关于linux下core dump【总结】
1、前言
一直在从事linux下后台开发,经常与core文件打交道。还记得刚开始从事linux下开发时,程序突然崩溃了,也没有任何日志。我不知所措,同事叫我看看core,我却问什么是core,怎么看。同事鄙视的眼神,我依然在目。后来学会了从core文件中分析原因,通过gdb看出程序挂再哪里,分析前后的变量,找出问题的原因。当时就觉得很神奇,core文件是怎么产生的呢?难道系统会自动产生,可是我在自己的linux系统上面写个非法程序测试,并没有产生core问题?这又是怎么回事呢?今天在ngnix的源码时候,发现可以在程序中设置core dump,又是怎么回事呢?在公司发现生成的core文件都带有进程名称、进程ID、和时间,这又是怎么做到的呢?今天带着这些疑问来说说core文件是如何生成,如何配置。
2、基本概念
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景。
3、开启core dump
可以使用命令ulimit开启,也可以在程序中通过setrlimit系统调用开启。
程序中开启core dump,通过如下API可以查看和设置RLIMIT_CORE
#include <sys/resource.h> int getrlimit(int resource, struct rlimit *rlim); int setrlimit(int resource, const struct rlimit *rlim);
参考程序如下所示:
#include <unistd.h>
#include <sys/time.h>
#include <sys/resource.h>
#include <stdio.h>
#define CORE_SIZE 1024 * 1024 * 500
int main()
{
struct rlimit rlmt;
if (getrlimit(RLIMIT_CORE, &rlmt) == -1) {
return -1;
}
printf("Before set rlimit CORE dump current is:%d, max is:%d\n", (int)rlmt.rlim_cur, (int)rlmt.rlim_max);
rlmt.rlim_cur = (rlim_t)CORE_SIZE;
rlmt.rlim_max = (rlim_t)CORE_SIZE;
if (setrlimit(RLIMIT_CORE, &rlmt) == -1) {
return -1;
}
if (getrlimit(RLIMIT_CORE, &rlmt) == -1) {
return -1;
}
printf("After set rlimit CORE dump current is:%d, max is:%d\n", (int)rlmt.rlim_cur, (int)rlmt.rlim_max);
/*测试非法内存,产生core文件*/
int *ptr = NULL;
*ptr = 10;
return 0;
}
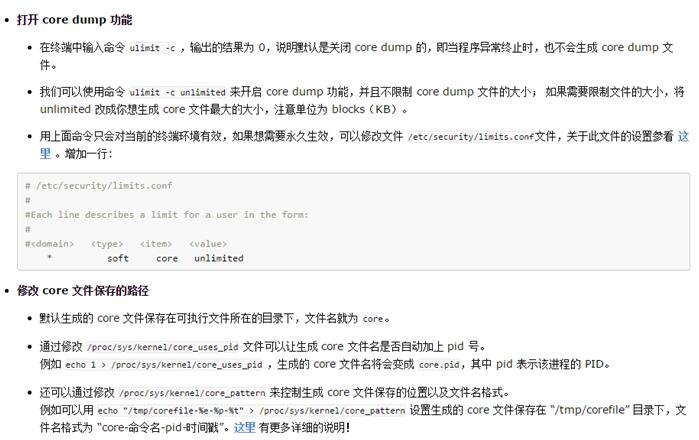
执行./main, 生成的core文件如下所示
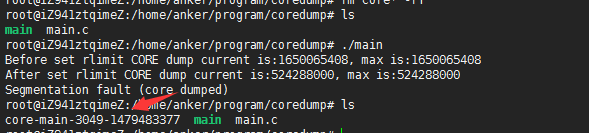
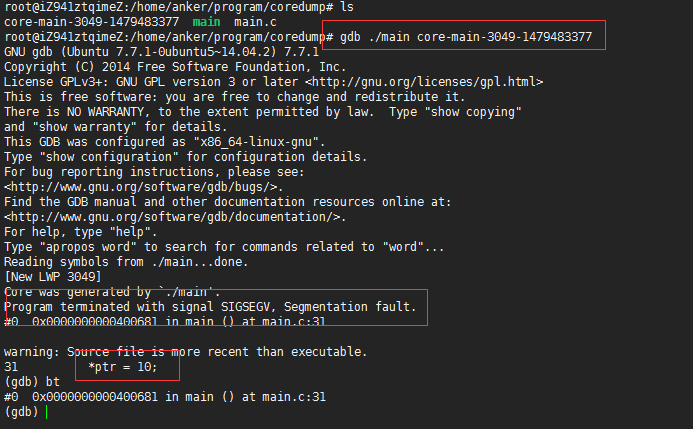
GDB调试core文件,查看程序挂在位置。当core dump 之后,使用命令 gdb program core 来查看 core 文件,其中 program 为可执行程序名,core 为生成的 core 文件名。
以上这篇关于linux下core dump【总结】就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

关于linux下core dump【总结】
1.前言 一直在从事linux下后台开发,经常与core文件打交道.还记得刚开始从事linux下开发时,程序突然崩溃了,也没有任何日志.我不知所措,同事叫我看看core,我却问什么是core,怎么看.同事鄙视的眼神,我依然在目.后来学会了从core文件中分析原因,通过gdb看出程序挂再哪里,分析前后的变量,找出问题的原因.当时就觉得很神奇,core文件是怎么产生的呢?难道系统会自动产生,可是我在自己的linux系统上面写个非法程序测试,并没有产生core问题?这又是怎么回事呢?今天在ngnix的
-
Linux下core文件的使用方法详解
前言 有时候程序会异常退出而不带任何日志,此时就可以使用 code 文件进行分析,它会记录程序运行的内存,寄存器,堆栈指针等信息 什么是core文件 通常在 Linux 下遇到程序异常退出或者中止,我们都会使用 core 文件进行分析,其中包含了程序运行时的内存,寄存器,堆栈指针等信息,格式为 ELF ,可以理解是程序工作当前状态转储成一个文件,通过工具分析这个文件,我们可以定位到程序异常退出或者终止时相应的堆栈调用等信息,为解决问题提供帮助. 使用core文件调试 生成方法 查看当前 core
-
Linux下如何使用gdb调试core文件
1.core文件 当程序运行过程中出现Segmentation fault (core dumped)错误时,程序停止运行,并产生core文件.core文件是程序运行状态的内存映象.使用gdb调试core文件,可以帮助我们快速定位程序出现段错误的位置.当然,可执行程序编译时应加上-g编译选项,生成调试信息. 当程序访问的内存超出了系统给定的内存空间,就会产生Segmentation fault (core dumped),因此,段错误产生的情况主要有: (1)访问不存在的内存地址: (2)访问系
-
ASP.NET Core在Linux下为dotnet创建守护进程
什么是守护进程 在linux或者unix操作系统中,守护进程(Daemon)是一种运行在后台的特殊进程,它独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件.由于在linux中,每个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端,这个终端被称为这些进程的控制终端,当控制终端被关闭的时候,相应的进程都会自动关闭.但是守护进程却能突破这种限制,它脱离于终端并且在后台运行,并且它脱离终端的目的是为了避免进程在运行的过程中的信息在任何终端中显示并且进程也不会
-
Linux下使用Jenkins自动化构建.NET Core应用
目录 部署 Jenkins 安装插件 拉取镜像 制作 Jenkinsfile 脚本 构建流水线 观察 部署 Jenkins 请提前在 Linux 上安装 Docker,在 Linux 中,我们使用 Docker 启动 Jenkins,这样可以避免手动安装大量依赖以及污染本地环境,也便于快速启动和故障恢复. 安装 Docker 完毕后,使用 docker version 检查 Docker 版本,Docker 版本不能为 1.x.3.x 这种版本,请升级到 18.x 以上版本.一般在 Ubuntu
-
linux下通过脚本实现自动重启程序
无论什么程序都不可能完美无缺,理论上,任何程序都有Core Dump的一天,正式运营的程序,尤其是服务器程序,一旦Core Dump,后果不堪设想,有过服务器开发经验的朋友,一定都经历过深夜美梦中,被电话惊醒的惨痛经历,手忙脚乱把服务器重新启动,第二天上班还要被老板一顿狠批.所以,程序发生错误时自动重启变得很重要.这里集中讨论linux实现自动重启程序的方法. linux下实现程序的自动重启有很多方法,这里我们介绍的是通过自己写脚本来实现, 自动重启脚本 假定需要实现重启的程序名为 test ,
-
解析Linux下C++编译和链接
编译原理 将如下最简单的C++程序(main.cpp)编译成可执行目标程序,实际上可以分为四个步骤:预处理.编译.汇编.链接,可以通过 g++ main.cpp –v看到详细的过程,不过现在编译器已经把预处理和编译过程合并. 预处理:g++ -E main.cpp -o main.ii,-E表示只进行预处理.预处理主要是处理各种宏展开:添加行号和文件标识符,为编译器产生调试信息提供便利:删除注释:保留编译器用到的编译器指令等. 编译:g++ -S main.ii –o main.s,-S表示只编
-
详解Linux下调试器GDB的基本使用方法
一.概述 GDB调试的三种方式: 1. 目标板直接使用GDB进行调试. 2. 目标板使用gdbserver,主机使用xxx-linux-gdb作为客户端. 3. 目标板使用ulimit -c unlimited,生成core文件:然后主机使用xxx-linux-gdb ./test ./core. 二.gdb调试 构造测试程序如下main.c和sum.c如下: main.c:#include <stdio.h> #include <stdlib.h> extern int sum(
-
Linux下安装MongoDB的实现步骤
Linux下安装MongoDB的实现步骤 Mongo DB 是目前在IT行业非常流行的一种非关系型数据库(NoSql),其灵活的数据存储方式备受当前IT从业人员的青睐.Mongo DB很好的实现了面向对象的思想(OO思想),在Mongo DB中 每一条记录都是一个Document对象.Mongo DB最大的优势在于所有的数据持久操作都无需开发人员手动编写SQL语句,直接调用方法就可以轻松的实现CRUD操作.本文介绍了如何快速安装mongodb供大家参考. 一.安装配置mongodb Step 1
-
Linux下Tomcat8.0.44配置使用Apr的方法
听说Apr可以提高tomcat很多的性能,配置具体如下 1.安装apr 1.5.2 [root@ecs-3c46 ]# cd /usr/local/src [root@ecs-3c46 src]# wget http://apache.fayea.com//apr/apr-1.5.2.tar.gz [root@ecs-3c46 src]# tar -xzvf apr-1.5.2.tar.gz [root@ecs-3c46 src]# cd apr-1.5.2 [root@ecs-3c46 apr