详解Redis 缓存 + Spring 的集成示例
《整合 spring 4(包括mvc、context、orm) + mybatis 3 示例》一文简要介绍了最新版本的 Spring MVC、IOC、MyBatis ORM 三者的整合以及声明式事务处理。现在我们需要把缓存也整合进来,缓存我们选用的是 Redis,本文将在该文示例基础上介绍 Redis 缓存 + Spring 的集成。
1. 依赖包安装
pom.xml 加入:
<!-- redis cache related.....start --> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>1.6.0.RELEASE</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.7.3</version> </dependency> <!-- redis cache related.....end -->
2. Spring 项目集成进缓存支持
要启用缓存支持,我们需要创建一个新的 CacheManagerbean。CacheManager 接口有很多实现,本文演示的是和 Redis 的集成,自然就是用 RedisCacheManager 了。Redis 不是应用的共享内存,它只是一个内存服务器,就像 MySql 似的,我们需要将应用连接到它并使用某种“语言”进行交互,因此我们还需要一个连接工厂以及一个 Spring 和 Redis 对话要用的 RedisTemplate,这些都是 Redis 缓存所必需的配置,把它们都放在自定义的 CachingConfigurerSupport 中:
/**
* File Name:RedisCacheConfig.java
*
* Copyright Defonds Corporation 2015
* All Rights Reserved
*
*/
package com.defonds.bdp.cache.redis;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
/**
*
* Project Name:bdp
* Type Name:RedisCacheConfig
* Type Description:
* Author:Defonds
* Create Date:2015-09-21
*
* @version
*
*/
@Configuration
@EnableCaching
public class RedisCacheConfig extends CachingConfigurerSupport {
@Bean
public JedisConnectionFactory redisConnectionFactory() {
JedisConnectionFactory redisConnectionFactory = new JedisConnectionFactory();
// Defaults
redisConnectionFactory.setHostName("192.168.1.166");
redisConnectionFactory.setPort(6379);
return redisConnectionFactory;
}
@Bean
public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory cf) {
RedisTemplate<String, String> redisTemplate = new RedisTemplate<String, String>();
redisTemplate.setConnectionFactory(cf);
return redisTemplate;
}
@Bean
public CacheManager cacheManager(RedisTemplate redisTemplate) {
RedisCacheManager cacheManager = new RedisCacheManager(redisTemplate);
// Number of seconds before expiration. Defaults to unlimited (0)
cacheManager.setDefaultExpiration(3000); // Sets the default expire time (in seconds)
return cacheManager;
}
}
当然也别忘了把这些 bean 注入 Spring,不然配置无效。在 applicationContext.xml 中加入以下:
<context:component-scan base-package="com.defonds.bdp.cache.redis" />
3. 缓存某些方法的执行结果
设置好缓存配置之后我们就可以使用 @Cacheable 注解来缓存方法执行的结果了,比如根据省份名检索城市的 provinceCities 方法和根据 city_code 检索城市的 searchCity 方法:
// R
@Cacheable("provinceCities")
public List<City> provinceCities(String province) {
logger.debug("province=" + province);
return this.cityMapper.provinceCities(province);
}
// R
@Cacheable("searchCity")
public City searchCity(String city_code){
logger.debug("city_code=" + city_code);
return this.cityMapper.searchCity(city_code);
}
4. 缓存数据一致性保证
CRUD (Create 创建,Retrieve 读取,Update 更新,Delete 删除) 操作中,除了 R 具备幂等性,其他三个发生的时候都可能会造成缓存结果和数据库不一致。为了保证缓存数据的一致性,在进行 CUD 操作的时候我们需要对可能影响到的缓存进行更新或者清除。
// C
@CacheEvict(value = { "provinceCities"}, allEntries = true)
public void insertCity(String city_code, String city_jb,
String province_code, String city_name,
String city, String province) {
City cityBean = new City();
cityBean.setCityCode(city_code);
cityBean.setCityJb(city_jb);
cityBean.setProvinceCode(province_code);
cityBean.setCityName(city_name);
cityBean.setCity(city);
cityBean.setProvince(province);
this.cityMapper.insertCity(cityBean);
}
// U
@CacheEvict(value = { "provinceCities", "searchCity" }, allEntries = true)
public int renameCity(String city_code, String city_name) {
City city = new City();
city.setCityCode(city_code);
city.setCityName(city_name);
this.cityMapper.renameCity(city);
return 1;
}
// D
@CacheEvict(value = { "provinceCities", "searchCity" }, allEntries = true)
public int deleteCity(String city_code) {
this.cityMapper.deleteCity(city_code);
return 1;
}
业务考虑,本示例用的都是 @CacheEvict 清除缓存。如果你的 CUD 能够返回 City 实例,也可以使用 @CachePut 更新缓存策略。笔者推荐能用 @CachePut 的地方就不要用 @CacheEvict,因为后者将所有相关方法的缓存都清理掉,比如上面三个方法中的任意一个被调用了的话,provinceCities 方法的所有缓存将被清除。
5. 自定义缓存数据 key 生成策略
对于使用 @Cacheable 注解的方法,每个缓存的 key 生成策略默认使用的是参数名+参数值,比如以下方法:
@Cacheable("users")
public User findByUsername(String username)
这个方法的缓存将保存于 key 为 users~keys 的缓存下,对于 username 取值为 "赵德芳" 的缓存,key 为 "username-赵德芳"。一般情况下没啥问题,二般情况如方法 key 取值相等然后参数名也一样的时候就出问题了,如:
@Cacheable("users")
public Integer getLoginCountByUsername(String username)
这个方法的缓存也将保存于 key 为 users~keys 的缓存下。对于 username 取值为 "赵德芳" 的缓存,key 也为 "username-赵德芳",将另外一个方法的缓存覆盖掉。
解决办法是使用自定义缓存策略,对于同一业务(同一业务逻辑处理的方法,哪怕是集群/分布式系统),生成的 key 始终一致,对于不同业务则不一致:
@Bean
public KeyGenerator customKeyGenerator() {
return new KeyGenerator() {
@Override
public Object generate(Object o, Method method, Object... objects) {
StringBuilder sb = new StringBuilder();
sb.append(o.getClass().getName());
sb.append(method.getName());
for (Object obj : objects) {
sb.append(obj.toString());
}
return sb.toString();
}
};
}
于是上述两个方法,对于 username 取值为 "赵德芳" 的缓存,虽然都还是存放在 key 为 users~keys 的缓存下,但由于 key 分别为 "类名-findByUsername-username-赵德芳" 和 "类名-getLoginCountByUsername-username-赵德芳",所以也不会有问题。
这对于集群系统、分布式系统之间共享缓存很重要,真正实现了分布式缓存。
笔者建议:缓存方法的 @Cacheable 最好使用方法名,避免不同的方法的 @Cacheable 值一致,然后再配以以上缓存策略。
6. 缓存的验证
6.1 缓存的验证
为了确定每个缓存方法到底有没有走缓存,我们打开了 MyBatis 的 SQL 日志输出,并且为了演示清楚,我们还清空了测试用 Redis 数据库。
先来验证 provinceCities 方法缓存,Eclipse 启动 tomcat 加载项目完毕,使用 JMeter 调用 /bdp/city/province/cities.json 接口:
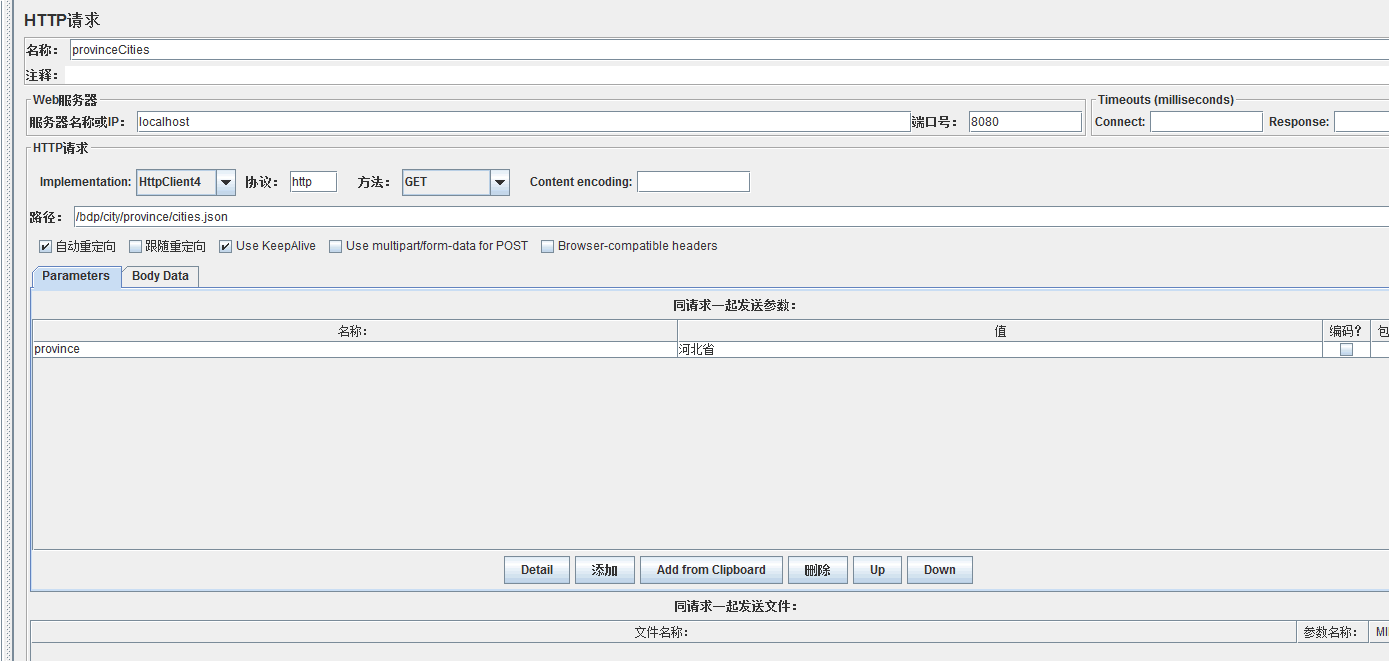
Eclipse 控制台输出如下:

说明这一次请求没有命中缓存,走的是 db 查询。JMeter 再次请求,Eclipse 控制台输出:
输出:

标红部分以下是这一次请求的 log,没有访问 db 的 log,缓存命中。查看本次请求的 Redis 存储情况:
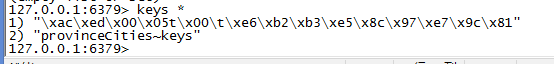
同样可以验证 city_code 为 1492 的 searchCity 方法的缓存是否有效:

图中标红部分是 searchCity 的缓存存储情况。
6.2 缓存一致性的验证
先来验证 insertCity 方法的缓存配置,JMeter 调用 /bdp/city/create.json 接口:
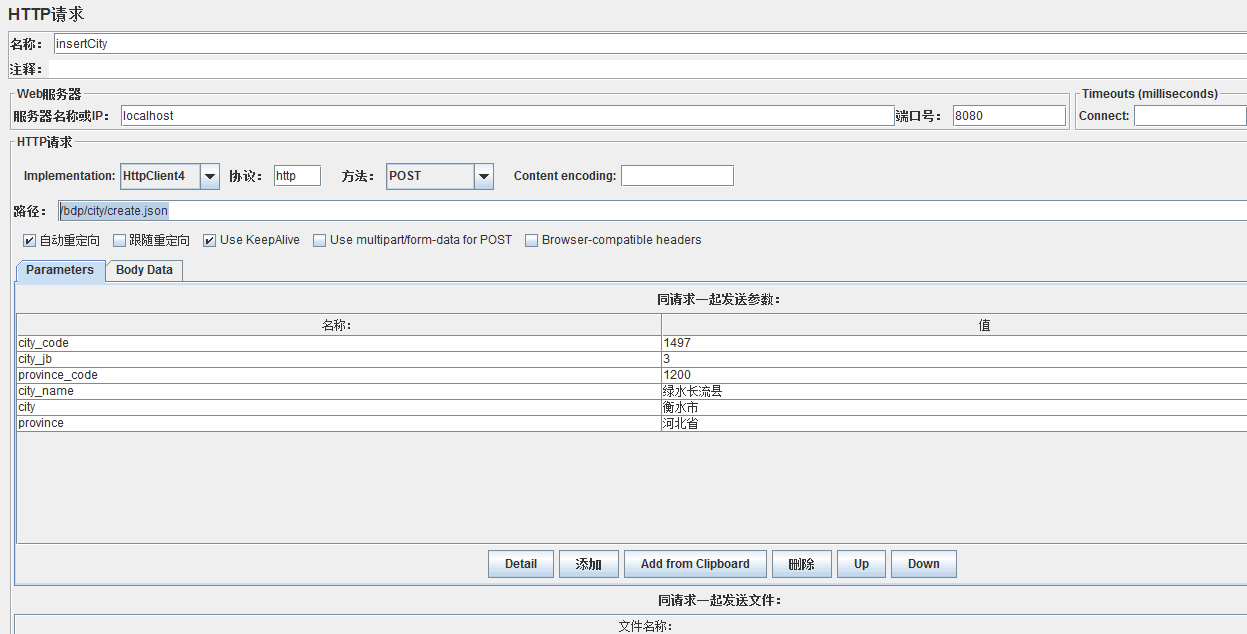
之后看 Redis 存储:

可以看出 provinceCities 方法的缓存已被清理掉,insertCity 方法的缓存奏效。
然后验证 renameCity 方法的缓存配置,JMeter 调用 /bdp/city/rename.json 接口:
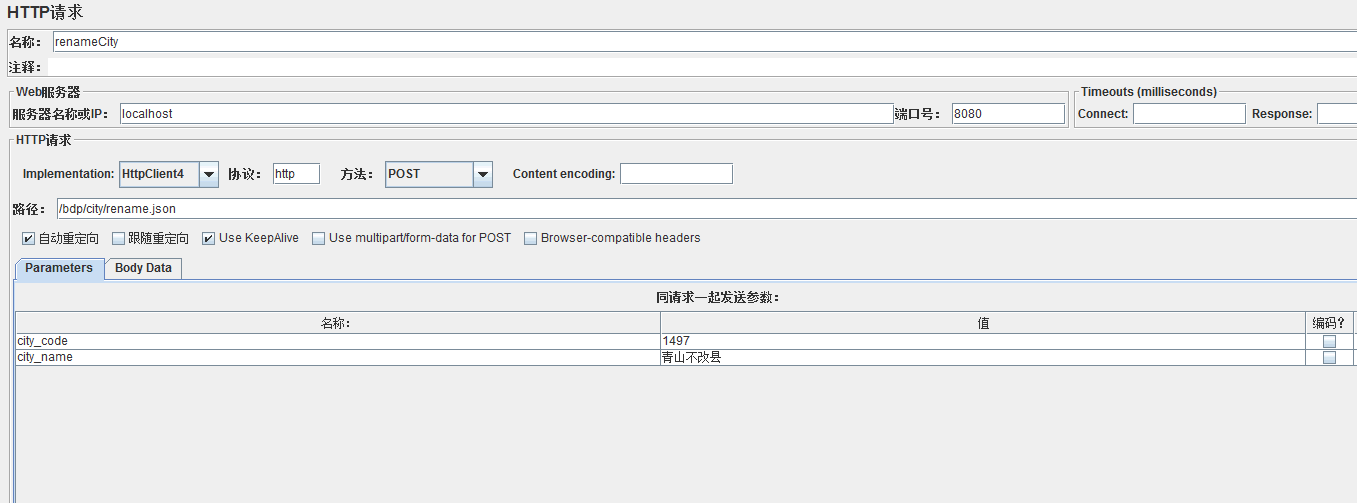
之后再看 Redis 存储:

searchCity 方法的缓存也已被清理,renameCity 方法的缓存也奏效。
7. 注意事项
- 要缓存的 Java 对象必须实现 Serializable 接口,因为 Spring 会将对象先序列化再存入 Redis,比如本文中的 com.defonds.bdp.city.bean.City 类,如果不实现 Serializable 的话将会遇到类似这种错误:nested exception is java.lang.IllegalArgumentException: DefaultSerializer requires a Serializable payload but received an object of type [com.defonds.bdp.city.bean.City]]。
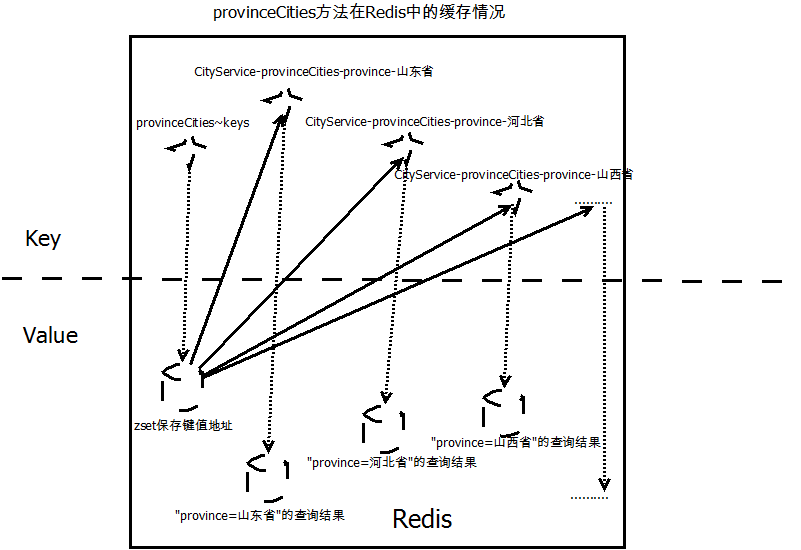
- 缓存的生命周期我们可以配置,然后托管 Spring CacheManager,不要试图通过 redis-cli 命令行去管理缓存。比如 provinceCities 方法的缓存,某个省份的查询结果会被以 key-value 的形式存放在 Redis,key 就是我们刚才自定义生成的 key,value 是序列化后的对象,这个 key 会被放在 key 名为 provinceCities~keys key-value 存储中,参考下图"provinceCities 方法在 Redis 中的缓存情况"。可以通过 redis-cli 使用 del 命令将 provinceCities~keys 删除,但每个省份的缓存却不会被清除。
- CacheManager 必须设置缓存过期时间,否则缓存对象将永不过期,这样做的原因如上,避免一些野数据“永久保存”。此外,设置缓存过期时间也有助于资源利用最大化,因为缓存里保留的永远是热点数据。
- 缓存适用于读多写少的场合,查询时缓存命中率很低、写操作很频繁等场景不适宜用缓存。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Spring整合Redis完整实例代码
做过大型软件系统的同学都知道,随着系统数据越来越庞大,越来越复杂,随之带来的问题就是系统性能越来越差,尤其是频繁操作数据库带来的性能损耗更为严重.很多业绩大牛为此提出了众多的解决方案和开发了很多框架以优化这种频繁操作数据库所带来的性能损耗,其中,尤为突出的两个缓存服务器是Memcached和Redis.今天,我们不讲Memcached和Redis本身,这里主要为大家介绍如何使spring与Redis整合. 1.pom构建 <project xmlns="http://maven.apach
-
Spring-data-redis操作redis知识总结
什么是spring-data-redis spring-data-redis是spring-data模块的一部分,专门用来支持在spring管理项目对redis的操作,使用java操作redis最常用的是使用jedis,但并不是只有jedis可以使用,像jdbc-redis,jredis也都属于redis的java客户端,他们之间是无法兼容的,如果你在一个项目中使用了jedis,然后后来决定弃用掉改用jdbc-redis就比较麻烦了,spring-data-redis提供了redis的java客
-
详解Spring Boot使用redis实现数据缓存
基于spring Boot 1.5.2.RELEASE版本,一方面验证与Redis的集成方法,另外了解使用方法. 集成方法 1.配置依赖 修改pom.xml,增加如下内容. <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 2.配置R
-

详解redis与spring的整合(使用缓存)
1.实现目标 通过redis缓存数据.(目的不是加快查询的速度,而是减少数据库的负担) 2.所需jar包 注意:jdies和commons-pool两个jar的版本是有对应关系的,注意引入jar包是要配对使用,否则将会报错.因为commons-pooljar的目录根据版本的变化,目录结构会变.前面的版本是org.apache.pool,而后面的版本是org.apache.pool2... 3.redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的val
-
详解java之redis篇(spring-data-redis整合)
1,利用spring-data-redis整合 项目使用的pom.xml: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/ma
-
详解Redis 缓存 + Spring 的集成示例
<整合 spring 4(包括mvc.context.orm) + mybatis 3 示例>一文简要介绍了最新版本的 Spring MVC.IOC.MyBatis ORM 三者的整合以及声明式事务处理.现在我们需要把缓存也整合进来,缓存我们选用的是 Redis,本文将在该文示例基础上介绍 Redis 缓存 + Spring 的集成. 1. 依赖包安装 pom.xml 加入: <!-- redis cache related.....start --> <dependency
-
详解redis缓存与数据库一致性问题解决
数据库与缓存读写模式策略 写完数据库后是否需要马上更新缓存还是直接删除缓存? (1).如果写数据库的值与更新到缓存值是一样的,不需要经过任何的计算,可以马上更新缓存,但是如果对于那种写数据频繁而读数据少的场景并不合适这种解决方案,因为也许还没有查询就被删除或修改了,这样会浪费时间和资源 (2).如果写数据库的值与更新缓存的值不一致,写入缓存中的数据需要经过几个表的关联计算后得到的结果插入缓存中,那就没有必要马上更新缓存,只有删除缓存即可,等到查询的时候在去把计算后得到的结果插入到缓存中即可. 所
-
详解Redis缓存穿透/击穿/雪崩原理及其解决方案
目录 1.简介 2.缓存穿透 2.1描述 2.2解决方案 3.缓存击穿 3.1描述 3.2解决方案 4.缓存雪崩 4.1描述 4.1解决方案 5.布隆过滤器 5.1描述 5.2数据结构 5.3"一定不在集合中" 5.4"可能在集合中" 5.5"删除困难" 5.6为什么不使用HashMap呢? 1. 简介 如图所示,一个正常的请求 1.客户端请求张铁牛的博客. 2.服务首先会请求redis,查看请求的内容是否存在. 3.redis将请求结果返回给服
-
详解Redis 缓存删除机制(源码解析)
删除的范围 过期的 key 在内存满了的情况下,如果继续执行 set 等命令,且所有 key 都没有过期,那么会按照缓存淘汰策略选中的 key 过期删除 redis 中设置了过期时间的 key 会单独存储一份 typedef struct redisDb { dict *dict; // 所有的键值对 dict *expires; //设置了过期时间的键值对 // ... } redisDb; 设置有效期 Redis 中有 4 个命令可以给 key 设置过期时间,分别是 expire pexpi
-
详解Quartz 与 Spring框架集成的三种方式
XML+ Spring MVC 版本 POM文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd
-
Spring Cache+Redis缓存数据的实现示例
目录 1.为什么使用缓存 2.常用的缓存注解 2.1 @Cacheable 2.2 @CacheEvict 2.3.@Cacheput 2.4.@Caching 2.5.@CacheConfig 3.SpringBoot缓存支持 4.项目继承Spring Cache+Redis 4.1 添加依赖 4.2 配置类 4.3 添加redis配置 4.4 接口中使用缓存注解 4.5 缓存效果测试 1.为什么使用缓存 我们知道内存的读取速度远大于硬盘的读取速度.当需要重复地获取相同数据时,一次一次地请
-
详解高性能缓存Caffeine原理及实战
目录 一.简介 二.Caffeine 原理 2.1.淘汰算法 2.1.1.常见算法 2.1.2.W-TinyLFU 算法 2.2.高性能读写 2.2.1.读缓冲 2.2.2.写缓冲 三.Caffeine 实战 3.1.配置参数 3.2.项目实战 四.总结 一.简介 下面是Caffeine 官方测试报告. 由上面三幅图可见:不管在并发读.并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件. 本文先介绍 Caffeine 实现原理,再讲解如何在项目中使用 Caffe
-
详解Redis中key的命名规范和值的命名规范
数据库中得热点数据key命名惯例 表名:主键名:主键值:字段名 例如 user:id:0001:name 例如 user:id:0002:name 例如 order:id:s2002:price 上面的key对应的值则可以是 存放的方式 key value 优点 单独的key:value形式 order:id:s2002:price 2000 方便简单的操作,例如incr自增或自减 json格式 user:id:0001 {id:0001,name:"张三"} 方便一次性存和取数据,但
-
详解Redis主从复制实践
复制简介 Redis 作为一门非关系型数据库,其复制功能和关系型数据库(MySQL)来说,功能其实都是差不多,无外乎就是实现的原理不同.Redis 的复制功能也是相对于其他的内存性数据库(memcached)所具备特有的功能. Redis 复制功能主要的作用,是集群.分片功能实现的基础:同时也是 Redis 实现高可用的一种策略,例如解决单机并发问题.数据安全性等等问题. 服务介绍 在本文环境演示中,有一台主机,启动了两个 Redis 示例. 实现方式 Redis 复制实现方式分为下面三种方式: