对python_discover方法遍历所有执行的用例详解
当我们写了一个单个py的测试文件时直接运行就ok了,但当我们有很多很多个这样的py时,难道要一个一个的点击来运行吗,当然不是。我们可以通过discover方法来找到所有的用例。
下面直接举例说明discover用法:
一、 准备工作
目录结构:

DiscoverCase.py 文件代码:
import unittest import os def discover_case(case_dir): # 待执行用例的目录 testcase = unittest.TestSuite() discover = unittest.defaultTestLoader.discover(case_dir,pattern="*.py",top_level_dir=None) # discover方法筛选出来的用例,循环添加到测试套件中 print(discover) for test_suite in discover: for test_case in test_suite: print(test_case) # 添加用例到testcase #testcase.addTests(test_case) testcase.addTests(test_case) return(testcase) path = os.path.join(os.getcwd(), "测试用例") case = discover_case(case_dir=path) print(case)
Test1代码(test2~4代码基本相同):
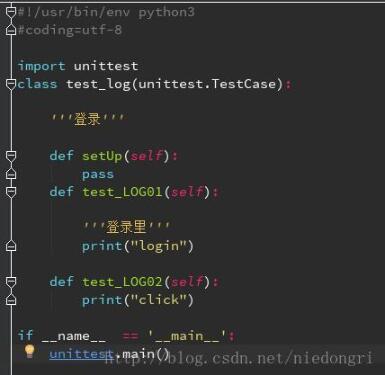
注意:每个testcase里面的执行用例(即以test开头的函数)必现大于或等于两个,不然会报错。
二、写好这些后我们就直接跑程序看结果
运行后用例的文件名、类名、函数名都会遍历出来

是不是很简单啊。
注意:如果用例名称全为中文是不可以加载的到的,必须以字母开始,比如“i登录.py”
这样是可以被加载到的,如果直接写”登录.py”这样是不能被加载到的。
以上这篇对python_discover方法遍历所有执行的用例详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python中pytest收集用例规则与运行指定用例详解
前言 上篇文章相信大家已经了解了pytest在cmd下结合各种命令行参数如何运行测试用例,并输出我们想要看到的信息.那么今天会讲解一下pytest是如何收集我们写好的用例?我们又有哪些方式来运行单个用例或者批量运行用例呢?下面将为大家一一解答! pytest收集用例原理分析 首先我们按照如下目录结构新建我们的项目 [pyttest搜索测试用例的规则] |[测试用例目录1] | |__init__.py | |test_测试模块1.py | |test_测试模块2.py |[测试用例目录2] |
-
python logging类库使用例子
一.简单使用 复制代码 代码如下: def TestLogBasic(): import logging logging.basicConfig(filename = 'log.txt', filemode = 'a', level = logging.NOTSET, format = '%(asctime)s - %(levelname)s: %(message)s') logging.debug('this is a message') logging.inf
-
Python中的CURL PycURL使用例子
在Linux上有个常用的命令 curl(非常好用),支持curl的就是大名鼎鼎的libcurl库:libcurl是功能强大的,而且是非常高效的函数库.libcurl除了提供本身的C API之外,还有多达40种编程语言的Binding,这里介绍的PycURL就是libcurl的Python binding.在Python中对网页进行GET/POST等请求,当需要考虑高性能的时候,libcurl是非常不错的选择,一般来说会比liburl.liburl2快不少,可能也会比Requests的效率更高.特
-
python selenium执行所有测试用例并生成报告的方法
直接上代码. # -*- coding: utf-8 -*- import time import os import os.path import re import unittest import HTMLTestRunner import shutil shutil.copyfile("setting.ini","../setting.ini") casepaths = [] def createsuite(casepath): testunit = unit
-
Python random模块(获取随机数)常用方法和使用例子
random.randomrandom.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 random.uniformrandom.uniform(a, b),用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限.如果a > b,则生成的随机数n: a <= n <= b.如果 a <b, 则 b <= n <= a 复制代码 代码如下: print random.uniform(10, 20)print rand
-
python自动化报告的输出用例详解
1.设计简单的用例 2.设计用例 以TestBaiduLinks.py命名 # coding:utf-8 from selenium import webdriver import unittest class BaiduLinks(unittest.TestCase): def setUp(self): base_url = 'https://www.baidu.com' self.driver = webdriver.Chrome() self.driver.implicitly_wait(
-
Python Nose框架编写测试用例方法
1. 关于Nose nose项目是于2005年发布的,也就是 py.test改名后的一年.它是由 Jason Pellerin 编写的,支持与 py.test 相同的测试习惯做法,但是这个包更容易安装和维护. nose的口号是:扩展unittest,nose让测试更简单! nose官网:http://nose.readthedocs.io/en/latest/index.html 使用nose框架进行Python项目的自动化测试,可以参考:http://www.cnblogs.com/liaof
-

python自动化测试之从命令行运行测试用例with verbosity
本文实例讲述了python自动化测试之从命令行运行测试用例with verbosity,分享给大家供大家参考.具体如下: 实例文件recipe3.py如下: class RomanNumeralConverter(object): def __init__(self, roman_numeral): self.roman_numeral = roman_numeral self.digit_map = {"M":1000, "D":500, "C"
-
Python装饰器使用示例及实际应用例子
测试1 deco运行,但myfunc并没有运行 复制代码 代码如下: def deco(func): print 'before func' return func def myfunc(): print 'myfunc() called' myfunc = deco(myfunc) 测试2 需要的deco中调用myfunc,这样才可以执行 复制代码 代码如下: def deco(func): print 'before func' func()
-
对python_discover方法遍历所有执行的用例详解
当我们写了一个单个py的测试文件时直接运行就ok了,但当我们有很多很多个这样的py时,难道要一个一个的点击来运行吗,当然不是.我们可以通过discover方法来找到所有的用例. 下面直接举例说明discover用法: 一. 准备工作 目录结构: DiscoverCase.py 文件代码: import unittest import os def discover_case(case_dir): # 待执行用例的目录 testcase = unittest.TestSuite() discove
-
从零开始使用gradle配置即可执行的Hook库详解
目录 背景 本文须知 当前技术背景 底层选择 目标流程图 Transform ASM 封装开始 目标 实现 gradle 定义extension Transform阶段收集信息: 自定义的classvisitor 自定义method visitor 自定义hook操作 总结 背景 有一天,老板突然找到小B说,隐私合规需要我们获取权限前,需要明确授权来意,这个你来跟一下吧!小B此时就可愁了,因为项目权限那么多,每个自己手动加上授权来意提示的话,可能会漏掉很多,工作量也大,这可咋办呀!老B看到小B这
-
MySQL DDL执行方式Online DDL详解
目录 1 引言 2 概述 3 介绍 4 用法 5 两种算法 第一种 Copy 第二种 Inplace 6 执行过程 7 踩坑 8 限制 9 总结 1 引言 一般来说MySQL分为DDL(定义)和DML(操作). DDL:Data Definition Language,即数据定义语言,那相关的定义操作就是DDL,包括:新建.修改.删除等:相关的命令有:CREATE,ALTER,DROP,TRUNCATE截断表内容(开发期,还是挺常用的),COMMENT 为数据字典添加备注. DML:Data M
-
Mysql 5.7.18安装方法及启动MySQL服务的过程详解
MySQL 是一个非常强大的关系型数据库.但有些初学者在安装配置的时候,遇到种种的困难,在此就不说安装过程了,说一下配置过程.在官网下载的MySQL时候,有msi格式和zip格式.Msi直接运行安装即可,zip则解压在自己喜欢的目录地址即可.在安装这两种的时候,都需要配置才能用.以下介绍主要是msi格式默认的地址:C:\Program Files\ mysql-5.7.18-win32. 一.在安装或者解压后,需要配置环境变量,过程如下:我的电脑->属性->高级系统设置->高级->
-
MyBatis 执行动态 SQL语句详解
大家基本上都知道如何使用 MyBatis 执行任意 SQL,使用方法很简单,例如在一个 XXMapper.xml 中: <select id="executeSql" resultType="map"> ${_parameter} </select> 你可以如下调用: sqlSession.selectList("executeSql", "select * from sysuser where enabled
-
Java中遍历ConcurrentHashMap的四种方式详解
这篇文章主要介绍了Java中遍历ConcurrentHashMap的四种方式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 方式一:在for-each循环中使用entries来遍历 System.out.println("方式一:在for-each循环中使用entries来遍历");for (Map.Entry<String, String> entry: map.entrySet()) { System.out.pr
-
SpringMVC的执行流程及组件详解
这篇文章主要介绍了SpringMVC的执行流程及组件详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.核心模块 数据库访问技术与集成:JDBC.XML等 Web与远程调用技术:SpringMVC.WebServlet.WebSocket等 面向切面编程:AOP 基础设施:Tomcat Spring核心容器:Beans.Core.Context.Expression.ContestSupport 测试:Test 二.执行流程 1.用户通过页
-
Spring AOP执行先后顺序实例详解
这篇文章主要介绍了Spring AOP执行先后顺序实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 众所周知,spring声明式事务是基于AOP实现的,那么,如果我们在同一个方法自定义多个AOP,我们如何指定他们的执行顺序呢? 网上很多答案都是指定order,order越小越是最先执行,这种也不能算是错,但有些片面. 配置AOP执行顺序的三种方式: 通过实现org.springframework.core.Ordered接口 @Compo
-
使用Jacoco获取 Java 程序的代码执行覆盖率的步骤详解
Jacoco是Java Code Coverage的缩写,顾名思义,它是获取Java代码执行覆盖率的一个工具,通常用它来获取单元测试覆盖率.它通过分析Java字节码来得到代码执行覆盖率,因此它还可以分析任何基于JVM的语言(如Croovy.Kotlin)的覆盖率.本文不讨论如何用Jacoco获取单元测试的代码覆盖率,而是从Jacoco的原理出发,介绍如何通过Jacoco获取SIT或者UAT的测试覆盖率.更准确来讲,是获取一个应用执行过的代码占总代码的比率.包括字节码指令覆盖率,分支覆盖率,圈复杂
-
python os.system执行cmd指令代码详解
1.执行cmd指令,在cmd输出的内容会直接在控制台输出,返回结果为0表示执行成功. 2.在调用完shell脚本后,返回一个16位的二进制数,低位为杀死所调用脚本的信号号码,高位为脚本的退出状态码. os.system()方法是简单粗暴的执行cmd指令,没有办法获取到cmd输出的内容. 实例 # coding:utf-8 import os os.system("ls") Python如何使用OS模块调用cmd 在os模块中提供了两种调用 cmd 的方法,os.popen() 和 os