易语言获取网页源码的方法
信息爆炸的时代,同样引领者软件产业的不断变化。目前,软件的需求已经不是从单一面向复杂,不单单考虑某一方面的需求而是多方面需求的融合。那么,易语言如何读取网页源码呢?下面,就由MovieClip给大家讲解一下吧!
1、首先,运行“易语言”主程序,弹出“新建工程对话框”选择“Windows窗口程序”然后点击“确定”按钮,进入“Windows窗口程序设计界面”。如下图:

2、接下来,拖放标签组件一个、编辑框组件两个、按钮组件一个及分组框组件一个。将他们放置到合适的位置并将窗口的宽高设置到适当的大小。以确保窗口的简洁美观。如下图:

3、待界面调整完毕之后,将窗口标题、标签标题、分组框标题及按钮标题修改成相应内容,并且将编辑框、按钮组件规范命名。为编写程序代码做准备。

4、接下来就是编写代码了,在“_按钮_获取源码_被单击”事件子程序下,编写如下代码【 编辑框_网页源码.内容 = 到文本 (HTTP读文件 (编辑框_网址.内容)) 】如下图所示:
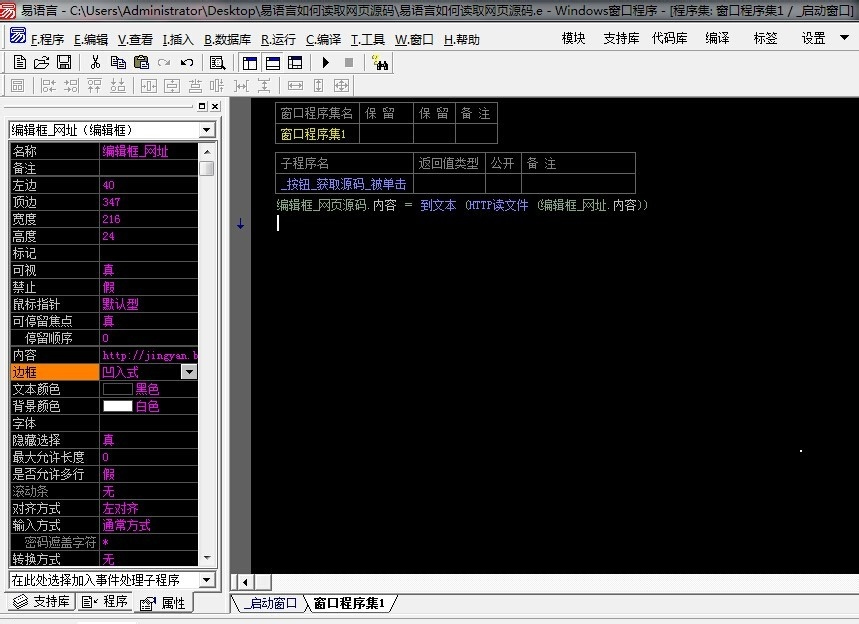
5、待代码编写无误后,进入调试阶段。按下“F5”快捷键运行程序,网址我们以百度经验的网址为例,然后点击“获取源码”按钮,等待程序执行。如图:

6、从网页源码编辑框得到的反馈结果分析,如果源码中出现乱码通常是编码方式的问题。这个时候,我们需要进行转码,就能看到正常的代码了。那么,我们的代码也需要做小的改动。如图:

7、重新测试程序,从网页源码编辑框的反馈结果可以看出,这次读取的网页源码是正确的。所以,MovieClip在这里提醒大家,编写软件或者程序时,一定要反复的调试。至此,易语言读取网页源码的讲解就结束了。感谢大家的阅读。

总结:以上就是通过易语言获取网页源码的相关步骤内容,感谢大家的阅读和学习。
相关推荐
-

易语言修改指定网页为浏览器主页的代码
监控浏览器进程,结束后用 运行(浏览器目录+" "+地址) 来实现主页修改 DLL命令表 .版本 2 .DLL命令 CoInitialize, 整数型, "Ole32.dll" .参数 pvReserved, 整数型 .DLL命令 CoUninitialize, , "Ole32.dll" .DLL命令 RegisterWindowMessageA, 整数型, , "RegisterWindowMessageA" .参数 lp
-
易语言进行网页操作方法
首先展示下功能(看图片) 本代码附加了DLL代码命令,会以不同的颜色标注,也可以全部复制后张贴到易语言新建的一个程序集名中,易语言会智能的分开DLL和子程序. 相关源码: .版本 2 .程序集 网页操作累 .子程序 HTTP读文本, 文本型, 公开, 有可能线程阻塞,请在外部加超时判断 .参数 完整网址, 文本型 .参数 访问方式, 文本型, 可空, "GET" or "POST",为空默认"GET" .参数 代理地址, 文本型, 可空 .参数
-
易语言爬取网页内容方法
写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦! 1.在新建的windos窗口程序中画: 两个编辑框.一个按钮. 再添加模块如图中三步! 我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中. 2.比如我们来取百度某贴吧一个帖子内的内容!如下图中的"跑遍数码城,XXXXX". 我们在该页面上右键---->查看网页源码(或查看源文件). 3.在打开的源文件内容中按CTRL+F组合键查找"跑遍
-
易语言表白网页生成器源码
表白网页生成器 .版本 2 .支持库 iext .支持库 spec .程序集 窗口程序集1 .子程序 _按钮_本地生成_被单击 透明标签3.标题 = "xx提醒您正在生成,,请稍候..." 创建目录 (取运行目录 () + "/本地专用版") 编辑框2.内容 = 子文本替换 (编辑框3.内容, "对方名字", 编辑框_对方名字.内容, , , 真) 延迟 (200) 编辑框5.内容 = 子文本替换 (编辑框2.内容, "自己名字&quo
-
易语言编写网页刷点击程序
用易语言中文程序,做一个简单的网页刷新器,用到时钟组件就可以完成. 1.在百度上下载易语言软件进行安装,通过百度"易语言",得出搜索结果,按照步骤进行正常的软件安装即可. 2.安装完毕之后,打开易语言程序,选择windows窗口程序进行启动 3.在拓展组件中找到超文本浏览框,移动到我们窗口程序中,在地址一栏中填写我们要刷新的网址. 4.添加一个时钟组件,时钟组件属性中的时间周期即是我们要刷新的频率,单位是ms,例如我们设置2000,就是2s刷新一次. 5.双击时钟,跳转到时钟子事件程序
-
易语言网页填表操作
用易语言编程工具编写网页普通填表 1.用IE浏览器打开百度 2.运行精易编程助手,打开[网页分析]按钮 3.拖动蓝色圆形十字到百度首页 4.分析出的详细信息,查看按钮ID 5.点击精易编程助手中的[窗口探测]查看标题 6.打开易语言,创建窗口句柄 新建一个标签.按钮.编辑框 7.代码如下,一定要普通填表初始化 8. 代码如下:.版本 2.程序集 窗口程序集1.程序集变量 句柄, 整数型.子程序 _按钮1_被单击普通填表.初始化 (句柄)普通填表.文本框_写内容 ("1", 编辑框1.内
-
易语言获取网页源码的方法
信息爆炸的时代,同样引领者软件产业的不断变化.目前,软件的需求已经不是从单一面向复杂,不单单考虑某一方面的需求而是多方面需求的融合.那么,易语言如何读取网页源码呢?下面,就由MovieClip给大家讲解一下吧! 1.首先,运行"易语言"主程序,弹出"新建工程对话框"选择"Windows窗口程序"然后点击"确定"按钮,进入"Windows窗口程序设计界面".如下图: 2.接下来,拖放标签组件一个.编辑框组件两
-
python获取整个网页源码的方法
1.Python中获取整个页面的代码: import requests res = requests.get('https://blog.csdn.net/yirexiao/article/details/79092355') res.encoding = 'utf-8' print(res.text) 2.运行结果 实例扩展: from bs4 import BeautifulSoup import time,re,urllib2 t=time.time() websiteurls={} de
-
三种获取网页源码的方法(使用MFC/Socket实现)
第一个方法是使用MFC里面的 <afxinet.h> 复制代码 代码如下: CString GetHttpFileData(CString strUrl){ CInternetSession Session("Internet Explorer", 0); CHttpFile *pHttpFile = NULL; CString strData; CString strClip; pHttpFile = (CHttpFile*)Ses
-
Python爬虫学习之获取指定网页源码
本文实例为大家分享了Python获取指定网页源码的具体代码,供大家参考,具体内容如下 1.任务简介 前段时间一直在学习Python基础知识,故未更新博客,近段时间学习了一些关于爬虫的知识,我会分为多篇博客对所学知识进行更新,今天分享的是获取指定网页源码的方法,只有将网页源码抓取下来才能从中提取我们需要的数据. 2.任务代码 Python获取指定网页源码的方法较为简单,我在Java中使用了38行代码才获取了网页源码(大概是学艺不精),而Python中只用了6行就达到了效果. Python中获取网页
-
asp.net 抓取网页源码三种实现方法
方法1 比较推荐 /// <summary> /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// </summary> /// <param name="url">网页地址" </param> /// <returns>返回网页源文件</returns> public static string GetHtmlSource2(strin
-
C#实现下载网页HTML源码的方法
本文实例讲述了C#实现下载网页HTML源码的方法.分享给大家供大家参考之用.具体方法如下: public static class DownLoad_HTML { private static int FailCount = 0; //记录下载失败的次数 public static string GetHtml(string url) //传入要下载的网址 { string str = string.Empty; try { System.Net.WebRequest request = Sys
-
Python requests模块基础使用方法实例及高级应用(自动登陆,抓取网页源码)实例详解
1.Python requests模块说明 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和POST数据自动编码. 在python内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用Requests可以轻而易举的完成浏览器可有的任何操作. 现代,国际化
-
易语言盗号源码编写及使用方法
易语言盗号源码编写教程 首先你需要开通邮箱.QQ邮箱即可.需要开启QQ邮箱的发信功能.如果是QQ邮箱.开通邮箱后15天内才能使用这个功能,所有推荐大家注册163邮箱.这样又安全.还可以防止软件被人拆解开了不会泄露你的QQ密码.首先上一段代码: .版本 2 .支持库 internet 连接发信服务器 ("smtp@163.com", 25, "你注册的账号", "你的密码", ) 这段代码是连接服务器之后写好你的程序,需要2个编辑框一个当账号框,一
-
Python无法用requests获取网页源码的解决方法
最近在抓取http://skell.sketchengine.eu网页时,发现用requests无法获得网页的全部内容,所以我就用selenium先模拟浏览器打开网页,再获取网页的源代码,通过BeautifulSoup解析后拿到网页中的例句,为了能让循环持续进行,我们在循环体中加了refresh(),这样当浏览器得到新网址时通过刷新再更新网页内容,注意为了更好地获取网页内容,设定刷新后停留2秒,这样可以降低抓不到网页内容的机率.为了减少被封的可能,我们还加入了Chrome,请看以下代码: fro
-
Python3使用requests包抓取并保存网页源码的方法
本文实例讲述了Python3使用requests包抓取并保存网页源码的方法.分享给大家供大家参考,具体如下: 使用Python 3的requests模块抓取网页源码并保存到文件示例: import requests html = requests.get("http://www.baidu.com") with open('test.txt','w',encoding='utf-8') as f: f.write(html.text) 这是一个基本的文件保存操作,但这里有几个值得注意的