sqlserver 不能将值NULL插入列id(列不允许有空值解决)
错误现象:
Microsoft OLE DB Provider for SQL Server 错误 '80040e2f'不能将值 NULL 插入列 'id',表 'web.dbo.dingdan';列不允许有空值。INSERT 失败。
/Untitled-2.asp,行 115
原因分析:
SQL数据库中,建立表时没有将id列标识规范设置为“是”。所以大家在创建表的时候一定将id设为自动增加id,标识之类的。
解决办法:
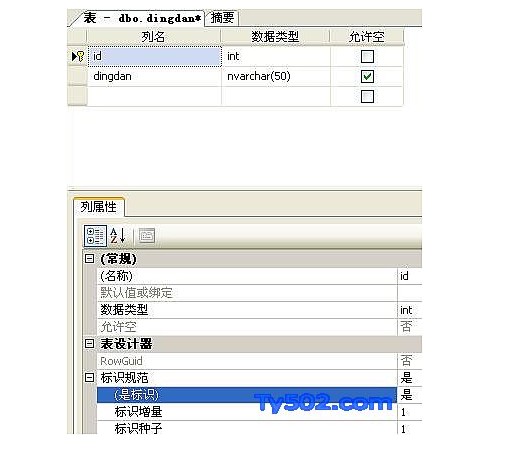
点击表,修改,设置id列标识规范为“是”,如下图。
相关推荐
-
SQLServer用存储过程实现插入更新数据示例
实现 1)有相同的数据,直接返回(返回值:0): 2)有主键相同,但是数据不同的数据,进行更新处理(返回值:2): 3)没有数据,进行插入数据处理(返回值:1). [创建存储过程] Create proc Insert_Update @Id varchar(20), @Name varchar(20), @Telephone varchar(20), @Address varchar(20), @Job varchar(20), @returnValue int output as declar
-
sqlserver中向表中插入多行数据的insert语句
下面把在sql吧里一位高手的解决方法,公布下.供大家参考: 假设有个表有 学号.姓名.学校 这三列 然后向这个表中插入 040501 孙明 山东大学 040502 李浩 山东师范 040503 王刚 烟台大学 怎么插入这三行数据啊~~~~~~~ 复制代码 代码如下: insert 表名 select '040504','孙明','山东大学' union select '040502','李浩','山东师范' union select '040503','王刚','烟台大学'
-
快速插入大量数据的asp.net代码(Sqlserver)
复制代码 代码如下: using System.Data; using System.Diagnostics; using System.Data.SqlClient; string connectionString = "Data Source=HG-J3EJJ9LSW5PY;Initial Catalog=Test;User ID=sa;password=hg"; DataTable dataTable = sql_.select_datagrid(" select a
-
SQL Server实现将特定字符串拆分并进行插入操作的方法
本文实例讲述了SQL Server实现将特定字符串拆分并进行插入操作的方法.分享给大家供大家参考,具体如下: --循环执行添加操作 declare @idx as int While Len(@UserList) > 0 Begin Set @idx = Charindex(',', @UserList); --只有一条数据 If @idx = 0 and Len(@UserList) > 0 Begin Insert Into BIS_MsgCenterInfo(ID,MsgID,UserI
-

SQLServer 批量插入数据的两种方法
运行下面的脚本,建立测试数据库和表值参数. 复制代码 代码如下: --Create DataBase create database BulkTestDB; go use BulkTestDB; go --Create Table Create table BulkTestTable( Id int primary key, UserName nvarchar(32), Pwd varchar(16)) go --Create Table Valued CREATE TYPE BulkUdt A
-
SqlServer下通过XML拆分字符串的方法
复制代码 代码如下: DECLARE @idoc int; DECLARE @doc xml; set @doc=cast('<Root><item><ProjID>'+replace(@SelectedProjectArray,',','</ProjID></item><item><ProjID>')+'</ProjID></item></Root>' as xml) EXEC sp_
-
使用SQL Server 获取插入记录后的ID(自动编号)
最近在开发项目的过程中遇到一个问题,就是在插入一条记录的后要立即获取所在数据库中ID,而该ID是自增的,怎么做?在sql server 2005中有几种方式可以实现. 要获取此ID,最简单的方法就是在查询之后select @@indentity --SQL语句创建数据库和表 复制代码 代码如下: create database dbdemo go use dbdemo go create table tbldemo ( id int primary key identity(1,1),
-
sqlserver2008 拆分字符串
--说明:例如,将下列数据 id id_value ----------------- 1 'aa,bb' 2 'aa,bb,cc' 3 'aaa,bbb,ccc' --转换成以下的格式 id id_value ----------------- 1 'aa' 1 'bb' 2 'aa' 2 'bb' 2 'cc' 3 'aaa' 3 'bbb' 3 'ccc' --代码-------------------------------------------GO 复制代码 代码如下: create
-
sql server中批量插入与更新两种解决方案分享(asp.net)
若只是需要大批量插入数据使用bcp是最好的,若同时需要插入.删除.更新建议使用SqlDataAdapter我测试过有很高的效率,一般情况下这两种就满足需求了 bcp方式 复制代码 代码如下: /// <summary> /// 大批量插入数据(2000每批次) /// 已采用整体事物控制 /// </summary> /// <param name="connString">数据库链接字符串</param> /// <param n
-
sqlserver 不能将值NULL插入列id(列不允许有空值解决)
错误现象: Microsoft OLE DB Provider for SQL Server 错误 '80040e2f'不能将值 NULL 插入列 'id',表 'web.dbo.dingdan':列不允许有空值.INSERT 失败. /Untitled-2.asp,行 115 原因分析: SQL数据库中,建立表时没有将id列标识规范设置为"是".所以大家在创建表的时候一定将id设为自动增加id,标识之类的. 解决办法: 点击表,修改,设置id列标识规范为"是",如
-
spark dataframe 将一列展开,把该列所有值都变成新列的方法
The original dataframe 需求:hour代表一天的24小时,现在要将hour列展开,每一个小时都作为一个列 实现: val pivots = beijingGeoHourPopAfterDrop.groupBy("geoHash").pivot("hour").sum("countGeoPerHour").na.fill(0) 并且统计了对应的countGeoPerHour的和,如果有些行没有这个新列对应的数据,将用null填
-
select隐藏选中值对应的id,显示其它id的简单实现方法
由于select选项较少,做的简单, <select name="typeid" id="typeid"> <option value="-1">-请选择类型-</option> <option value="grade">兑换等级</option> <option value="money">兑换现金</option> &
-
vantUI 获得piker选中值的自定义ID操作
问题 官网中给的picker例子,每项只能是个字符串,但我需要它返回每个字符串对应的自定义ID,而不是index. vantUI官网:picker 官网例子 <van-picker :columns="columns" @change="onChange" /> export default { data() { return { columns: ['杭州', '宁波', '温州', '嘉兴', '湖州'] }; }, methods: { onCha
-
pandas按照列的值排序(某一列或者多列)
按照某一列排序 d = {'A': [3, 6, 6, 7, 9], 'B': [2, 5, 8, 0, 0]} df = pd.DataFrame(data=d) print('排序前:\n', df) ''' 排序前: A B 0 3 2 1 6 5 2 6 8 3 7 0 4 9 0 ''' res = df.sort_values(by='A', ascending=False) print('按照A列的值排序:\n', res) ''' 按照A列的值排序: A B 4 9 0 3 7
-
MySQL的自增ID(主键) 用完了的解决方法
在 MySQL 中用很多类型的自增 ID,每个自增 ID 都设置了初始值.一般情况下初始值都是从 0 开始,然后按照一定的步长增加(一般是自增 1).一般情况下,我们都是用int(11)来作为数据表的自增 ID,在 MySQL 中只要定义了这个数的字节长度,那么就会有上限. MySQL的自增ID(主键) 用完了,怎么办? 如果用 int unsigned (int,4个字节 ), 我们可以算下最大当前声明的自增ID最大是多少,由于这里定义的是 int unsigned,所以最大可以达到2的32幂
-
BeanUtils.copyProperties()拷贝id属性失败的原因及解决
目录 BeanUtils.copyProperties()拷贝id属性失败 部分代码如下 解决方法 BeanUtils.copyProperties 出错 BeanUtils.copyProperties()拷贝id属性失败 po类中id有值,但是使用BeanUtils.copyProperties()拷贝出的vo类id属性为null,检查后发现是因为po继承的父类声明了一个泛型. 部分代码如下 public abstract class AbstractEntity<ID extends Se
-
php生成excel列名超过26列大于Z时的解决方法
本文实例讲述了php生成excel列名超过26列大于Z时的解决方法.分享给大家供大家参考.具体分析如下: 我们生成excel都会使用phpExcel类,这里就来给大家介绍在生成excel列名超过26列大于Z时的解决办法,这是phpExcel类中的方法,今天查到了,记录一下备忘,代码如下: 复制代码 代码如下: public static function stringFromColumnIndex($pColumnIndex = 0) { // Using a lookup
-
Ajax提交参数的值中带有html标签不能提交成功的解决办法(ASP.NET)
最近在公司做资源及文章上传功能遇到一个小问题,被坑了好半天. 该功能就类似利用富文本编辑器发布信息,但是用Ajax提交数据,因此提交参数值中不可避免的含有html标签. 在本地运行代码一直没问题,总是可以提交成功,但是代码部署到线上就不能成功提交数据了,被坑了好久,找了好半天才找到问题所在. 提交不成功的原因是因为我的提交数据中含有html标签,然后直接无法请求到我的目标地址. 然后解决办法如下: 1.在页面用JS的Base64编码(类似加密)带有html标签的参数值. 2.在目标地址获
-
pandas筛选某列出现编码错误的解决方法
如下所示: df = df[df['cityname']==u'北京市'] 记得,如果用的python2,一定要导入 import sys reload(sys) sys.setdefaultencoding('utf-8') 或者在中文前面加入u'表示unicode编码的,因为pandas对象中中文字符为unicode类型的. 以上这篇pandas筛选某列出现编码错误的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.