Python中文编码知识点
如何用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题。
Python 文件中如果未指定编码,在执行过程会出现报错:
#!/usr/bin/python
print "你好,世界";
以上程序执行输出结果为:
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错。
解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了
注意:#coding=utf-8 的 = 号两边不要空格。
#!/usr/bin/python # -*- coding: UTF-8 -*- print "你好,世界";
输出结果为:

所以如果大家在学习过程中,代码中包含中文,就需要在头部指定编码。
注意:Python3.X 源码文件默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。
注意:如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现类似以下错误信息:
SyntaxError: (unicode error) ‘utf-8' codec can't decode byte 0xc4 in position 0:
invalid continuation byte
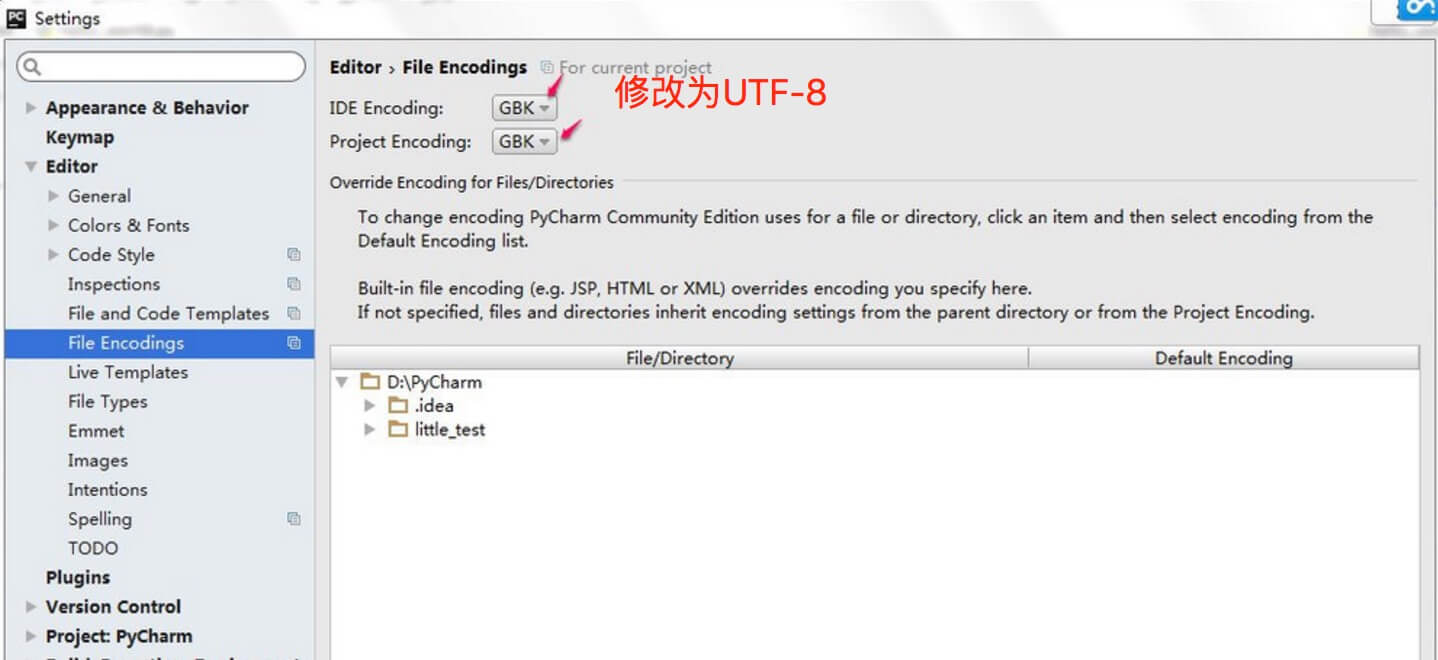
Pycharm 设置步骤:
- 进入 file > Settings,在输入框搜索 encoding。
- 找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为utf-8。
相关推荐
-
python处理中文编码和判断编码示例
下面所说的都是针对python2.7 复制代码 代码如下: #coding:utf-8#chardet 需要下载安装 import chardet#抓取网页htmlline = "http://www.***.com"html_1 = urllib2.urlopen(line,timeout=120).read()#print html_1encoding_dict = chardet.detect(html_1)#print encodingweb_encoding = encodi
-

简单解决Python文件中文编码问题
读写中文 需要读取utf-8编码的中文文件,先利用sublime text软件将它改成无DOM的编码,然后用以下代码: with codecs.open(note_path, 'r+','utf-8') as f: line=f.readline() print line 这样就可以正确地读出文件里面的中文字符了. 同样的,如果要在创建的文件中写入中文,最好也和上面差不多: with codecs.open(st,'a+','utf-8') as book_note: book_note.wri
-
python中文编码问题小结
中文编码问题一直是Python程序设计中很头痛的问题,本文对此较为详细的进行了总结归纳.具体如下: 当字符串是:'\u4e2d\u56fd' >>>s=['\u4e2d\u56fd','\u6e05\u534e\u5927\u5b66'] >>>str=s[0].decode('unicode_escape') #.encode("EUC_KR") >>>print str 中国 当字符串是:' 东亚学团一中' >>
-
在Python中关于中文编码问题的处理建议
字符串是Python中最常用的数据类型,而且很多时候你会用到一些不属于标准ASCII字符集的字符,这时候代码就很可能抛出UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 10: ordinal not in range(128)异常.这种异常在Python中很容易遇到,尤其是在Python2.x中,是一个很让初学者费解头疼的问题.不过,如果你理解了Python的Unicode,并在编码中遵循一定的原则,这种编
-
python中文编码与json中文输出问题详解
前言 python2.x版本的字符编码有时让人很头疼,遇到问题,网上方法可以解决错误,但对原理还是一知半解,本文主要介绍 python 中字符串处理的原理,附带解决 json 文件输出时,显示中文而非 unicode 问题.首先简要介绍字符串编码的历史,其次,讲解 python 对于字符串的处理,及编码的检测与转换,最后,介绍 python 爬虫采取的 json 数据存入文件时中文输出的问题. 参考书籍:Python网络爬虫从入门到实践 by唐松 在python 2或者3 ,字符串编码只有两类
-
Python2.x版本中基本的中文编码问题解决
Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题. Python 文件中如果未指定编码,在执行过程会出现报错: #!/usr/bin/python print "你好,世界"; 以上程序执行输出结果为: File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file te
-
SQLite3中文编码 Python的实现
读取十万多条文本写入SQLite类型数据库,由于文本中存在中文字符,插入到数据库没错,取出时一直是UnicodeDecodeError,导致折腾了一天. 最后的解决方法: Python连接数据时进行如下设置: db=sqlite3.connection("...") db.text_factory=st 另为了python代码中硬编码的中文字符串不出现问题,除了在源码开始添加 # -*- coding:utf-8 -*- 设置python源码的编码为utf-8 import sys r
-
Python中文编码那些事
首先,要明白encode()和decode()的区别 encode()的作用是将Unicode编码的字符串转换为其他编码格式. 例如: st1.encode("utf-8") 这句话的作用是将Unicode编码的st1编码为utf-8编码的字符串 decode()的作用是把其他编码格式的字符串转换成Unicode编码的字符串. 例如: st2.decode("utf-8") 这句话的作用是将utf-8编码的字符串st2解码为Unicode编码的字符串 第二,除Un
-
Python中文编码知识点
如何用 Python 输出 "Hello, World!",英文没有问题,但是如果你输出中文字符"你好,世界"就有可能会碰到中文编码问题. Python 文件中如果未指定编码,在执行过程会出现报错: #!/usr/bin/python print "你好,世界"; 以上程序执行输出结果为: File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in fil
-
详解Python if-elif-else知识点
有的时候,一个 if - else - 还不够用.比如,根据年龄的划分: 条件1:18岁或以上:adult 条件2:6岁或以上:teenager 条件3:6岁以下:kid Python if-elif-else知识点 if age >= 18: print 'adult' else: if age >= 6: print 'teenager' else: print 'kid' 这样写出来,我们就得到了一个两层嵌套的 if - else - 语句.这个逻辑没有问题,但是,如果继续增加条件,比如
-
Python Pandas知识点之缺失值处理详解
前言 数据处理过程中,经常会遇到数据有缺失值的情况,本文介绍如何用Pandas处理数据中的缺失值. 一.什么是缺失值 对数据而言,缺失值分为两种,一种是Pandas中的空值,另一种是自定义的缺失值. 1. Pandas中的空值有三个:np.nan (Not a Number) . None 和 pd.NaT(时间格式的空值,注意大小写不能错),这三个值可以用Pandas中的函数isnull(),notnull(),isna()进行判断. isnull()和notnull()的结果互为取反,isn
-
详解python中文编码问题
目录 1. 在Python中使用中文 1.1 Windows控制台 1.2 Windows IDLE(在Shell上运行) 1.3 在IDLE上运行代码 1.4 Windows Eclipse 1.5 从文件读取中文 1.6 在数据库中使用中文 1.7 在XML中使用中文 1. 在Python中使用中文 在Python中有两种默认的字符串:str和unicode.在Python中一定要注意区分"Unicode字符
-
python 中文编码乱码问题的解决
目录 前言: 一.什么是字符编码. 1.ASCII 2.GB2312 3.Unicode 4.UTF-8 二.Python2中的字符编码 三.decode()与encode()方法 四.一个字符编码的例子 前言: 中文编码问题一直是程序员头疼的问题,而Python2中的字符编码足矣令新手抓狂.本文将尽量用通俗的语言带大家彻底的了解字符编码以及Python2和3中的各种编码问题. 一.什么是字符编码. 要彻底解决字符编码的问题就不能不去了解到底什么是字符编码.计算机从本质上来说只认识二进制中的0和
-
Python 多线程知识点总结及实例用法
Python 多线程 多线程类似于同时执行多个不同程序,多线程运行有如下优点: 使用线程可以把占据长时间的程序中的任务放到后台去处理. 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度 程序的运行速度可能加快 在一些等待的任务实现上如用户输入.文件读写和网络收发数据等,线程就比较有用了.在这种情况下我们可以释放一些珍贵的资源如内存占用等等. 线程在执行过程中与进程还是有区别的.每个独立的进程有一个程序运行的入口.顺序执行序列和程序的出口.
-
Python基础语法(Python基础知识点)
Python与Perl,C和Java语言等有许多相似之处.不过,也有语言之间有一些明确的区别.本章的目的是让你迅速学习Python的语法. 第一个Python程序: 交互模式编程: 调用解释器不经过脚本文件作为参数,显示以下提示: $ python Python 2.6.4 (#1, Nov 11 2014, 13:34:43) [GCC 4.1.2 20120704 (Red Hat 5.6.2-48)] on linux2 Type "help", "copyright&