一个专题,便称之为kimol君的无聊小发明. 妙-啊~~~ 众所周知,视频是一个学习新姿势知识的良好媒介.那么,如何利用爬虫更加方便快捷地下载视频呢?本文将从数据包分析到代码实现来进行一个相对完整的讲解. 一.爬虫分析 本次选取的目标视频网站为某度旗下的好看视频: https://haok
-
python爬取音频下载的示例代码
抓取"xmly"鬼故事音频 import json # 在这个url,音频链接为JSON动态生成,所以用到了json模块 import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36" } # 请求网页
-
Python实现一个论文下载器的过程
在科研学习的过程中,我们难免需要查询相关的文献资料,而想必很多小伙伴都知道SCI-HUB,此乃一大神器,它可以帮助我们搜索相关论文并下载其原文.可以说,SCI-HUB造福了众多科研人员,用起来也是"美滋滋". 然而,当师姐告诉我:"xx,可以帮我下载几篇文献嘛?".乐心助人的我自当是满口答应了,心想:"这种小事就交给我叭~" 于是乎,我收到了一个excel文档,66篇论文的列表安静地趟在里面(此刻心中碎碎念:"这尼玛,是几篇嘛...&q
-
python 制作网站小说下载器
基本开发环境 · Python 3.6 · Pycharm 相关模块使用 目标网页分析 输入想看的小说内容,点击搜索 这里会返回很多结果,我只选择第一个 网页数据是静态数据,但是要搜索,是post请求,需要提价data参数,如下图所示: 然后通过解析网站数据,获取第一个小说i的详情页url即可 静态网页的获取,难度是不大的. def search(): search_url = 'http://www.xbiquge.la/modules/article/waps.php' da
-
用python制作个论文下载器(图形化界面)
在科研学习的过程中,我们难免需要查询相关的文献资料,而想必很多小伙伴都知道SCI-HUB,此乃一大神器,它可以帮助我们搜索相关论文并下载其原文.可以说,SCI-HUB造福了众多科研人员,用起来也是"美滋滋". 在上一篇文章中介绍了分析过程以及相应的函数代码.根据小伙伴们的反映发现了一些问题,毕竟命令框的形式用起来难免没那么"丝滑".为了让大家更方便地使用,可以"纵享丝滑",kimol君决定写一个图形界面(GUI): PS.由于近期实属忙到晕厥,这
-
Python实现免费音乐下载器
目录 前言 正文 1)思路 2)环境 3)代码演示 4)效果展示 前言 嘿!一直在学习从没停下,最近的话一直没咋更新,因为小编也在忙着学编程~ 哈哈哈,今天刚好有时间嘛 那就给学习爬虫的小伙伴儿更新一期简单的爬虫案例实战给大家啦! 于是最后我还是选择了一种最简单,最方便的一种方法: python爬虫. 正文 1)思路 进入某音乐主页输入任意歌手,比如李XX为列. 音乐从哪里来?---网站的服务器里 怎么从网址里得到音乐?---向网站发起网络请求 最后用tkinter做成一个界面下载框即可