基于Java回顾之集合的总结概述
Java中的集合主要集中在2部分,一部分是java.util包中,一部分是java.util.concurrent中,后者是在前者的基础上,定义了一些实现了同步功能的集合。
这篇文章主要关注java.util下的各种集合对象。Java中的集合对象可以粗略的分为3类:List、Set和Map。对应的UML图如下(包括了java.util下大部分的集合对象):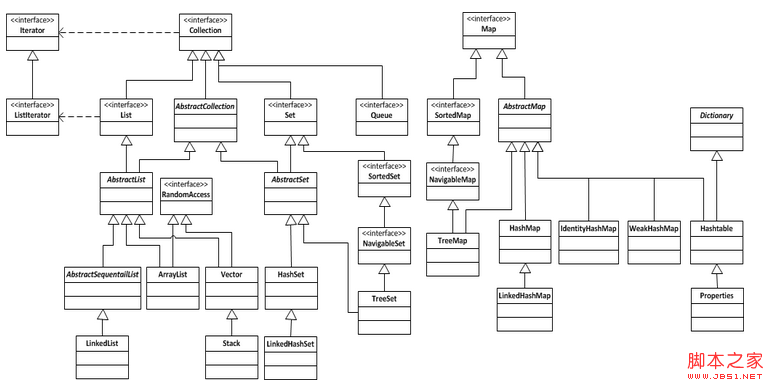
Collection概述
Java集合中的List和Set都从Collection出来,它是一个学习集合很不错的入口,它包含了集合中通常需要有的操作:
添加元素:add/addAll
清空集合:clear
删除元素:remove/removeAll
判断集合中是否包含某元素:contains/containsAll
判断集合是否为空:isEmpty
计算集合中元素的个数:size
将集合转换为数组:toArray
获取迭代器:iterator
我们来看一个简单的例子,下面的代码会返回一个集合,集合中的元素是随机生成的整数:
代码如下:
private static Collection initCollection()
{
Collection<Integer> collection = new ArrayList<Integer>();
Random r = new Random();
for (int i = 0 ; i < 5; i++)
{
collection.add(new Integer(r.nextInt(100)));
}
return collection;
}
在对集合进行操作的过程中,遍历是一个经常使用的操作,我们可以使用两种方式对集合进行遍历:
1) 使用迭代器对集合进行遍历。正如上面描述Collection接口时所说,所有集合都会有一个迭代器,我们可以用它来遍历集合。
代码如下:
private static void accessCollectionByIterator(Collection<Integer> collection)
{
Iterator<Integer> iterator = collection.iterator();
System.out.println("The value in the list:");
while(iterator.hasNext())
{
System.out.println(iterator.next());
}
}
private static void accessCollectionByFor(Collection<Integer> collection)
{
System.out.println("The value in the list:");
for(Integer value : collection)
{
System.out.println(value);
}
}
List
Java中的List是对数组的有效扩展,它是这样一种结构,如果不使用泛型,它可以容纳任何类型的元素,如果使用泛型,那么它只能容纳泛型指定的类型的元素。和数组相比,List的容量是可以动态扩展的。
List中的元素是可以重复的,里面的元素是“有序”的,这里的“有序”,并不是排序的意思,而是说我们可以对某个元素在集合中的位置进行指定。
List中常用的集合对象包括:ArrayList、Vector和LinkedList,其中前两者是基于数组来进行存储,后者是基于链表进行存储。其中Vector是线程安全的,其余两个不是线程安全的。
List中是可以包括null的,即使是使用了泛型。
ArrayList可能是我们平时用到的最多的集合对象了,在上述的示例代码中,我们也是使用它来实例化一个Collection对象,在此不再赘述。
Vector
Vector的示例如下,首先我们看如何生成和输出Vector:
代码如下:
private static void vectorTest1()
{
List<Integer> list = new Vector<Integer>();
for (int i = 0 ; i < 5; i++)
{
list.add(new Integer(100));
}
list.add(null);
System.out.println("size of vector is " + list.size());
System.out.println(list);
}
它的元素中,既包括了重复元素,也包括了null,输出结果如下:
代码如下:
size of vector is 6
[100, 100, 100, 100, 100, null]
下面的示例,演示了Vector中的一些常用方法:
代码如下:
private static void vectorTest2()
{
Vector<Integer> list = new Vector<Integer>();
Random r = new Random();
for (int i = 0 ; i < 10; i++)
{
list.add(new Integer(r.nextInt(100)));
}
System.out.println("size of vector is " + list.size());
System.out.println(list);
System.out.println(list.firstElement());
System.out.println(list.lastElement());
System.out.println(list.subList(3, 8));
List<Integer> temp = new ArrayList<Integer>();
for(int i = 4; i < 7; i++)
{
temp.add(list.get(i));
}
list.retainAll(temp);
System.out.println("size of vector is " + list.size());
System.out.println(list);
}
size of vector is 10
[39, 41, 20, 9, 29, 32, 54, 12, 94, 82]
[9, 29, 32, 54, 12]
size of vector is 3
[29, 32, 54]
LinkedList
LinkedList使用链表来存储数据,它的示例代码如下:
代码如下:
LinkedList示例
private static void linkedListTest1()
{
LinkedList<Integer> list = new LinkedList<Integer>();
Random r = new Random();
for (int i = 0 ; i < 10; i++)
{
list.add(new Integer(r.nextInt(100)));
}
list.add(null);
System.out.println("size of linked list is " + list.size());
System.out.println(list);
System.out.println(list.element());
System.out.println(list.getFirst());
System.out.println(list.getLast());
System.out.println(list.peek());
System.out.println(list.peekFirst());
System.out.println(list.peekLast());
System.out.println(list.poll());
System.out.println(list.pollFirst());
System.out.println(list.pollLast());
System.out.println(list.pop());
list.push(new Integer(100));
System.out.println("size of linked list is " + list.size());
System.out.println(list);
}
这里列出了LinkedList常用的各个方法,从方法名可以看出,LinkedList也可以用来实现栈和队列。
size of linked list is 11
[17, 21, 5, 84, 19, 57, 68, 26, 27, 47, null]
null
null
null
size of linked list is 8
[100, 84, 19, 57, 68, 26, 27, 47]
Set
Set 和List类似,都是用来存储单个元素,单个元素的数量不确定。但Set不能包含重复元素,如果向Set中插入两个相同元素,那么后一个元素不会被插入。
Set可以大致分为两类:不排序Set和排序Set,不排序Set包括HashSet和LinkedHashSet,排序Set主要指TreeSet。其中HashSet和LinkedHashSet可以包含null。
HashSet
HashSet是由Hash表支持的一种集合,它不是线程安全的。
我们来看下面的示例,它和Vector的第一个示例基本上是相同的:
代码如下:
private static void hashSetTest1()
{
Set<Integer> set = new HashSet<Integer>();
for (int i = 0; i < 3; i++)
{
set.add(new Integer(100));
}
set.add(null);
System.out.println("size of set is " + set.size());
System.out.println(set);
}
这里,HashSet中既包含了重复元素,又包含了null,和Vector不同,这里的输出结果如下:
代码如下:
size of set is 2
[null, 100]
对于HashSet是如何判断两个元素是否是重复的,我们可以深入考察一下。Object中也定义了equals方法,对于HashSet中的元素,它是根据equals方法来判断元素是否相等的,为了证明这一点,我们可以定义个“不正常”的类型:
代码如下:
定义MyInteger对象
class MyInteger
{
private Integer value;
public MyInteger(Integer value)
{
this.value = value;
}
public String toString()
{
return String.valueOf(value);
}
public int hashCode()
{
return 1;
}
public boolean equals(Object obj)
{
return true;
}
}
可以看到,对于MyInteger来说,对于任意两个实例,我们都认为它是不相等的。
private static void hashSetTest2()
{
Set<MyInteger> set = new HashSet<MyInteger>();
for (int i = 0; i < 3; i++)
{
set.add(new MyInteger(100));
}
System.out.println("size of set is " + set.size());
System.out.println(set);
}
size of set is 3
[100, 100, 100]
可以看到,现在HashSet里有“重复”元素了,但对于MyInteger来说,它们不是“相同”的。
TreeSet
TreeSet是支持排序的一种Set,它的父接口是SortedSet。
我们首先来看一下TreeSet都有哪些基本操作:
代码如下:
private static void treeSetTest1()
{
TreeSet<Integer> set = new TreeSet<Integer>();
Random r = new Random();
for (int i = 0 ; i < 5; i++)
{
set.add(new Integer(r.nextInt(100)));
}
System.out.println(set);
System.out.println(set.first());
System.out.println(set.last());
System.out.println(set.descendingSet());
System.out.println(set.headSet(new Integer(50)));
System.out.println(set.tailSet(new Integer(50)));
System.out.println(set.subSet(30, 60));
System.out.println(set.floor(50));
System.out.println(set.ceiling(50));
}
[8, 42, 48, 49, 53]
[53, 49, 48, 42, 8]
[8, 42, 48, 49]
[53]
[42, 48, 49, 53]
TreeSet中的元素,一般都实现了Comparable接口,默认情况下,对于Integer来说,SortedList是采用升序来存储的,我们也可以自定义Compare方式,例如以降序的方式来存储。
定义MyInteger2对象
class MyInteger2 implements Comparable
{
public int value;
public MyInteger2(int value)
{
this.value = value;
}
public int compareTo(Object arg0)
{
MyInteger2 temp = (MyInteger2)arg0;
if (temp == null) return -1;
if (temp.value > this.value)
{
return 1;
}
else if (temp.value < this.value)
{
return -1;
}
return 0;
}
public boolean equals(Object obj)
{
return compareTo(obj) == 0;
}
public String toString()
{
return String.valueOf(value);
}
}
private static void treeSetTest2()
{
TreeSet<Integer> set1 = new TreeSet<Integer>();
TreeSet<MyInteger2> set2 = new TreeSet<MyInteger2>();
Random r = new Random();
for (int i = 0 ; i < 5; i++)
{
int value = r.nextInt(100);
set1.add(new Integer(value));
set2.add(new MyInteger2(value));
}
System.out.println("Set1 as below:");
System.out.println(set1);
System.out.println("Set2 as below:");
System.out.println(set2);
}
Set1 as below:
[13, 41, 42, 45, 61]
Set2 as below:
[61, 45, 42, 41, 13]
Map
Map中存储的是“键值对”,和Set类似,Java中的Map也有两种:排序的和不排序的,不排序的包括HashMap、Hashtable和LinkedHashMap,排序的包括TreeMap。
非排序Map
HashMap和Hashtable都是采取Hash表的方式进行存储,HashMap不是线程安全的,Hashtable是线程安全的,我们可以把HashMap看做是“简化”版的Hashtable。
HashMap是可以存储null的,无论是对Key还是对Value。Hashtable是不可以存储null的。
无论HashMap还是Hashtable,我们观察它的构造函数,就会发现它可以有两个参数:initialCapacity和loadFactor,默认情况下,initialCapacity等于16,loadFactor等于0.75。这和Hash表中可以存放的元素数目有关系,当元素数目超过initialCapacity*loadFactor时,会触发rehash方法,对hash表进行扩容。如果我们需要向其中插入过多元素,需要适当调整这两个参数。
private static void hashMapTest1()
{
Map<Integer,String> map = new HashMap<Integer, String>();
map.put(new Integer(1), "a");
map.put(new Integer(2), "b");
map.put(new Integer(3), "c");
System.out.println(map);
System.out.println(map.entrySet());
System.out.println(map.keySet());
System.out.println(map.values());
}
{1=a, 2=b, 3=c}
[1=a, 2=b, 3=c]
[1, 2, 3]
[a, b, c]
private static void hashMapTest2()
{
Map<Integer,String> map = new HashMap<Integer, String>();
map.put(null, null);
map.put(null, null);
map.put(new Integer(4), null);
map.put(new Integer(5), null);
System.out.println(map);
System.out.println(map.entrySet());
System.out.println(map.keySet());
System.out.println(map.values());
}
{null=null, 4=null, 5=null}
[null=null, 4=null, 5=null]
[null, 4, 5]
[null, null, null]
接下来我们演示Hashtable,和上述两个示例基本上完全一样(代码不再展开):
代码如下:
Hashtable示例
private static void hashTableTest1()
{
Map<Integer,String> table = new Hashtable<Integer, String>();
table.put(new Integer(1), "a");
table.put(new Integer(2), "b");
table.put(new Integer(3), "c");
System.out.println(table);
System.out.println(table.entrySet());
System.out.println(table.keySet());
System.out.println(table.values());
}
private static void hashTableTest2()
{
Map<Integer,String> table = new Hashtable<Integer, String>();
table.put(null, null);
table.put(null, null);
table.put(new Integer(4), null);
table.put(new Integer(5), null);
System.out.println(table);
System.out.println(table.entrySet());
System.out.println(table.keySet());
System.out.println(table.values());
}
{3=c, 2=b, 1=a}
[3=c, 2=b, 1=a]
[3, 2, 1]
[c, b, a]
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Unknown Source)
at sample.collections.MapSample.hashTableTest2(MapSample.java:61)
at sample.collections.MapSample.main(MapSample.java:11)
可以很清楚的看到,当我们试图将null插入到hashtable中时,报出了空指针异常。
排序Map
排序Map主要是指TreeMap,它对元素增、删、查操作时的时间复杂度都是O(log(n))。它不是线程安全的。
它的特点和TreeSet非常像,这里不再赘述。
相关推荐
-
javascript列表框操作函数集合汇总
复制代码 代码如下: <script language="javascript"> /* 列表框互相操作函数集 */ //描述: 添加不重复列表框元素 function selAdd( srcList, dstList ) { var selectedIndex = new Array(); var count = 0; for ( i=0; i<srcList.options.length; i++ ){ if ( srcList.optio
-
java如何对map进行排序详解(map集合的使用)
今天做统计时需要对X轴的地区按照地区代码(areaCode)进行排序,由于在构建XMLData使用的map来进行数据统计的,所以在统计过程中就需要对map进行排序. 一.简单介绍Map 在讲解Map排序之前,我们先来稍微了解下map.map是键值对的集合接口,它的实现类主要包括:HashMap,TreeMap,Hashtable以及LinkedHashMap等.其中这四者的区别如下(简单介绍): HashMap:我们最常用的Map,它根据key的HashCode 值来存储数据,根据key可以直接
-
java集合求和最大值最小值示例分享
复制代码 代码如下: package com.happyelements.athene.game.util; import static com.google.common.base.Preconditions.checkNotNull; import java.util.Collection; import com.google.common.collect.Lists; /** * Math工具类 * * @version 1.0 * @since 1.0 */public class M
-
java实现高效的枚举元素集合示例
思路分析:可以通过为EnumSet指定类型,该类型即为在同一包中定义的枚举类.使用EnumSet类的add()方法添加元素,使用EnumSet类的remove()方法删除元素,使用EnumSet类的complementOf()方法获取对象的全部,使用EnumSet类的range()方法获取指定范围的元素. 代码如下: 复制代码 代码如下: package cn.edu.xidian.crytoll;public enum Weeks { MONDAY, TUESDAY, WEDNESDAY
-
java去除集合中重复元素示例分享 java去除重复
复制代码 代码如下: class ArrayListTest1 { public static void main(String[] args) { ArrayList al = new ArrayList(); al.add("java03"); al.add("java03"); al.add("java01"); al.add("java02")
-

Java集合类中文介绍
Java集合是java提供的工具包,包含了常用的数据结构:集合.链表.队列.栈.数组.映射等.Java集合工具包位置是java.util.*Java集合主要可以划分为4个部分:List列表.Set集合.Map映射.工具类(Iterator迭代器.Enumeration枚举类.Arrays和Collections)..Java集合工具包框架图(如下):大致说明:看上面的框架图,先抓住它的主干,即Collection和Map.1 Collection是一个接口,是高度抽象出来的集合,它包含了集合的基
-
Java常用排序算法及性能测试集合
现在再回过头理解,结合自己的体会, 选用最佳的方式描述这些算法,以方便理解它们的工作原理和程序设计技巧.本文适合做java面试准备的材料阅读. 先附上一个测试报告: Array length: 20000bubbleSort : 766 msbubbleSortAdvanced : 662 msbubbleSortAdvanced2 : 647 msselectSort : 252 msinsertSort : 218 msinsertSortAdvanced : 127 msinsertSor
-
java集合map取key使用示例 java遍历map
复制代码 代码如下: for (Iterator i = keys.iterator(); i.hasNext() { String key = (String) i.next(); String value = (String) map.get(key); text+=key + " = " + value; } 复制代码 代码如下: <span style="border-coll
-
Java实现Map集合二级联动示例
Map集合可以保存键值映射关系,这非常适合本实例所需要的数据结构,所有省份信息可以保存为Map集合的键,而每个键可以保存对应的城市信息,本实例就是利用Map集合实现了省市级联选择框,当选择省份信息时,将改变城市下拉选择框对应的内容. 思路分析: 1. 创建全国(省,直辖市,自治区)映射集合,即LinkedHashMap对象,使用Map接口的put()方法向集合中添加指定的省与城市的映射关系,其中值为String型一维数组. 代码如下: CityMap.java 复制代码 代码如下: import
-
基于Java回顾之集合的总结概述
Java中的集合主要集中在2部分,一部分是java.util包中,一部分是java.util.concurrent中,后者是在前者的基础上,定义了一些实现了同步功能的集合. 这篇文章主要关注java.util下的各种集合对象.Java中的集合对象可以粗略的分为3类:List.Set和Map.对应的UML图如下(包括了java.util下大部分的集合对象):Collection概述 Java集合中的List和Set都从Collection出来,它是一个学习集合很不错的入口,它包含了集合中通常需要有
-
基于Java回顾之多线程同步的使用详解
首先阐述什么是同步,不同步有什么问题,然后讨论可以采取哪些措施控制同步,接下来我们会仿照回顾网络通信时那样,构建一个服务器端的"线程池",JDK为我们提供了一个很大的concurrent工具包,最后我们会对里面的内容进行探索. 为什么要线程同步? 说到线程同步,大部分情况下, 我们是在针对"单对象多线程"的情况进行讨论,一般会将其分成两部分,一部分是关于"共享变量",一部分关于"执行步骤". 共享变量 当我们在线程对象(Run
-
基于Java回顾之JDBC的使用详解
尽管在实际开发过程中,我们一般使用ORM框架来代替传统的JDBC,例如Hibernate或者iBatis,但JDBC是Java用来实现数据访问的基础,掌握它对于我们理解Java的数据操作流程很有帮助. JDBC的全称是Java Database Connectivity. JDBC对数据库进行操作的流程:•连接数据库•发送数据请求,即传统的CRUD指令•返回操作结果集JDBC中常用的对象包括:•ConnectionManager•Connection•Statement•CallableStat
-
基于Java回顾之反射的使用分析
反射可以帮助我们查看指定类型中的信息.创建类型的实例,调用类型的方法.我们平时使用框架,例如Spring.EJB.Hibernate等都大量的使用了反射技术.反射简单示例 下面来演示反射相关的基本操作 首先是基础代码,我们定义一个接口及其实现,作为我们反射操作的目标: 复制代码 代码如下: interface HelloWorldService { void sayHello(String name); } class MyHelloWorld implements HelloWorld
-
基于Java回顾之多线程详解
线程是操作系统运行的基本单位,它被封装在进程中,一个进程可以包含多个线程.即使我们不手动创造线程,进程也会有一个默认的线程在运行. 对于JVM来说,当我们编写一个单线程的程序去运行时,JVM中也是有至少两个线程在运行,一个是我们创建的程序,一个是垃圾回收. 线程基本信息 我们可以通过Thread.currentThread()方法获取当前线程的一些信息,并对其进行修改. 我们来看以下代码: 复制代码 代码如下: 查看并修改当前线程的属性 String name = Thread.currentT
-
基于Java回顾之I/O的使用详解
工作后,使用的技术随着项目的变化而变化,时而C#,时而Java,当然还有其他一些零碎的技术.总体而言,C#的使用时间要更长一些,其次是Java.我本身对语言没有什么倾向性,能干活的语言,就是好语言.而且从面向对象的角度来看,我觉得C#和Java对我来说,没什么区别. 这篇文章主要回顾Java中和I/O操作相关的内容,I/O也是编程语言的一个基础特性,Java中的I/O分为两种类型,一种是顺序读取,一种是随机读取. 我们先来看顺序读取,有两种方式可以进行顺序读取,一种是InputStream/Ou
-
基于Java回顾之网络通信的应用分析
TCP连接 TCP的基础是Socket,在TCP连接中,我们会使用ServerSocket和Socket,当客户端和服务器建立连接以后,剩下的基本就是对I/O的控制了. 我们先来看一个简单的TCP通信,它分为客户端和服务器端. 客户端代码如下: 复制代码 代码如下: 简单的TCP客户端 import java.net.*; import java.io.*; public class SimpleTcpClient { public static void main(String[] args
-
基于Java ORM框架的使用详解
ORM框架不是一个新话题,它已经流传了很多年.它的优点在于提供了概念性的.易于理解的数据模型,将数据库中的表和内存中的对象建立了很好的映射关系.我们在这里主要关注Java中常用的两个ORM框架:Hibernate和iBatis.下面来介绍这两个框架简单的使用方法,如果将来有时间,我会深入的写一些更有意思的相关文章.HibernateHibernate是一个持久化框架和ORM框架,持久化和ORM是两个有区别的概念,持久化注重对象的存储方法是否随着程序的退出而消亡,ORM关注的是如何在数据库表和内存
-
基于Java中的数值和集合详解
数组array和集合的区别: (1) 数值是大小固定的,同一数组只能存放一样的数据. (2) java集合可以存放不固定的一组数据 (3) 若程序事不知道究竟需要多少对象,需要在空间不足时自动扩增容量,则需要使用容器类库,array不适用 数组转换为集合: Arrays.asList(数组) 示例: int[] arr = {1,3,4,6,6}; Arrays.asList(arr); for(int i=0;i<arr.length;i++){ System.out.println(arr[
-
基于java集合中的一些易混淆的知识点(详解)
(一) collection和collections 这两者均位于java.util包下,不同的是: collection是一个集合接口,有ListSet等常见的子接口,是集合框架图的第一个节点,,提供了对集合对象进行基本操作的一系列方法. 常见的方法有: boolean add(E e) 往容器中添加元素:int size() 返回collection的元素数:boolean isEmpty() 判断此容器是否为空: boolean contains(Object o) 如果此collecti