详解java整合solr5.0之solrj的使用
1、首先导入solrj需要的的架包
2、需要注意的是低版本是solr是使用SolrServer进行URL实例的,5.0之后已经使用SolrClient替代这个类了,在添加之后首先我们需要根据schema.xml配置一下我们的分词器

这里的msg_all还需要在schema.xml中配置
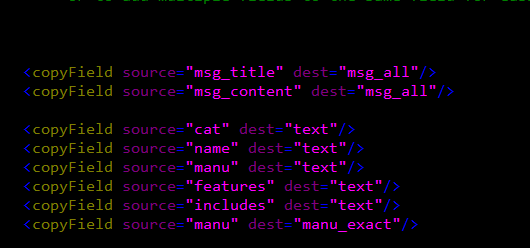
它的主要作用是将msg_title,msg_content两个域的值拷贝到msg_all域中,我们在搜索的时候可以只搜索这个msg_all域就可以了,
solr默认搜索需要带上域,比如
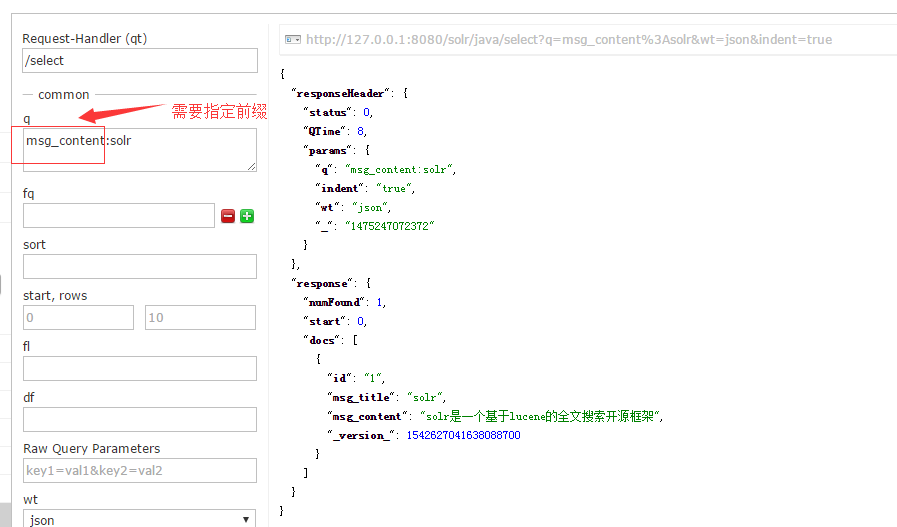
solr更改默认搜索域的地方也在schema.xml,它默认是搜索text域的,但是5.0之后不在这里配置默认搜索域了,它的文档也告诉我们,在solrconfig.xml中配置

在solrconfig.xml中配置默认搜素域,这样我们就可以按照我们自己的域进行搜索了

配置好以上,就可以使用代码进行CURD
private final static String URL="http://localhost:8080/solr/java";
public SolrClient server=null;
@Before
public void init() throws Exception{
server=new HttpSolrClient(URL);
}
删除所有分词
//删除所有分词
@Test
public void testDel() throws Exception{
server.deleteByQuery("*:*");
server.commit();//先删除 基于query的删除 会删除所有建立的索引文件
}
增加分词
@Test
public void testAdd() throws Exception{
SolrInputDocument doc=new SolrInputDocument();
doc.addField("id", "3");
doc.addField("msg_title", "新浪微博");
doc.addField("msg_content", "我有一个微博帐号名字叫做什么呢?");
server.add(doc);
server.commit();
}
基于Bean增加分词
@Test
public void test03() throws Exception{
List<Message> msgs=new ArrayList<Message>();
msgs.add(new Message("4", "第四个测试solr测试文件", new String[]{"中华人民共和国万岁","中华上下五千年那年"}));
msgs.add(new Message("5", "第5个好朋友是什么意思呢?", new String[]{"上海是个好地方","歌唱我们亲爱的祖国曾经走过千山万水"}));
server.addBeans(msgs);
server.commit();
}
查询结果
@Test
public void test04() throws Exception{
//定义查询内容 * 代表查询所有 这个是基于结果集
SolrQuery query = new SolrQuery("solr");
query.setStart(0);//起始页
query.setRows(3);//每页显示数量
QueryResponse rsp = server.query( query );
SolrDocumentList results = rsp.getResults();
System.out.println(results.getNumFound());//查询总条数
for(SolrDocument doc:results){
System.out.println(doc);
}
}
将查询结果集封装为对象Bean
@Test
public void test05() throws Exception{
SolrQuery query = new SolrQuery("中华");// * 号 是查询 所有的数据
QueryResponse rsp = server.query( query );
List<Message> beans = rsp.getBeans(Message.class);//这个不能获取查询的总数了 也不能高亮
for(Message message:beans){
System.out.println(message.toString());
}
}
将结果集高亮显示
@Test
public void test06() throws Exception{
//定义查询内容 * 代表查询所有 这个是基于结果集
SolrQuery query = new SolrQuery("solr");
query.setStart(0);//起始页
query.setRows(5);//每页显示数量
query.setParam("hl.fl", "msg_title,msg_content");//设置哪些字段域会高亮显示
query.setHighlight(true).setHighlightSimplePre("<span class='hight'>")
.setHighlightSimplePost("</span>");
QueryResponse rsp = server.query( query );
SolrDocumentList results = rsp.getResults();
System.out.println(results.getNumFound());//查询总条数
for(SolrDocument doc:results){
String id = (String) doc.getFieldValue("id"); //id is the uniqueKey field
if(rsp.getHighlighting().get(id)!=null){
//高亮必须要求存储 不存储的话 没法添加高亮
System.out.println(rsp.getHighlighting().get(id).get("msg_title"));
}
}
}
ok,solr的基本使用就完成了
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解spring中使用solr的代码实现
在介绍solr的使用方法之前,我们需要安装solr的服务端集群.基本上就是安装zookeeper,tomcat,jdk,solr,然后按照需要配置三者的配置文件即可.由于本人并没有具体操作过如何进行solr集群的搭建.所以关于如何搭建solr集群,读者可以去网上查看其它资料,有很多可以借鉴.这里只介绍搭建完solr集群之后,我们客户端是如何访问solr集群的. 之前介绍过,spring封装nosql和sql数据库的使用,都是通过xxxTemplate.solr也不例外. 我们需要引入solr的j
-
java多线程处理执行solr创建索引示例
复制代码 代码如下: public class SolrIndexer implements Indexer, Searcher, DisposableBean { //~ Static fields/initializers ============================================= static final Logger logger = LoggerFactory.getLogger(SolrIndexer.class); private static fi
-
solr在java中的使用实例代码
SolrJ是操作Solr的Java客户端,它提供了增加.修改.删除.查询Solr索引的JAVA接口.SolrJ针对 Solr提供了Rest 的HTTP接口进行了封装, SolrJ底层是通过使用httpClient中的方法来完成Solr的操作. jar包的引用(maven pom.xml): <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-solrj</artifactId
-

Solr通过特殊字符分词实现自定义分词器详解
前言 我们在对英文句子分词的时候,一般采用采用的分词器是WhiteSpaceTokenizerFactory,有一次因业务要求,需要根据某一个特殊字符(以逗号分词,以竖线分词)分词.感觉这种需求可能与WhiteSpaceTokenizerFactory相像,于是自己根据Solr源码自定义了分词策略. 业务场景 有一次,我拿到的数据都是以竖线"|"分隔,分词的时候,需要以竖线为分词单元.比如下面的这一堆数据: 有可能你拿到的是这样的数据,典型的例子就是来自csv文件的数据,格式和下面这种
-
详解java整合solr5.0之solrj的使用
1.首先导入solrj需要的的架包 2.需要注意的是低版本是solr是使用SolrServer进行URL实例的,5.0之后已经使用SolrClient替代这个类了,在添加之后首先我们需要根据schema.xml配置一下我们的分词器 这里的msg_all还需要在schema.xml中配置 它的主要作用是将msg_title,msg_content两个域的值拷贝到msg_all域中,我们在搜索的时候可以只搜索这个msg_all域就可以了, solr默认搜索需要带上域,比如 solr更改默认搜索域的地
-
详解Springboot整合ActiveMQ(Queue和Topic两种模式)
写在前面: 从2018年底开始学习SpringBoot,也用SpringBoot写过一些项目.这里对学习Springboot的一些知识总结记录一下.如果你也在学习SpringBoot,可以关注我,一起学习,一起进步. ActiveMQ简介 1.ActiveMQ简介 Apache ActiveMQ是Apache软件基金会所研发的开放源代码消息中间件:由于ActiveMQ是一个纯Java程序,因此只需要操作系统支持Java虚拟机,ActiveMQ便可执行. 2.ActiveMQ下载 下载地址:htt
-
详解Java 包扫描实现和应用(Jar篇)
如果你曾经使用过 Spring, 那你已经配过 包扫描路径吧,那包扫描是怎么实现的呢?让我们自己写个包扫描 上篇文章中介绍了使用 File 遍历的方式去进行包扫描,这篇主要补充一下jar包的扫描方式,在我们的项目中一般都会去依赖一些其他jar 包, 比如添加 guava 依赖 <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <ve
-
详解SpringBoot整合MyBatis详细教程
1. 导入依赖 首先新建一个springboot项目,勾选组件时勾选Spring Web.JDBC API.MySQL Driver 然后导入以下整合依赖 <!-- https://mvnrepository.com/artifact/org.mybatis.spring.boot/mybatis-spring-boot-starter --> <dependency> <groupId>org.mybatis.spring.boot</groupId> &
-
详解Java TCC分布式事务实现原理
概述 之前网上看到很多写分布式事务的文章,不过大多都是将分布式事务各种技术方案简单介绍一下.很多朋友看了还是不知道分布式事务到底怎么回事,在项目里到底如何使用. 所以这篇文章,就用大白话+手工绘图,并结合一个电商系统的案例实践,来给大家讲清楚到底什么是 TCC 分布式事务. 业务场景介绍 咱们先来看看业务场景,假设你现在有一个电商系统,里面有一个支付订单的场景. 那对一个订单支付之后,我们需要做下面的步骤: 更改订单的状态为"已支付" 扣减商品库存 给会员增加积分 创建销售出库单通知仓
-
SpringBoot详解如何整合Redis缓存验证码
目录 1.简介 2.介绍 3.前期配置 3.1.坐标导入 3.2.配置文件 3.3.配置类 4.Java操作Redis 1.简介 Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. 翻译:Redis 是一个开源的内存中的数据结构存储系统,它可以用作:数据库.缓存和消息中间件. 官网链接:https://redis
-
详解Java单元测试之Junit框架使用教程
目录 单元测试 Junit单元测试框架 单元测试快速入门 单元测试 单元测试就是针对最小的功能单元编写测试代码,Java程序最小的功能单元是方法,因此,单元测试就是针对Java方法的测试,进而检查方法的正确性 目前测试方法是怎么进行的,存在什么问题? 1.只有一个main方法,如果一个方法的测试失败了,其他方法测试会受到影响 2.无法得到测试的结果报告,需要程序员自己去观察测试是否成功 3.无法实现自动化测试 Junit单元测试框架 1.Junit是使用Java语言实现的单元测试框架,它是开源的
-
详解Java如何利用数字描述更多的信息
目录 一 . 前言 二 . 单数中描述信息 三. 宏观思路 总结 一 . 前言 这一篇来趣味性的探讨一下 , 如何通过更少的空间描述更多的信息 在数据库里面 ,通常我们会用数字的递进来描述状态等信息 , 但是如果想进行更复杂的操作 , 就有必要对二进制有一定理解了. 二 . 单数中描述信息 单数中保存多个信息的意思是 : 我们能把多少信息存储到一串数字里面. 这里直接来通过一些案例来说明用法 用单个数字来表示状态 这也是业务中最常见的一种使用方式 , 通过数字 1,2,3 等来描述一个状态 ,
-
详解Java中多线程异常捕获Runnable的实现
详解Java中多线程异常捕获Runnable的实现 1.背景: Java 多线程异常不向主线程抛,自己处理,外部捕获不了异常.所以要实现主线程对子线程异常的捕获. 2.工具: 实现Runnable接口的LayerInitTask类,ThreadException类,线程安全的Vector 3.思路: 向LayerInitTask中传入Vector,记录异常情况,外部遍历,判断,抛出异常. 4.代码: package step5.exception; import java.util.Vector
-
详解Java编写并运行spark应用程序的方法
我们首先提出这样一个简单的需求: 现在要分析某网站的访问日志信息,统计来自不同IP的用户访问的次数,从而通过Geo信息来获得来访用户所在国家地区分布状况.这里我拿我网站的日志记录行示例,如下所示: 121.205.198.92 - - [21/Feb/2014:00:00:07 +0800] "GET /archives/417.html HTTP/1.1" 200 11465 "http://shiyanjun.cn/archives/417.html/" &qu