Python 实现文件读写、坐标寻址、查找替换功能
读文件
打开文件(文件需要存在)
#打开文件
f = open("data.txt","r") #设置文件对象
print(f)#文件句柄
f.close() #关闭文件
#为了方便,避免忘记close掉这个文件对象,可以用下面这种方式替代
with open('data.txt',"r") as f: #设置文件对象
str = f.read() #可以是随便对文件的操作

完全读取文件
#完全读取文件
f = open("data.txt","r") #设置文件对象
string1 = f.read() #将txt文件的所有内容读入到字符串string1中
f.close() #将文件关闭
print(string1)

按按行读取整个文件方法一(删除回车)
#按行读取整个文件方法一(删除回车)
data = []
f = open("data.txt","r") #设置文件对象
line = f.readline()
if line !='\n' and line[len(line) -1 if len(line)-1>0 else 0] == "\n":#去掉换行符,也可以不去
line_ = line[:-1]
data.append(line_)
while line: #直到读取完文件
line = f.readline() #读取一行文件,包括换行符
if line !='' and line[len(line) -1 if len(line)-1>0 else 0] == "\n":#去掉换行符,也可以不去
line_ = line[:-1]
data.append(line_)
f.close() #关闭文件
print(data)

按行读取整个文件方法一(不删除回车)
#按行读取整个文件方法一(不删除回车)
data = []
f = open("data.txt","r") #设置文件对象
line = f.readline()
data.append(line)
while line: #直到读取完文件
line = f.readline() #读取一行文件,包括换行符
if line !='':
data.append(line)
f.close() #关闭文件
print(data)

按行读取整个文件第二种方法
#按行读取整个文件第二种方法
data = []
for line in open("data.txt","r"): #设置文件对象并读取每一行文件
data.append(line) #将每一行文件加入到list中
print(data )

按行读取整个文件第三种方法
f = open("data.txt","r") #设置文件对象
data = f.readlines() #直接将文件中按行读到list里,效果与方法2一样
f.close() #关闭文件
print(data)

将文件读入numpy数组中
#将文件读入数组中
import numpy as np
data = np.loadtxt("data.txt") #将文件中数据加载到data数组里
print(data)

写文件列表写入文件
#列表写入文件(直接)
data = ['a','b','c']
#单层列表写入文件
with open("data.txt","w") as f:
f.writelines(data)

#列表写入文件(加入一些东西)
data = ['a','b','c']
#单层列表写入文件
with open("data.txt","w") as f:
for i in data:
f.write(i+'\r\n')
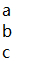
#二维列表写入文件
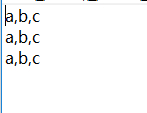
data =[ ['a','b','c'],['a','b','c'],['a','b','c']]
with open("data.txt","w") as f: #设置文件对象
for i in data:
i = str(i).strip('[').strip(']').replace(',','').replace('\'','').replace(' ',',')+'\r\n' #将其中每一个列表规范化成字符串
print(i)
f.write(i)
#第二种方法,直接将每一项都写入文件
data =[ ['a','b','c'],['a','b','c'],['a','b','c']]
with open("data.txt","w") as f: #设置文件对象
for i in data: #对于双层列表中的数据
f.writelines(i)
#将数组写入文件


import numpy as np
data =[ [1,2,3],[4,5,6],[7,8,9]]
# 第一种方法将数组中数据写入到data.txt文件
np.savetxt("data1.txt",data)
# 第二种方法将数组中数据写入到data.npy文件
np.save("data",data)
import numpy as np
filename = 'data.txt' # txt文件和当前脚本在同一目录下,所以不用写具体路径
dataele_list = []
with open(filename, 'r') as f:
while True:
lines = f.readline() # 整行读取数据
if not lines:
break
dataele_tmp = [float(i) for i in lines.split()] # 将整行数据分割处理,如果分割符是空格,括号里就不用传入参数,如果是逗号, 则传入‘,'字符。
dataele_list.append(dataele_tmp) # 添加新读取的数据
dataele_np = np.array(dataele_list) # 将数据从list类型转换为array类型。
print(dataele_np)
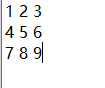

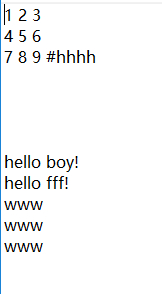
非替换写入
#非替换写入
#r+ 模式的指针默认是在文件的开头
# 如果直接写入,则会覆盖源文件,通过read() 读取文件后,指针会移到文件的末尾,再写入数据就不会有问题了。
# 这里也可以使用a 模式
f2 = open('data.txt','r+')
f2.read()
f2.write('\r\nhello boy!')
f2.close()
#非替换写入
f2 = open('data.txt','a')
f2.write('\r\nhello fff!')
f2.close()

文件坐标插入读取
# 在开始使用open打开文件时候,将打开方式从r,换成rb即可 才可以使用seek移动
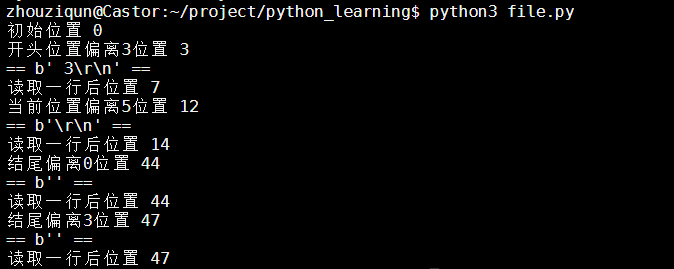
f = open('data.txt','rb')
#f.tell() #获取指针位置
print("初始位置",f.tell())
# 开头位置偏离3位置
f.seek(3,0)
print("开头位置偏离3位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
# 当前位置偏离5位置
f.seek(5,1)
print("当前位置偏离5位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
# 结尾偏离5位置
f = open('data.txt','rb')
f.seek(0,2)
print("结尾偏离0位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
f.seek(3,2)
print("结尾偏离3位置",f.tell())
print("==",f.readline(),"==")
print("读取一行后位置",f.tell())
内容查找
# 内容查找
import re
f = open('data.txt')
source = f.read()
f.close()
r = 'www'
s = len(re.findall(r,source))
print(s)
import re
f = open("data.txt",'r')
count = 0
for s in f.readlines():
li = re.findall("www",s)
if len(li)>0:
count = count + len(li)
print ("Search",count, "www")
f.close()


替换
#替换
f1 = open('data.txt','r')
f2 = open('data2.txt','w')
for s in f1.readlines():
f2.write(s.replace('www','w')+'\r\n')
f1.close()
f2.close()

#排序 去除空行 注释
f = open('data.txt')
result = list()
for line in f.readlines(): # 逐行读取数据
line = line.strip() #去掉每行头尾空白
if not len(line) or line.startswith('#'): # 判断是否是空行或注释行
continue #是的话,跳过不处理
result.append(line) #保存
f.close()
result.sort() #排序结果
print(result)
f = open('data2.txt','w')
for line in result:
f.write(line+'\r\n')

总结
以上所述是小编给大家介绍的Python 实现文件读写、坐标寻址、查找替换功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
使用Python进行二进制文件读写的简单方法(推荐)
总的感觉,python本身并没有对二进制进行支持,不过提供了一个模块来弥补,就是struct模块. python没有二进制类型,但可以存储二进制类型的数据,就是用string字符串类型来存储二进制数据,这也没关系,因为string是以1个字节为单位的. import struct a=12.34 #将a变为二进制 bytes=struct.pack('i',a) 此时bytes就是一个string字符串,字符串按字节同a的二进制存储内容相同. 再进行反操作 现有二进制数据bytes,(其实就是字
-
Python 字符串操作(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
去空格及特殊符号 s.strip().lstrip().rstrip(',') Python strip() 方法用于移除字符串头尾指定的字符(默认为空格). 复制字符串 #strcpy(sStr1,sStr2) sStr1 = 'strcpy' sStr2 = sStr1 sStr1 = 'strcpy2' print sStr2 连接字符串 #strcat(sStr1,sStr2) sStr1 = 'strcat' sStr2 = 'append' sStr1 += sStr2 print
-
Python3 中文文件读写方法
字符串在Python内部的表示是Unicode编码,因此,在做编码转换时,通常需要以Unicode作为中间编码,即先将其他编码的字符串解码(decode)成Unicode,再从Unicode编码(encode)成另一种编码. 在新版本的python3中,取消了unicode类型,代替它的是使用unicode字符的字符串类型(str),字符串类型(str)成为基础类型如下所示,而编码后的变为了字节类型(bytes) 但是两个函数的使用方法不变: decode encode bytes ------
-
python文件读写操作与linux shell变量命令交互执行的方法
本文实例讲述了python文件读写操作与linux shell变量命令交互执行的方法.分享给大家供大家参考.具体如下: python对文件的读写还是挺方便的,与linux shell的交互变量需要转换一下才能用,这比较头疼. 代码如下: 复制代码 代码如下: #coding=utf-8 #!/usr/bin/python import os import time #python执行linux命令 os.system(':>./aa.py') #人机交互输入 S = raw_input("
-
Python实现的Excel文件读写类
本文实例讲述了Python实现的Excel文件读写类.分享给大家供大家参考.具体如下: #coding=utf-8 ####################################################### #filename:ExcelRW.py #author:defias #date:2015-4-27 #function:read or write excel file #################################################
-
Python 字符串操作实现代码(截取/替换/查找/分割)
Python 截取字符串使用 变量[头下标:尾下标],就可以截取相应的字符串,其中下标是从0开始算起,可以是正数或负数,下标可以为空表示取到头或尾. 复制代码 代码如下: # 例1:字符串截取str = '12345678'print str[0:1]>> 1 # 输出str位置0开始到位置1以前的字符print str[1:6] >> 23456 # 输出str位置1开始到位置6以前的字符num = 18str = '0000' + str(num) # 合并字符串pr
-
Python 包含汉字的文件读写之每行末尾加上特定字符
最近,接手的项目里,提供的数据文件格式简直让人看不下去,使用pandas打不开,一直是io error.仔细查看,发现文件中很多行数据是以"结尾,然而其他行缺失,因而需求也就很明显了:判断每行的结尾是否有",没有的话,加上就好了. 采用倒叙的方式好了,毕竟很多人需要的只是一个快速的解决方案,而不是一个why. 解决方案如下: b = open('b_file.txt', w) with open('a_file.txt', 'r') as lines: for line in line
-
Python 实现文件读写、坐标寻址、查找替换功能
读文件 打开文件(文件需要存在) #打开文件 f = open("data.txt","r") #设置文件对象 print(f)#文件句柄 f.close() #关闭文件 #为了方便,避免忘记close掉这个文件对象,可以用下面这种方式替代 with open('data.txt',"r") as f: #设置文件对象 str = f.read() #可以是随便对文件的操作 完全读取文件 #完全读取文件 f = open("data.t
-
详解python持久化文件读写
持久化文件读写: f=open('info.txt','a+') f.seek(0) str1=f.read() if len(str1)==0: f1 = open('info.txt', 'w+') str1 = f.read() # 如果数据没有就写入数据到文件 time_list = ["早上", "中午", "晚上"] character_list = ["小赵","小钱", "小孙&q
-
java实现查找替换功能
本文实例为大家分享了java实现查找替换功能的具体代码,供大家参考,具体内容如下 查找 if(searchTxt.getText().equals("")){ JOptionPane.showMessageDialog(null, "查找内容不能为空!"); }else if(!searchTxt.getText().equals("")){ //searchDialog.dispose(); if(fileChoose.focus == 1){
-

WinForm使用DataGridView实现类似Excel表格的查找替换功能
在桌面程序开发过程中我们常常使用DataGridView作为数据展示的表格,在表格中我们可能要对数据进行查找或者替换. 其实要实现这个查找替换的功能并不难,记录下实现过程,不一定是最好的方式,但它有用! 先看demo下效果 1.数据展示建一个WinForm窗体 GridDataWindow ,放上菜单和DataGridView控件,添加4列用来显示信息. 创建一个Person类用于显示数据 public class Person { public int ID { get; set; } pub
-
批量文件查找替换功能的vbs脚本
'============================================ 'code by lcx 修改网上原有的一个小程序,不知作者,那个程序没有对目录实现递归查找 '将本程序放在你要查找的目录下,或把查找的目录拖到此脚本上,估计还有bug '======================================================================================= On Error Resume next Do Until
-
python利用文件读写编写一个博客
代码展示 import random import json import time import os def zhuce(): print("*********************正在注册*********************") try: users = readfile() except: fa = open(r'test.json', "w",encoding="utf-8&
-
Python编程中的文件读写及相关的文件对象方法讲解
python文件读写 python 进行文件读写的内建函数是open或file file_hander(文件句柄或者叫做对象)= open(filename,mode) mode: 模式 说明 r 只读 r+ 读写 w 写入,先删除源文件,在重新写入,如果文件没有则创建 w+ 读写,先删除源文件,在重新写入,如果文件没有则创建(可以写入写出) 读文件: >>> fo = open("/root/a.txt") >
-
Python实现密码薄文件读写操作
制作一个"密码薄",其可以存储一个网址,和一个密码(如 123456),请编写程序完成这个"密码薄"的增删改查功能,并且实现文件存储功能 D:\pytest_day\mimab\wenjian.py class WenJian(): def __init__(self,lujing,xieru): self.lujing=lujing self.xieru=xieru #读文件 def read_file(self): #打开文件 with open(self.lu
-
使用python修改文件并立即写回到原始位置操作(inplace读写)
很多应用多需要处理文件,而处理文件有一个固定的模式:打开文件,读入一些数据,处理这些数据,打印到屏幕上或写入另一个文件. 那么,如果我们想修改之后立即写回文件,该怎么做呢?用什么模式打开?又怎么读写? 我个人尝试了很多中方法,不是无法实现,就是操作非常麻烦.最终放弃. 幸运的是,Python内置模块fileinput就可以轻松完成.代码如下: import fileinput for line in fileinput.input(r"D:\1.txt", inplace=1): pr
-
使用Python文件读写,自定义分隔符(custom delimiter)
众所周知,python文件读取文件的时候所支持的newlines(即换行符),是指定的.这一点不管是从python的doucuments上还是在python的源码中(作者是参考了python的io版本,并没有阅读C版本),都可以看出来: if newline is not None and not isinstance(newline, str): raise TypeError("illegal newline type: %r" % (type(newline),)) if new