基于Python正则表达式提取搜索结果中的站点地址
正则表达式对于Python来说并不是独有的,最近在把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址。
这其中涉及几个需要解决的问题:
1、获取搜索的结果文本
为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果。
获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本
2、分析如何提取站点信息
首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息。
我使用IE8自带的开发工具(按F12就会弹出来)中的探查器功能查看自己要关心的内容有什么特殊的格式

从上图可以看出我需要的站点在标签<cite></cite>中,所以我使用正则表达式提取这其中的文本是否就可以呢?
3、编写正则表达式来获取站点地址
接下来的就是写表达式了,我使用Python3.2编写的,方便好用(~_~)
代码如下,先把搜索结果页面保持到e:/t3.txt中,在执行如下代码
import re
p = re.compile(r'<cite>([^<>\/].+?)</cite>')
f = open("e:/t3.txt", encoding='utf-8')
content = f.read()
print ("\n".join(p.findall(content)))
运行如下:
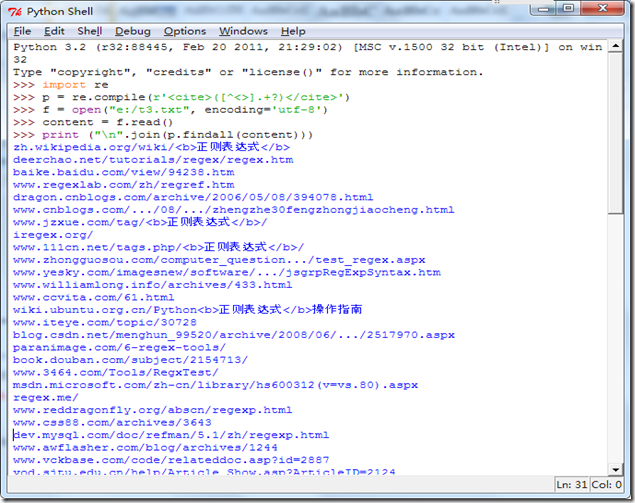
大家可以对照一下运行效果图,看看所有的站点地址是不是都给获取到了。
相关推荐
-
理解python正则表达式
在python中,对正则表达式的支持是通过re模块来支持的.使用re的步骤是先把表达式字符串编译成pattern实例,然后在使用pattern去匹配文本获取结果. 其实也有另外一种方式,就是直接使用re模块的方法,但是这样就不能使用编译后的pattern实例了. 实例: #!/usr/bin/python # -*- coding: utf-8 -*- import re pat = re.compile(r'hello') match = pat.match('hello world!') i
-
跟老齐学Python之正规地说一句话
小孩子刚刚开始学说话的时候,常常是一个字一个字地开始学,比如学说"饺子",对他/她来讲,似乎有点难度,大人也聪明,于是就简化了,用"饺饺"来代替,其实就是让孩子学会一个字就能表达.当然,从教育学的角度,有人不赞成这种方法.这个此处不讨论了.如果对比学习编程,就好像是前面已经学习过的那些各种类型的数据(对应这自然语言中的单个字.词),要表达一个完整的意思,或者让计算机完成一个事情(动作),不得不通过一句话,这句话就是语句,它是按照一定规则组织起来的.自然语言中的一句话
-

玩转python爬虫之正则表达式
面对大量杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌
-
Python正则表达式之基础篇
正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下图展示了使用正则表达式进行匹配的流程: 1.1介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.得益于这一点,在提供了
-
Python的爬虫包Beautiful Soup中用正则表达式来搜索
Beautiful Soup使用时,一般可以通过指定对应的name和attrs去搜索,特定的名字和属性,以找到所需要的部分的html代码. 但是,有时候,会遇到,对于要处理的内容中,其name或attr的值,有多种可能,尤其是符合某一规律,此时,就无法写成固定的值了. 所以,就可以借助正则表达式来解决此问题. 比如, <div class="icon_col"> <h1 class="h1user">crifan</h1> <
-
Python正规则表达式学习指南
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同:但不用担心,不被支持的语法通常是不常用的部分.如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了. 下图展示了使用正则表达式进行匹配的流程: 正则表达式的大致
-
基于Python正则表达式提取搜索结果中的站点地址
正则表达式对于Python来说并不是独有的,最近在把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址. 这其中涉及几个需要解决的问题: 1.获取搜索的结果文本 为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果. 获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本 2.分析如何提取站点信息 首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息. 我使用IE8自带的开发工具(按F12就会弹出来
-
如何利用python批量提取txt文本中所需文本并写入excel
目录 1.提取txt文本 2.增加数据框的列 3.引入基础csv数据,并扩列 汇总 总结 1.提取txt文本 我想要的文本是如图所示,宝可梦的外貌描述文本,由于原本的数据源结构并不是很稳定,而且也不是表格形式,因此在csdn上查了半天. 最原始的一行一行提取(不建议,未采用) fi = open("D:\python_learning\data\data\Axew.txt","r",encoding="utf-8") wflag =False #
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
基于Python 装饰器装饰类中的方法实例
title: Python 装饰器装饰类中的方法 comments: true date: 2017-04-17 20:44:31 tags: ['Python', 'Decorate'] category: ['Python'] --- 目前在中文网上能搜索到的绝大部分关于装饰器的教程,都在讲如何装饰一个普通的函数.本文介绍如何使用Python的装饰器装饰一个类的方法,同时在装饰器函数中调用类里面的其他方法.本文以捕获一个方法的异常为例来进行说明. 有一个类Test, 它的结构如下: clas
-
python 实现提取某个索引中某个时间段的数据方法
如下所示: from elasticsearch import Elasticsearch import datetime import time import dateutil.parser class App(object): def __init__(self): pass def _es_conn(self): es = Elasticsearch() return es def get_data(self, day,start,end): index_ = "gather-apk-20
-
python 实现提取log文件中的关键句子,并进行统计分析
利用python开发了一个提取sim.log 中的各个关键步骤中的时间并进行统计的程序: #!/usr/bin/python2.6 import re,datetime file_name='/home/alzhong/logs/qtat1/R2860.01.13/sim-applycommitrollback-bld1.log' file=open(file_name,'r') acnum=[];time_res=[];lnum=0 def trans_time(time): t1=datet
-
python re正则匹配网页中图片url地址的方法
最近写了个python抓取必应搜索首页http://cn.bing.com/的背景图片并将此图片更换为我的电脑桌面的程序,在正则匹配图片url时遇到了匹配失败问题. 要抓取的图片地址如图所示: 首先,使用这个pattern reg = re.compile('.*g_img={url: "(http.*?jpg)"') 无论怎么匹配都匹配不到,后来把网页源码抓下来放在notepad++中查看,并用notepad++的正则匹配查找,很轻易就匹配到了,如图: 后来我写了个测试代码,把图片地
-
使用Linux正则表达式灵活搜索文件中的文本
正则表达式是一种符号表示法,用于识别文本模式.Linux处理正则表达式的主要程序是grep.grep搜索与正则表达式匹配的行,并将结果输送至标准输出. 1. grep匹配模式 grep按下述方式接受选项和参数(其中,regex表示正则表达式) 复制代码 代码如下: grep [options] regex [files] 其中options主要为下表: 选项 含义 功能描述 -i ignore case 忽略大小写 -v invert match 不匹配匹配的 -l file-with-matc
-
基于python解线性矩阵方程(numpy中的matrix类)
这学期有一门运筹学,讲的两大块儿:线性优化和非线性优化问题.在非线性优化问题这里涉及到拉格朗日乘子法,经常要算一些非常变态的线性方程,于是我就想用python求解线性方程.查阅资料的过程中找到了一个极其简单的解决方式,也学到了不少东西.先把代码给出. import numpy as np # A = np.mat('1 2 3;2 -1 1;3 0 -1') A = np.array([[1, 2, 3], [2, -1, 1], [3, 0, -1]]) b = np.array([9, 8,
-
PHP提取数据库内容中的图片地址并循环输出
复制代码 代码如下: /* 1 (?s) 代表 Pattern.DOTALL,也就是匹配换行,允许 img里出现在多行 2 .*?代表非贪婪匹配任意字符,直到后面的条件出现 3 ?: 代表这个匹配但不被捕获,也就是不在结果出现 [\.gif|\.jpg] 是或者的意思 */ $pattern="/<img.*?src=[\'|\"](.*?(?:[\.gif|\.jpg]))[\'|\"].*?[\/]?>/"; $str='<p style=&q