Python Pandas 如何shuffle(打乱)数据
在Python里面,使用Pandas里面的DataFrame来存放数据的时候想要把数据集进行shuffle会许多的方法,本文介绍两种比较常用而且简单的方法。
应用情景:
我们有下面以个DataFrame
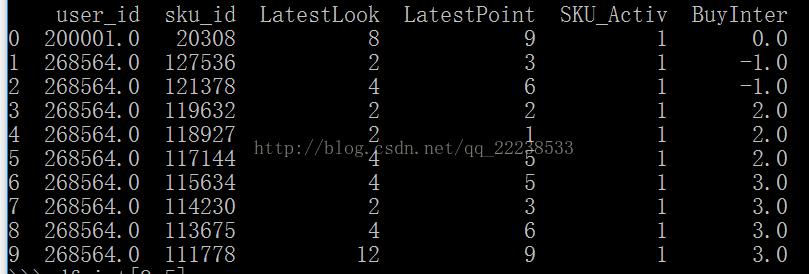
我们可以看到BuyInter的数值是按照0,-1,-1,2,2,2,3,3,3,3这样排列的,我们希望不保持这个次序,但是同时列属性又不能改变,即如下效果:

实现方法:
最简单的方法就是采用pandas中自带的 sample这个方法。
假设df是这个DataFrame
df.sample(frac=1)
这样对可以对df进行shuffle。其中参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3。
有时候,我们可能需要打混后数据集的index(索引)还是按照正常的排序。我们只需要这样操作
df.sample(frac=1).reset_index(drop=True)
-------------------------------------分割线--------------------------------------------------------------
其实,sklearn(机器学习的库)中也有shuffle的方法。
from sklearn.utils import shuffle df = shuffle(df)
另外,numpy库中也有进行shuffle的方法(不建议)
df.iloc[np.random.permutation(len(df))]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pandas数据框,统计某列数据对应的个数方法
现在要解决的问题如下: 我们有一个数据的表 第7列有许多数字,并且是用逗号分隔的,数字又有一个对应的关系: 我们要得到第7列对应关系的统计,就是每一行的第7列a有多少个,b有多少个 好了,我给的解决方法如下: #!/bin/python #-*-coding:UTF-8-*- import pandas as pd import numpy as np dfidspec = pd.read_table("one.txt")#这个是对应关系的文件 dfmgs = pd.read_tabl
-
pandas系列之DataFrame 行列数据筛选实例
一.对DataFrame的认知 DataFrame的本质是行(index)列(column)索引+多列数据. 为了简化理解,我们不妨换个思路- 现实中,为了简化对一件事物的描述,我们会选择几个特征. 例如,从(性别.身高.学历.职业.爱好..)等角度去刻画一个人,这些"角度"即为"特征". 其中,不同的行表示不同的记录:列代表特征,不同记录因各个特征之间的差异而不同. DataFrame默认索引是序号(0,1,2-),可以理解成位置索引.一般我们用id标识不同记录,
-
pandas 对每一列数据进行标准化的方法
两种方式 >>> import numpy as np >>> import pandas as pd Backend TkAgg is interactive backend. Turning interactive mode on. >>> np.random.seed(1) >>> df_test = pd.DataFrame(np.random.randn(4,4)* 4 + 3) >>> df_test 0
-
pandas 使用apply同时处理两列数据的方法
多的不说,看了代码就懂了! df = pd.DataFrame ({'a' : np.random.randn(6), 'b' : ['foo', 'bar'] * 3, 'c' : np.random.randn(6)}) def my_test(a, b): return a + b df['Value'] = df.apply(lambda row: my_test(row['a'], row['c']), axis=1) print df 以上这篇pandas 使用apply同时处理两列
-

Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-
Pandas实现数据类型转换的一些小技巧汇总
前言 Pandas是Python当中重要的数据分析工具,利用Pandas进行数据分析时,确保使用正确的数据类型是非常重要的,否则可能会导致一些不可预知的错误发生. Pandas 的数据类型:数据类型本质上是编程语言用来理解如何存储和操作数据的内部结构.例如,一个程序需要理解你可以将两个数字加起来,比如 5 + 10 得到 15.或者,如果是两个字符串,比如「cat」和「hat」,你可以将它们连接(加)起来得到「cathat」.尚学堂•百战程序员陈老师指出有关 Pandas 数据类型的一个可能令人
-
python pandas消除空值和空格以及 Nan数据替换方法
在人工采集数据时,经常有可能把空值和空格混在一起,一般也注意不到在本来为空的单元格里加入了空格.这就给做数据处理的人带来了麻烦,因为空值和空格都是代表的无数据,而pandas中Series的方法notnull()会把有空格的数据也纳入进来,这样就不能完整地得到我们想要的数据了,这里给出一个简单的方法处理该问题. 方法1: 既然我们认为空值和空格都代表无数据,那么可以先得到这两种情况下的布尔数组. 这里,我们的DataFrame类型的数据集为df,其中有一个变量VIN,那么取得空值和空格的布尔数组
-
pandas DataFrame数据转为list的方法
首先使用np.array()函数把DataFrame转化为np.ndarray(),再利用tolist()函数把np.ndarray()转为list,示例代码如下: # -*- coding:utf-8-*- import numpy as np import pandas as pd data_x = pd.read_csv("E:/Tianchi/result/features.csv",usecols=[2,3,4])#pd.dataframe data_y = pd.read_
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa