weblogic的集群与配置图文方法
一、Weblogic的集群
还记得我们在第五天教程中讲到的关于Tomcat的集群吗?
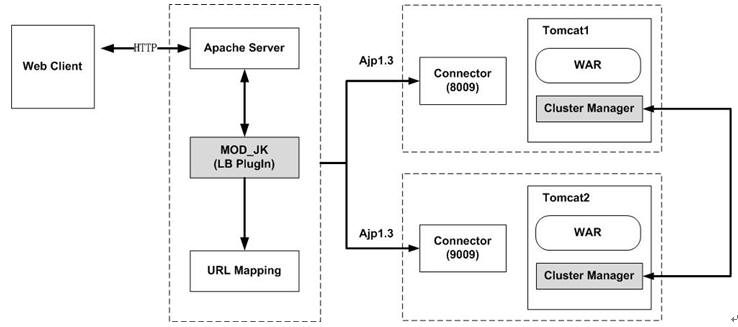
两个tomcat做node即tomcat1, tomcat2,使用Apache HttpServer做请求派发。
现在看看WebLogic的集群吧,其实也差不多。
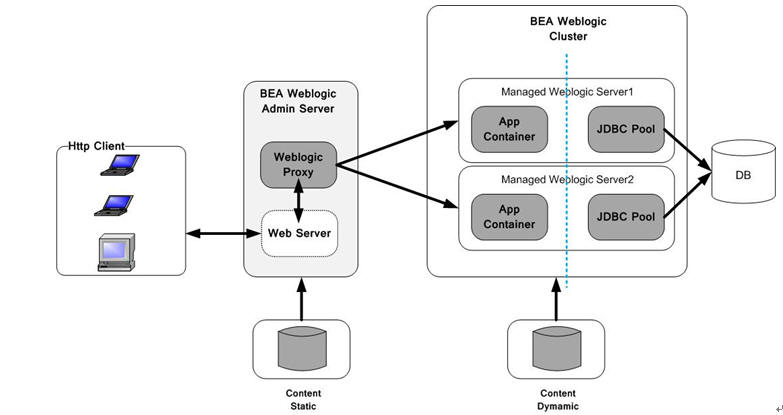
区别在于:
Tomcat的集群的实现为两个物理上不同的tomcat,分别就是两个node,没有总控端,没有任何控制台可言(只有通过比较简陋的http://localhost:8080/manager/html,或者是http://localhost:9090/manager/html)来对每个tomcat节点进行监视(此处只有monitor没有control);
如果我们要布署我们的Web应用,需要分别手工往每个Tomcat的webapp目录里拷贝文件。
Weblogic的集群必须设立一个总控端,可从上图中看出,然后这个总控端我们把它称为AdminServer,然后在其下可以挂weblogic的集群的node,这个node不是物理上不同的两个weblogic,而是不同的domain,我们假设domain1, domain2为两个weblogic的集群的节点。
如果我们要布署我们的Web应用,只需要在总控端布署一次,然后挂在这个总控端下的节点将会自动将我们的web应用发布到每一个节点。
因此,要实现weblogic的集群必须:
安装Weblogic创建一个AdminServer的domain在AdminServer上建立集群总控端分别创建每一个要加入此集群总控端的node,也是一个个的domain
二、创建Weblogic集群前的规划
根据第一节中的内容,我们将我们用于实验的Weblogic规划成3个domain,每个domain都包含有下列的必不可少的属性:
AdminConsole(总控端)
逻辑名
物理名(domain的系统路径)
端口号
计器名(IP)
登录信息(username/password)
Cluster node1(集群节点1)
逻辑名
物理名(domain的系统路径)
端口号
计器名(IP)
登录信息(username/password)
Cluster node2(集群节点2)
逻辑名
物理名(domain的系统路径)
端口号
计器名(IP)
登录信息(username/password)
我们用表格列出我们将要创建的集群中总控端与每个节点的集息:
|
物理名 |
逻辑名 |
端口号 |
主机名(IP) |
登录信息 |
|
\bea\user_projects\domains\adminserver |
AdminServer |
7001 |
localhost |
weblogic/password_1 |
|
\bea\user_projects\domains\server1 |
mycluster1 |
7011 |
localhost |
weblogic/password_1 |
|
bea\user_projects\domains\server2 |
mycluster2 |
7012 |
localhost |
weblogic/password_1 |
规划好了,就可以开始来创建我们的集群了。
三、开始创建我们的Weblogic集群3.1 创建集群的总控制端(aminserver)
Windows:
Windows下通过菜单->OracleWeblogic->Weblogic Server 11gR1->Tools->Configuration Wizard来启动创建domain的wizard。
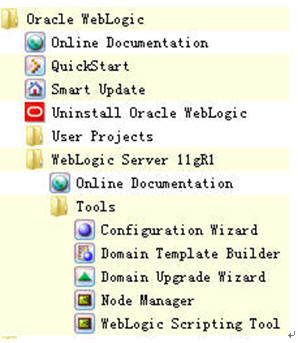
Unix/Linux:
Unix/Linux下通过
|
cd /bea/wlserver/common/bin ./config.sh |
来启动创建domain的wizard。
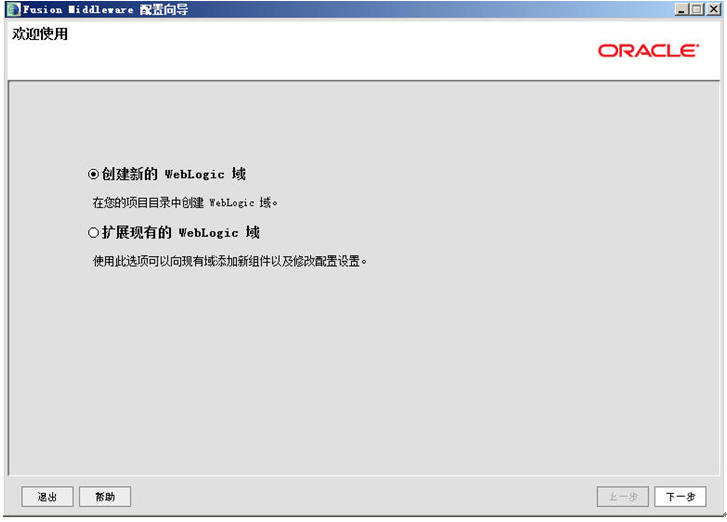
选择“创建新的Weblogic域”,选下一步(下面全部跟着我的操作步骤与界面填选的参数走,所有的用户名啦、密码啦、端口号啦、IP啦,都请根据第一节中的那个表格里的参数填写)
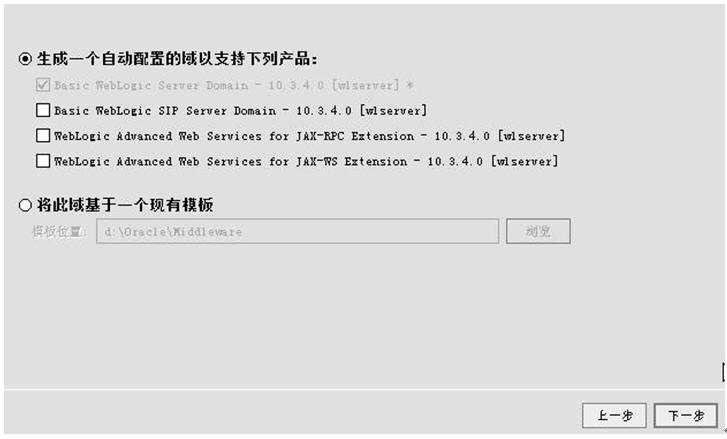
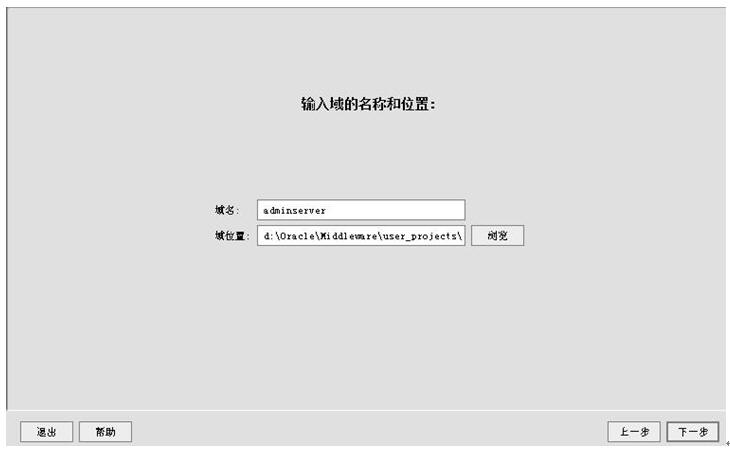
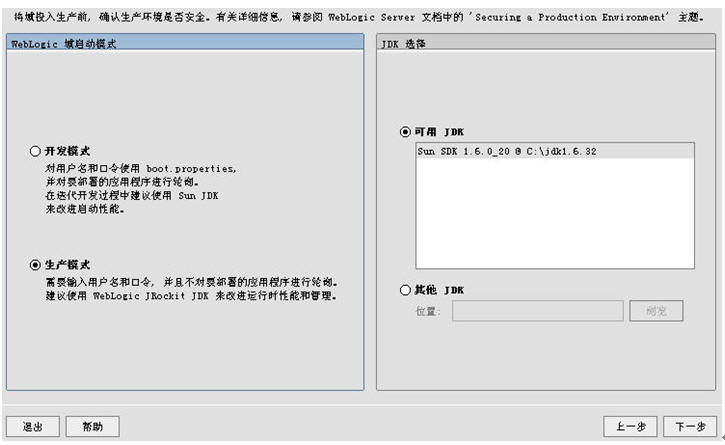
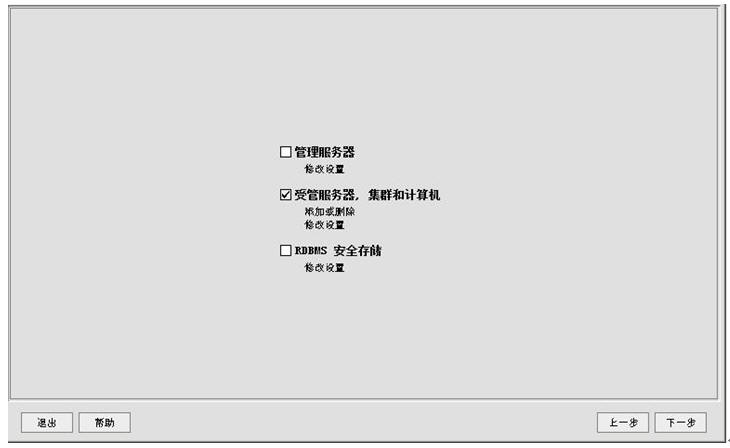
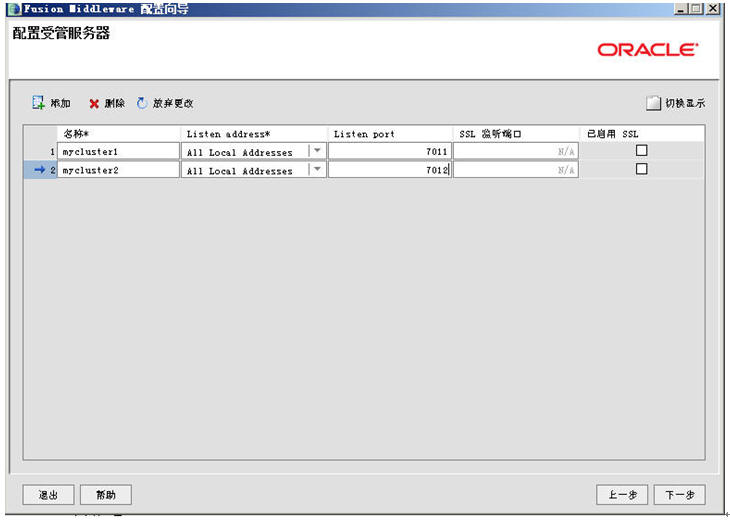
下一步后界面类似,但是是有区别的,注意了哦,不要下手太快了
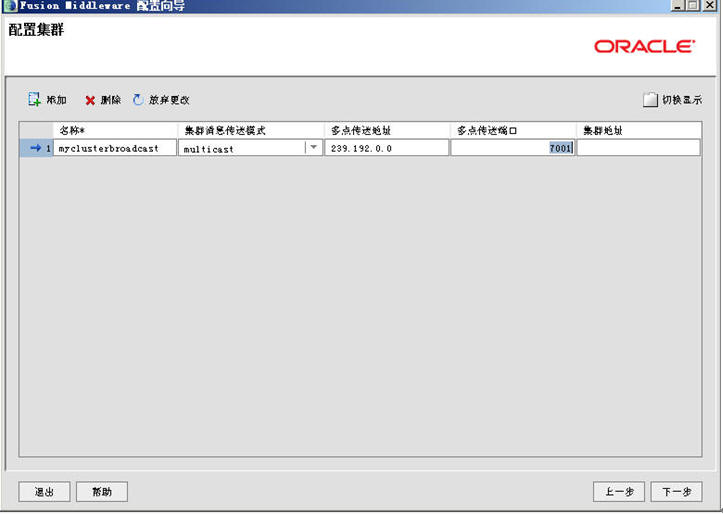
上面这个配的就叫集群广播地址的界面。
因为集群是通过广播(有unicast和multicast两种)来同步集群中的节点,并且把每个节点中的session通过这个广播地址来进行复制和同步,即主控域不断的时时刻刻的会和它下面的子节点间保持通讯、经常去询问各个子节点的。
名称:可以任意集群信息传送模式:有unitcast与multicast两种,在11G版本前都是multicast10G后开始支持unicast协议。如果指定了multicast,就必须指定一个“多点传送地址”,此地址和端口都可以采用weblogic默认的。
如果在域环境,还需要在防火墙中配置这个“多点传送地址”与“多点传送端口”,使其在防火墙中被打开,协议为both of tcp and udp。

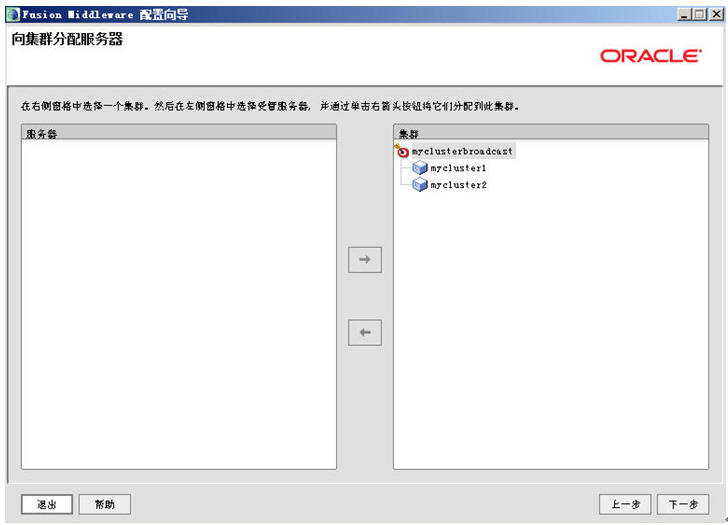
Look, 右边这块我们把它称为“集群的逻辑拓卜图”。

此处是对每个集群里的节点指定相应的“计算机名/IP”,由于我们的实验是建立在同一台机器上的即纵向集群,因此这步什么都不需要填,直接下一步。
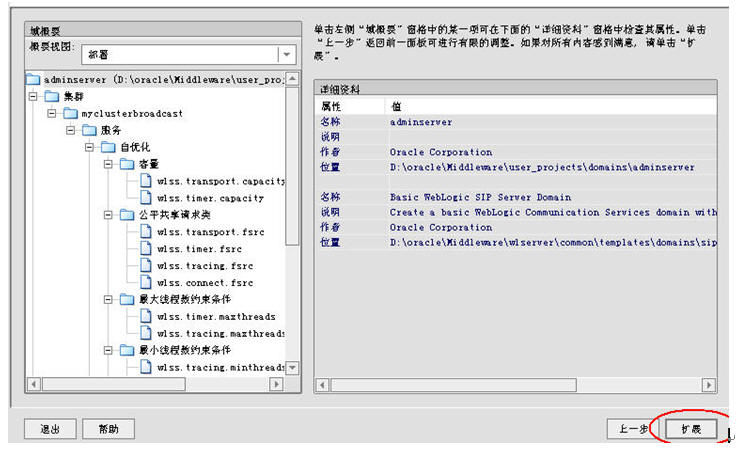
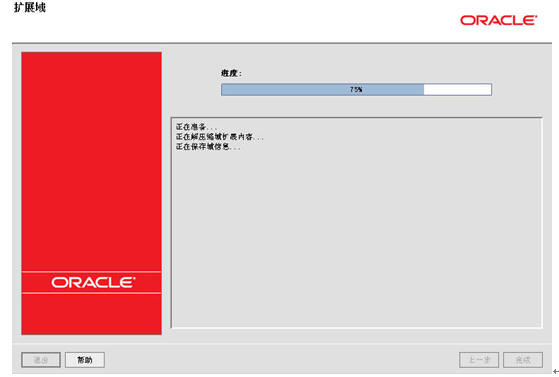

完成后可以启动adminserver

然后通过http://localhost:7001/console来查看我们的集群规划,如下图:

这样,我们就完成了创建一个新的domain并且将且扩展成为了集群的总控制端服务器,同时在这上面我们制作了一个“集群拓卜图”,那么下面要做的就是:
创建该集群拓卜图中的节点1创建该集群拓卜图中的节点23.2 创建集群中的节点(mycluster1, mycluster2)
启动Weblogic的Configuration Wizard
按照普通的域,就是一个普通的域来创建(为了实验方便我们的用户名与密码全部为weblogic/password_1):
user_projects\domains\server1(逻辑名为:mycluster1,端口:7011)user_projects\domains\server2(逻辑名为:mycluster2,端口:7012)




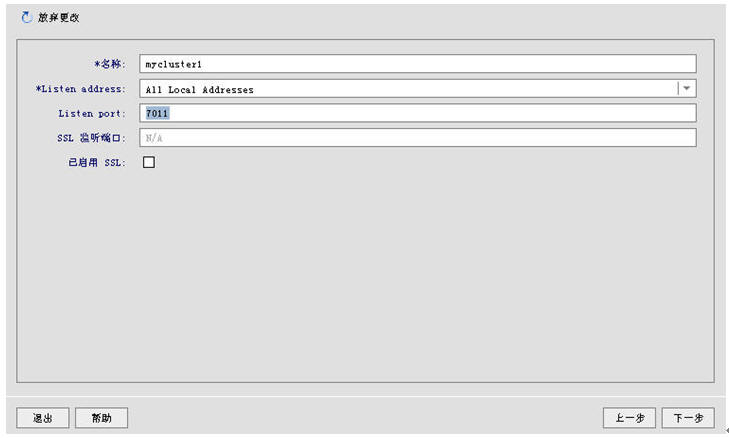
下一步,下一步,创建,完成。
依上面的相同步骤可以自行创建server2(逻辑名为mycluster2,端口:7012)。
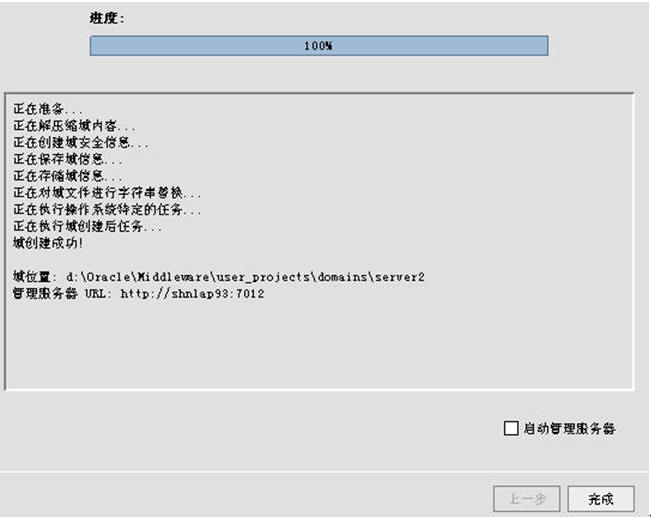
3.3 如何启动集群
|
物理名 |
逻辑名 |
端口号 |
主机名(IP) |
登录信息 |
|
\bea\user_projects\domains\adminserver |
AdminServer |
7001 |
localhost |
weblogic/password_1 |
|
\bea\user_projects\domains\server1 |
mycluster1 |
7011 |
localhost |
weblogic/password_1 |
|
bea\user_projects\domains\server2 |
mycluster2 |
7012 |
localhost |
weblogic/password_1 |
我们看着上面这个表格来输入命令吧:
1. 启动主控域(必须永远先启动主控域)
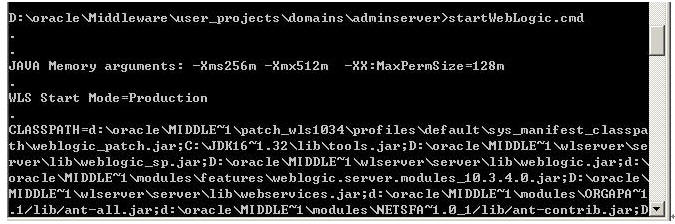
2. 启动节点1(间点间的启动顺序无所谓)

3. 启动节点2(间点间的启动顺序无所谓)
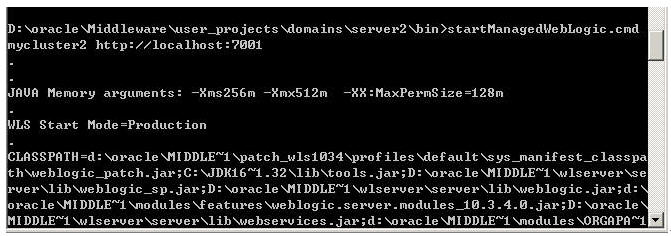
全部启动完毕后就可以通过主控制域的admin console即http://localhost:7001/console来管理这个集群了。

四、jdbc集群
有了集群,我们就可以布署我们的JDBC了,只是这个JDBC的布署和以前单机版的JDBC布署稍稍有点不一样,前面我们引用第八天中的建立JDBC的步骤:
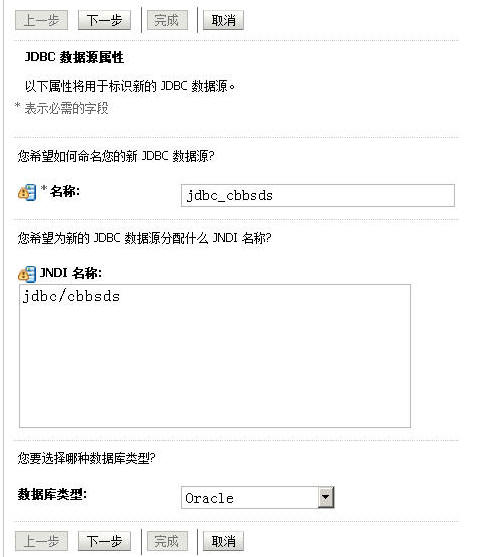
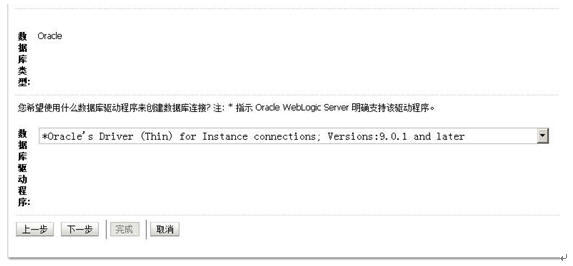
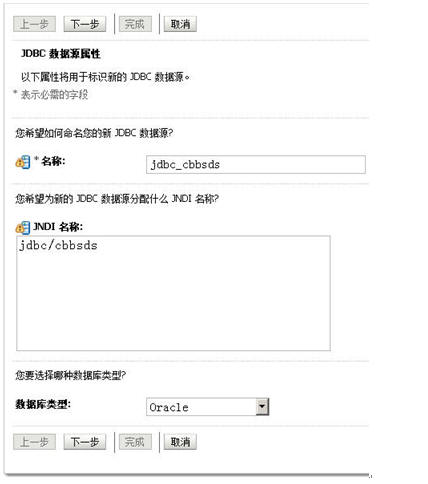
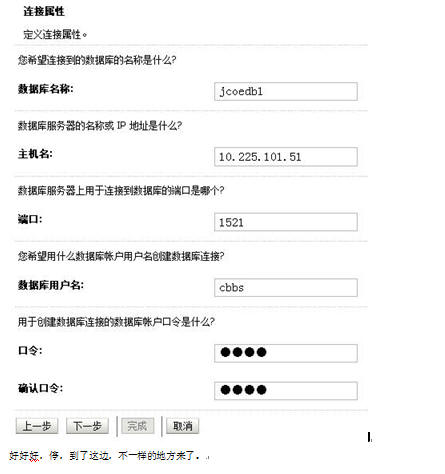
好好好,停,到了这边,不一样的地方来了。
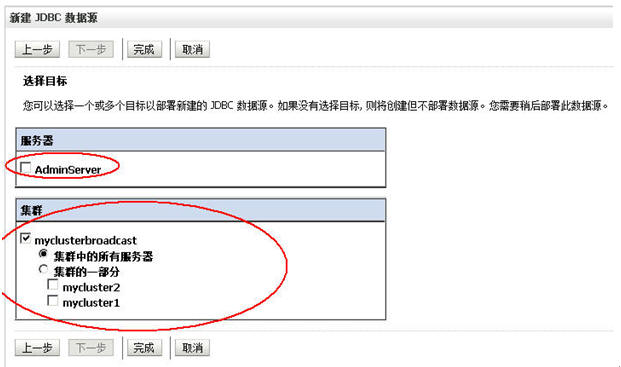
嘿嘿,千万不要把这个JDBC连接池的“target”即作用域设错了哈,我们现在是集群,要把这个JDBC连接池的作用域设在我们的集群上的哈!

我们来测试一下我们建立的数据源吧。
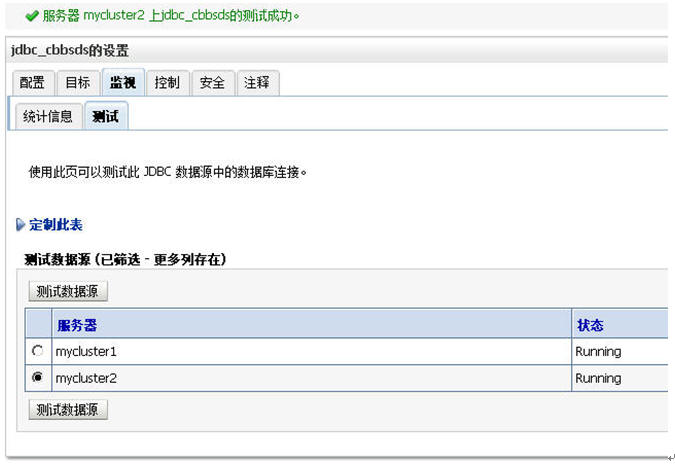
两个cluster上的数据源全部部署成功。
这边再提一句:
集群布署的话AdminServer只是一个控制器,通过它布署的war程序是自动同步到挂在它下面的所有的节点中去的,因此JDBC数据源,或者JMS或者是EJB都要在绑定是把target即作用域设成cluster而不是AdminServer本身,因为AdminServer本身不会布署任何任何东西的。
五、把工程布署到集群环境中去确保我们将要布署的工程中的web.xml的最后一行含有:
<distributable/>
在将要布署的工程的WEB-INF目录下新建一个weblogic.xml的文件,其内容如下:
<?xml version="1.0" encoding="UTF-8"?> <weblogic-web-app xmlns="http://www.bea.com/ns/weblogic/90"> <session-descriptor> <debug-enabled>true</debug-enabled> <persistent-store-type>replicated</persistent-store-type> <sharing-enabled>true</sharing-enabled> </session-descriptor> <context-root>/cbbs</context-root> </weblogic-web-app>
该内容使得你的工程可以在Weblogic集群环境下进行Session复制。
然后就可以开始布署了
下面又来了,和在集群中布署JDBC是一样的,请看:

下一步,下一步一直到[完成]按钮亮起来后,点[完成]。
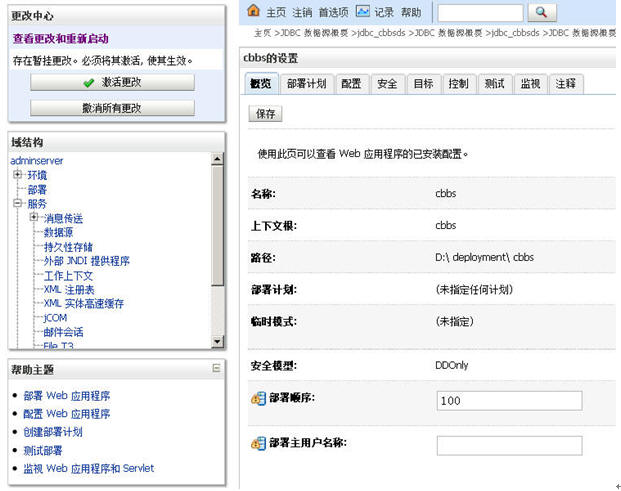
点[保存]并[激活更改]。
大家来看看两个cluster即mycluster1与mycluster2下是否被布署了工程,即相当于我们手工要在两个tomcat节点的webapps目录里拷入我们的WAR工程,而weblogic只需要通过主控制域,自动将war工程布署在其下的所有子节点内。
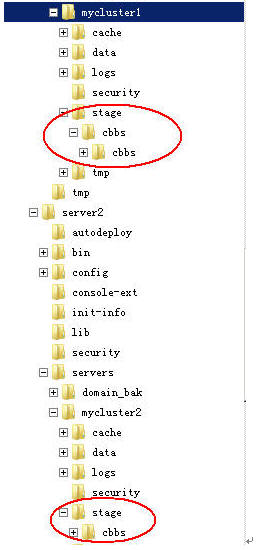
是的,果然,它自动布署了。就算我下面有10几个子节点,它也一样只需要在AdminServer上布署一次,自动同步。
我们把这个工程启动起来吧。

当你一点“为所有请求提供服务,再来看两个字节点的后台console,都可以同步启动了:
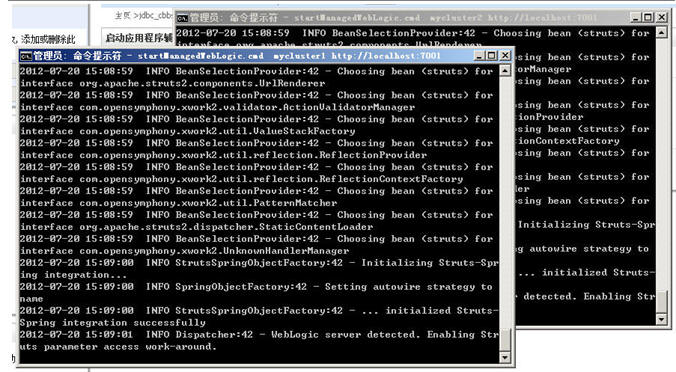
布署成功

打开两个IE:
一个输入: http://localhost:7011/cbbs
一个输入: http://localhost:7012/cbbs
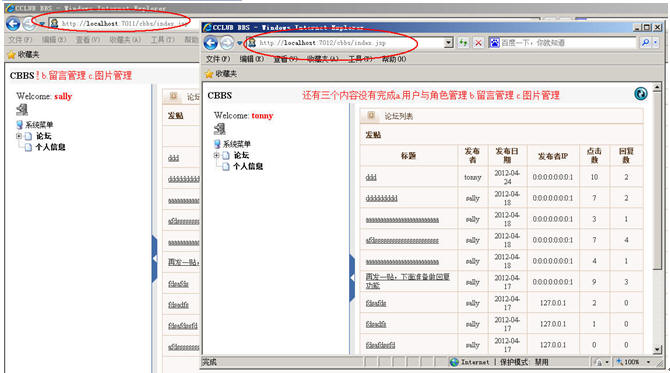
Weblogic集群布署成功,接下去就是在Apache里进行派发了
六、使用Apache与Weblogic集群整合
打开httpd.conf,把下面这段就是我们在“第九天”中加入的,去掉:
LoadModule weblogic_module modules/mod_wl_22.so <IfModule mod_weblogic.c> WebLogicHost localhost WebLogicPort 7001 MatchExpression /cbbs/WEB-INF MatchExpression /cbbs/*WEB-INF MatchExpression /cbbs/*.action MatchExpression /cbbs/servlet/* MatchExpression /cbbs/*.jsp MatchExpression /cbbs/*fckeditor/editor/filemanager/connectors/*.* MatchExpression /cbbs/fckeditor/editor/filemanager/connectors/* WLLogFile logs/wlproxy.log </IfModule>
换成下面这一段
LoadModule weblogic_module modules/mod_wl_22.so <IfModule mod_weblogic.c> Include conf/weblogic.conf </IfModule>
然后在apache安装的conf目录下手工建立weblogic.conf文件,其内容如下:
WeblogicCluster localhost:7011,localhost:7012 MatchExpression /cbbs/WEB-INF MatchExpression /cbbs/*WEB-INF MatchExpression /cbbs/*.action MatchExpression /cbbs/servlet/* MatchExpression /cbbs/*.jsp MatchExpression /cbbs/*fckeditor/editor/filemanager/connectors/*.* MatchExpression /cbbs/fckeditor/editor/filemanager/connectors/*
重启你的Apache,输入:http://localhost/cbbs/index.jsp
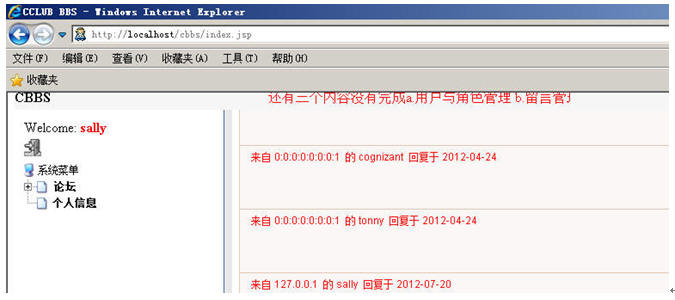
Apache加Weblogic集群,搞定!
七、JMS集群
这是我在用Weblogic集群布署PEGA Rulz的详细步骤,供各为参考。因为网上关于JMS在Weblogic下如何作集群不是太多,因此把步骤记录下来Share给大家。
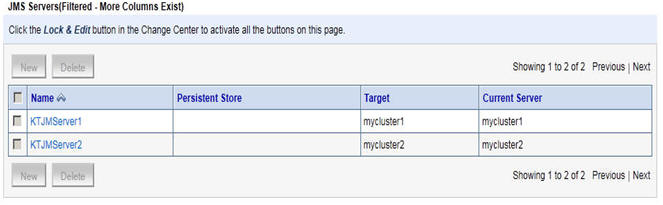
JMS集群和JDBC集群不一样,就是不能够直接建立JMS源,然后把它target到我们的myclusterbroadcast上去。
而是需要分别为每个cluster单独建一个jms的server如下图。
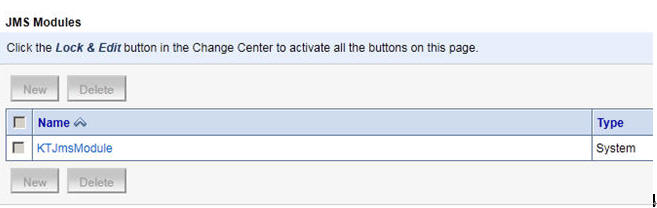
然后建立jmsmodule
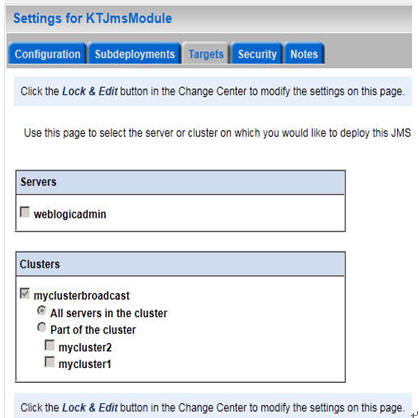
将module 的作用范围即target到我们的cluster(myclusterbroadcast)上去。
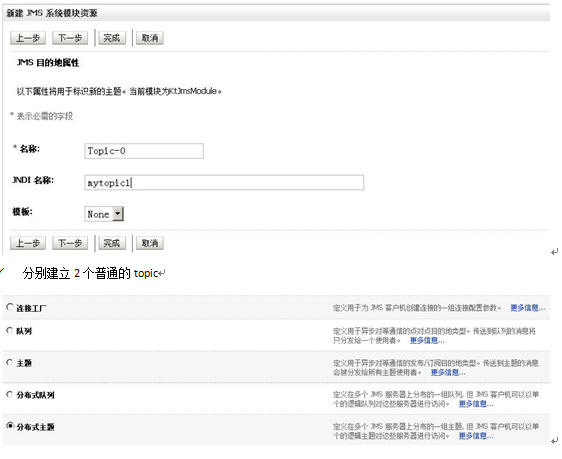
建立完了module你就要建立topic, queue以及相应的topic connection factory或者是queue connectionfactory了是吧?因为我们这边给PEGA Rulz做集群用的是topic方式来发布集群的,因此我们以topic为例,queue的建立也就一样了。
单击刚才我们建立的KTJmsModule

点[New]
先建connection factory
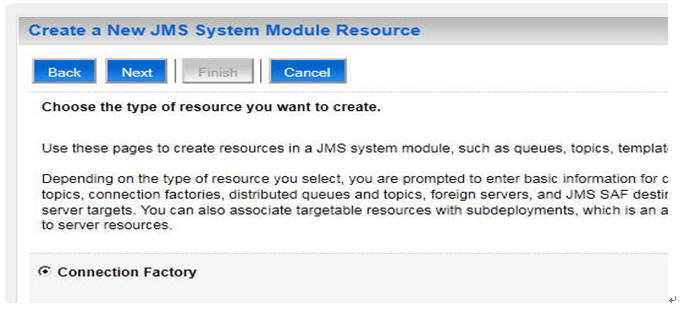
在新建connectionfactory的界面中有一个[高级定位]的按钮

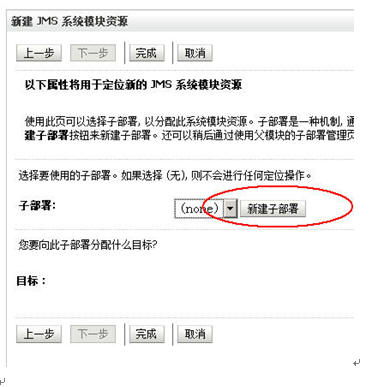
点[新建子部署]
填入完子布署的名称后,按照如下图来“target”

点完成后跳出如下的界面

此时我们可以开始真正建立我们的topic或者是queue了
前面说了不能够直接建立JMS源,然后把它target到我们的myclusterbroadcast上去。那么我们要对JMS进行集群即对Topic或者是Queue进行集群,但是我们可以建立一个Distribute Topic,然后分别建两个一边的topic,一个topic连向jmsserver1一个topic连向jmsserver2,然后把这个Distribute Topic定位(Target)到这两条topic上即是我们的“集群下的jms topic”。
在jmd module里点[新建]按钮
选择“主题”(不是分布式主题)
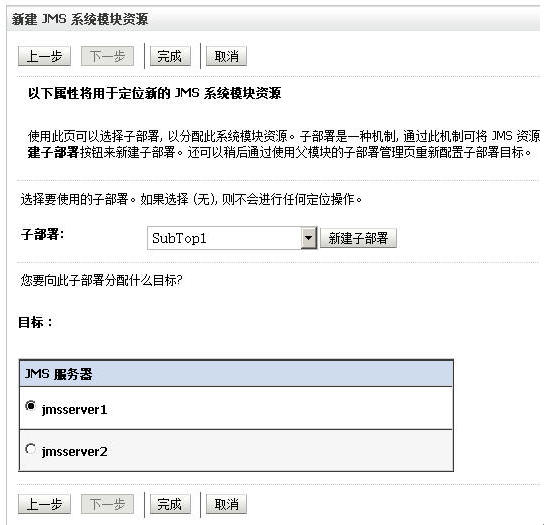
每个子部署(sub deployment)需要定位(target)到一个jms server上。
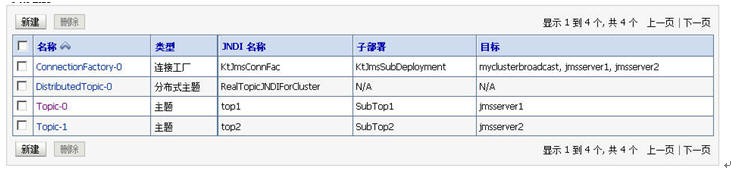
依此分别建立:
topic1 subtop1->jmsserver1topic2 subtop2->jmsserver2
现在,我们的jms module里的内容因该如下图所示:

建立 “分布式主题”(DistributeTopic)
在jms module里点新建按钮,选“分布式主题”
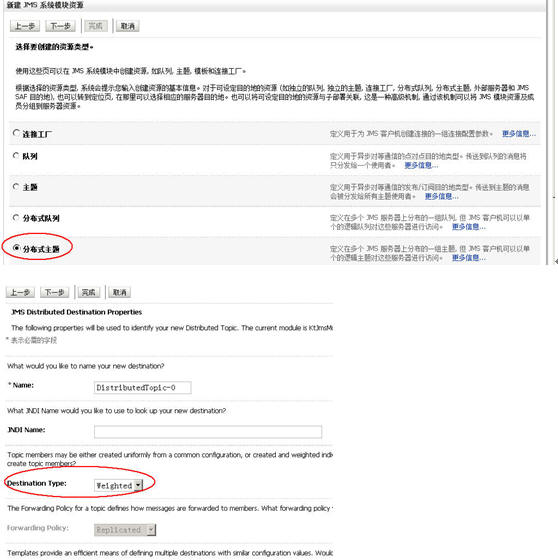
一定要记得把“Destination Type”改成“Weighted”。
这边的分布式Topic的JNDI Name: 就是我们真正的需要用来做集群的JMS的Topic或者是Queue的jndi名,比如说我的产品PEGA Rulz需要在集群环境下用到RamTopicJNDI,这个JNDI Name就必须填产品说明书上的那个Topic或者是Queue的名字哦。
点下一步后将刚才两个新建的topic全部分配给这个distribute topic
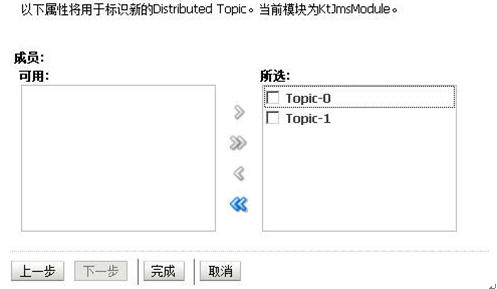
点[完成]按钮
这样,一个集群环境下的JMS分布式主题(Topic)就全建完了,最后不要忘了点左边菜单上方的“激活更改”,保存您刚才的所有的更改。
相关推荐
-
Red Hat Linux,Apache2.0+Weblogic9.2负载均衡集群安装配置
************************************************************************************************************************ JDK安装步骤 1. 以root身份登录系统 2. 到java.sun.com去下载JDK1.5 for LINUX的rpm,是个jdk-1_5_0_11-linux-i586-rpm.bin的文件. 3. 通过chmod +x jdk-1_5_x-rc-l
-

CentOS 6.3安装配置Weblogic-10方法
zhoulf 2013-02-22 09:51:52 原创 安装说明 安装环境:CentOS-6.3-x64 软件:server1001_ccjk_linux32.bin 安装方式:bin文件安装 安装位置:/usr/local/weblogic/ 下载地址:http://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-1703574.html 安装准备 复制代码 代码如下: #创建weblogic用户组.
-
Oracle WebLogic Server 12.2.1.2安装部署教程
本教程为大家分享了Oracle WebLogic Server 12.2.1.2安装与项目部署,供大家参考,具体内容如下 1.下载 http://www.oracle.com/technetwork/middleware/weblogic/downloads/wls-for-dev-1703574.html 选择红框里面下载其中一个就可以. 现在不分windows版本和linux版本,为了兼容统一只发布jar版,安装过程方法一样 2.安装 直接执行java -d64 -jar D:\xxx\xx
-
weblogic的集群与配置图文方法
一.Weblogic的集群 还记得我们在第五天教程中讲到的关于Tomcat的集群吗? 两个tomcat做node即tomcat1, tomcat2,使用Apache HttpServer做请求派发. 现在看看WebLogic的集群吧,其实也差不多. 区别在于: Tomcat的集群的实现为两个物理上不同的tomcat,分别就是两个node,没有总控端,没有任何控制台可言(只有通过比较简陋的http://localhost:8080/manager/html,或者是http://localhost:
-
VMware + Ubuntu18.04 搭建Hadoop集群环境的图文教程
目录 前言 VMware克隆虚拟机(准备工作,克隆3台虚拟机,一台master,两台node) 1.创建Hadoop用户(在master,node1,node2执行) 2.更新apt下载源(在master,node1,node2执行) 3. 安装SSH.配置SSH免密登录 (在master,node1,node2执行) 4.安装Java环境 (在master,node1,node2执行) 修改主机名(在master,node1,node2执行) 修改IP映射(在master,node1,node
-
PHP实现分布式memcache设置web集群session同步的方法
本文实例讲述了PHP实现分布式memcache设置web集群session同步的方法. php的session默认是文件存储: session.save_handler = files session.save_path = "/var/lib/php/session" 当做web集群,需要session同步时,将session存到分布式memcache来达到共享同步是个不错的办法 方法: 第1种: vi /etc/php.ini session.save_handler = memc
-
Redis集群的搭建图文教程
redis集群的特点: 1.机器多,能够保证redis服务器出现问题后,影响较小 2.自备主从结构,自动的根据算法划分主从结构.动态的实现 3.能够根据主从结构自动的实现高可用 4.实现数据文件的备份 3.Redis集群的搭建步骤: 准备9台服务器 3主6从 一个主机下有2个子节点 7000-7008 2.拷贝redis.conf文件到文件夹中 cp redis.conf 7000/redis-7000.conf mkdir 7000 7001 7002 7003 7004 7005 7006
-
docker安装Elasticsearch7.6集群并设置密码的方法步骤
目录 一些基础配置 关于版本和docker镜像 开始 关于elasticsearch.yml 关于证书elastic-certificates.p12 生成密码 使用密码 忘记密码 Elasticsearch从6.8开始, 允许免费用户使用X-Pack的安全功能, 以前安装es都是裸奔.接下来记录配置安全认证的方法. 为了简化物理安装过程,我们将使用docker安装我们的服务. 一些基础配置 es需要修改linux的一些参数. 设置vm.max_map_count=262144 sudo vim
-
Nginx+Tomcat负载均衡集群安装配置案例详解
目录 前言 一.Nginx+Tomcat 二.配置Nginx服务器 三.部署Tomcat应用服务器 总结 前言 介绍Tomcat及Nginx+Tomcat负载均衡集群,Tomcat的应用场景,然后重点介绍Tomcat的安装配置.Nginx+Tomcat负载均衡集案列是应用于生产环境的一套可靠的Web站点解决方案. 一.Nginx+Tomcat 通常情况下,一个Tomcat站点由于可能出现单点故障及无法应付过多客户复杂多样的请求等问题,不能单独应用于生产环境下,所以我们需要一套更可靠的解决方案来完
-
MySQL 5.6.51 解压版(zip版)安装配置图文方法
导读:MySQL是一款关系型数据库产品,官网给出了两种安装包格式:MSI和ZIP.MSI格式是图形界面安装方式,基本只需下一步即可,这篇文章主要介绍ZIP格式的安装过程.ZIP Archive版是免安装的.只要解压就行了. 一.首先下载MySQL 进入官网https://dev.mysql.com/downloads/mysql/5.6.html进行下载. 根据自己电脑选择32位或64位. 下载完成后,得到mysql-5.6.51-winx64.zip,解压到你想安装的目录(改名mysql-5.
-
Sentinel实现动态配置的集群流控的方法
介绍 为什么要使用集群流控呢? 相对于单机流控而言,我们给每台机器设置单机限流阈值,在理想情况下整个集群的限流阈值为机器数量✖️单机阈值.不过实际情况下流量到每台机器可能会不均匀,会导致总量没有到的情况下某些机器就开始限流.因此仅靠单机维度去限制的话会无法精确地限制总体流量.而集群流控可以精确地控制整个集群的调用总量,结合单机限流兜底,可以更好地发挥流量控制的效果. 基于单机流量不均的问题以及如何设置集群整体的QPS的问题,我们需要创建一种集群限流的模式,这时候我们很自然地就想到,可以找一个 s
-
MongoDB的分片集群基本配置教程
为何要分片 1.减少单机请求数,降低单机负载,提高总负载 2.减少单机的存储空间,提高总存空间. 常见的mongodb sharding 服务器架构 要构建一个 MongoDB Sharding Cluster,需要三种角色: 1.Shard Server 即存储实际数据的分片,每个Shard可以是一个mongod实例,也可以是一组mongod实例构成的Replication Set.为了实现每个Shard内部的auto-failover(自动故障切换),MongoDB官方建议每个Shard为一