C++ 单链表的基本操作(详解)
链表一直是面试的高频题,今天先总结一下单链表的使用,下节再总结双向链表的。本文主要有单链表的创建、插入、删除节点等。
1、概念
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。
链表中的数据是以结点来表示的,每个结点的构成:元素 + 指针,元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。如下图:

2、链表的基本操作
SingleList.cpp:
#include "stdafx.h"
#include "SingleList.h"
#include <cstdlib>
#include <iostream>
#include <string.h>
#include <conio.h>
#include <stdio.h>
/*c++实现简单的单链表操作*/
using namespace std;
SingleList::SingleList()
{
int num;
char name[128];
// 创建链表
node *stuList = CreatNode();
PrintList(stuList);
// 插入节点
printf("\n请输入要插入的学生学号和姓名,输入0 0表示结束.");
scanf_s("%d%s", &num, name, 100);
stuList = InsertNode(stuList, num, name);
PrintList(stuList);
// 删除节点
printf("\n请输入要删除的学生学号:");
scanf_s("%d", &num, 100);
stuList = DeleteNode(stuList, num);
PrintList(stuList);
// 逆序
printf("\n逆序后的链表为:\n");
stuList = ReverseList(stuList);
PrintList(stuList);
system("PAUSE");
}
SingleList::~SingleList()
{
}
//建立单链表
node *SingleList::CreatNode()
{
node *head, *p, *s;
int num = 0;
char name[128];
int cycle = 1;
head = (node *)malloc(sizeof(node)); // 为头结点分配内存空间
head->next = nullptr;
p = head; // p指向头节点
while (cycle)
{
printf("\n请输入学生的学号和姓名:");
scanf_s("%d%s", &num, name, 100);
if (num != 0)
{
s = (node *)malloc(sizeof(node));
s->num = num;
memcpy(s->name, name, 128);
printf("%d%s", s->num, s->name);
p->next = s; // 指向新插入的节点
p = s; // p指向当前节点
}
else
{
cycle = 0;
}
}
head = head->next;
p->next = NULL;
printf("头节点学生信息为: %d%s\n", head->num, head->name);
return head;
}
//单链表插入
node *SingleList::InsertNode(node *head, int num, char* name)
{
node *s, *p1, *p2 = NULL;
p1 = head;
s = (node *)malloc(sizeof(node));
s->num = num;
strcpy_s(s->name, name);
while ((s->num > p1->num) && p1->next != NULL)
{
p2 = p1;
p1 = p1->next;
}
if (s->num <= p1->num)
{
if (head == p1)
{
// 插入首节点
s->next = p1;
head = s;
}
else
{
// 插入中间节点
p2->next = s;
s->next = p1;
}
}
else
{
// 插入尾节点
p1->next = s;
s->next = NULL;
}
return head;
}
// 计算单链表长度
int SingleList::GetLength(node *head)
{
int length = 0;
node *p;
p = head;
while (p != NULL)
{
p = p->next;
length++;
}
return length;
}
//单链表删除某个元素
node *SingleList::DeleteNode(node *head, int num)
{
node *p1, *p2 = nullptr;
p1 = head;
while (num != p1->num && p1->next != NULL)
{
p2 = p1;
p1 = p1->next;
}
if (num == p1->num)
{
if (p1 == head)
{
head = p1->next;
}
else
{
p2->next = p1->next;
}
free(p1);
}
else
{
printf("找不到学号为%d 的学生!\n", num);
}
return head;
}
//单链表逆序
node *SingleList::ReverseList(node *head)
{
// A->B->C->D
node *old_head; // 原来链表的头
node *new_head; // 新链表的头
node *cur_head; // 获得原来链表的头
if (head == NULL || head->next == NULL)
return head;
new_head = head; // A
cur_head = head->next; // B
while (cur_head)
{
old_head = cur_head->next; // 将原来链表的头取出,并将第二个节点作为头节点
cur_head->next = new_head; // 将取出的头设为新链表的头
new_head = cur_head; // 新链表的头就是目前新链表的头
cur_head = old_head; // 接着处理
}
head->next = NULL;
head = new_head;
return head;
}
//打印单链表
void SingleList::PrintList(node *head)
{
node *p;
int n;
n = GetLength(head);
printf("\n打印出 %d 个学生的信息:\n", n);
p = head;
while (p != NULL)
{
printf("学号: %d ,姓名: %s\n", p->num, p->name);
p = p->next;
}
}
SingleList.h:
#pragma once
typedef struct student
{
int num; // 学号
char name[128]; // 姓名
struct student *next;
}node;
class SingleList
{
public:
SingleList();
~SingleList();
//建立单链表
node *CreatNode();
//单链表插入
node *InsertNode(node *head, int num, char* name);
// 计算单链表长度
int GetLength(node *head);
//单链表删除某个元素
node *DeleteNode(node *head, int num);
//单链表逆序
node *ReverseList(node *head);
//打印单链表
void PrintList(node *head);
};
关于逆序逻辑,研究了一下:
1、主要思路:
假设有单链表A->B->C->D,首先取出首节点A作为新逆序出来的链表
这样,原链表就为:B->C->D,逆序后的新链表为:A
2. 按照上述方法,依次取出B、C、D放入新链表
2、图形表示:
原始的单链表:

<!--[endif]-->
初始状态时,单链表如上图所示,head指向头节点A。
1. 取出原始链表的第一个节点A,然后将该节点作为新链表的头节点
原始链表:

<!--[endif]-->
新链表:
<!--[if !vml]-->  <!--[endif]-->
<!--[endif]-->
<!--[if !supportLists]--> 2.然后同上处理:
原始链表:
<!--[if !vml]--> 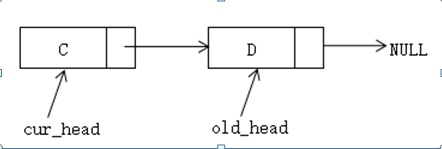 <!--[endif]-->
<!--[endif]-->
新链表:
<!--[if !vml]-->  <!--[endif]-->
<!--[endif]-->
以上这篇C++ 单链表的基本操作(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
C++ 实现静态单链表的实例
C++ 实现静态单链表的实例 利用数组实现的静态单链表,与严蔚敏书实现略有不同,不另设回收空间.有任何BUG或错误,希望各位朋友多多反馈~~感激不尽 /* Author : Moyiii * Mail: lc09@vip.qq.com * 静态链表实现,仅作学习之用,当然如果 * 你想拿去用,随你好啦. */ #include <iostream> using namespace std; #define MAX_LIST_SIZE 100 class Node { public: int d
-
C++实现顺序表的方法
废话不多说了,直接给大家上关键代码了. #pragma once #include <assert.h> template<class T> class SeqList { public: SeqList() :_a(NULL) ,_size(1) ,_capacity(1) {} SeqList(T* a, size_t size) :_a(new T[size]) ,_size(size) ,_capacity(size) { for (size_t i = 0; i <
-

如何在C++中建立一个顺序表
准备数据 复制代码 代码如下: #define MAXLEN 100 //定义顺序表的最大长度struct DATA{ char key[10]; //结点的关键字 char name[20]; int age;};struct SLType //定义顺序表结构 { DATA ListData[MAXLEN+1];//保存顺序表的结构数组 int ListLen; //顺序表已存结点的数量 }; 定义了顺序表的最大长度MAXLEN.顺序表数据元素的类型DATA以及顺序表的数据结构SLTyp
-
C++中单链表的建立与基本操作
准备数据 准备在链表操作中需要用到的变量及数据结构 示例代码如下: 复制代码 代码如下: struct Data //数据结点类型 { string key; //关键字 string name; int age;};struct CLType //定义链表结构 { Data nodeData; Data *nextNode;}; 定义了链表数据元素的类型Data以及链表的数据结构CLType.结点的具体数据保存在一个结构Data中,而指针nextNode用来指向下一个结点. 我们可以
-
C++实现顺序表的常用操作(插入删出查找输出)
实现顺序表的插入,删除,查找,输出操作在C语言中经常用到.下面小编给大家整理实现代码,一起看下吧 代码如下所示: #include<iostream> using namespace std; #define MAXSIZE 15 typedef int DataType; typedef struct { DataType data[MAXSIZE]; //通常用一位数组来描述顺序表的数据存储 int SeqLength; /*线性表长度*/ } SeqList; SeqList *Init
-
浅析C++中单链表的增、删、改、减
首先是是一个简单的例子,单链表的建立和输出.程序1.1 复制代码 代码如下: #include<iostream>#include<string>using namespace std;struct Student{ string name; string score; Student *next;//定义了指向Candidate类型变量的指针};int main(){ int n;// cout<<"请输入学生的总数:"; cin>>n
-
C++实现单链表按k值重新排序的方法
本文实例讲述了C++实现单链表按k值重新排序的方法.分享给大家供大家参考,具体如下: 题目要求: 给定一链表头节点,节点值类型是整型. 现给一整数k,根据k将链表排序为小于k,等于k,大于k的一个链表. 对某部分内的节点顺序不做要求. 算法思路分析及代码(C) 思路:将链表分为小于k.等于k.大于k的三个链表,然后再合并. 链表结点定义: typedef struct Node { int data; struct Node* next; }node, *pNode; 算法代码: pNode s
-
C++实现单链表删除倒数第k个节点的方法
本文实例讲述了C++实现单链表删除倒数第k个节点的方法.分享给大家供大家参考,具体如下: 题目: 删除单链表中倒数第k个节点 解题思路及算法代码: 标尺法,定义两个指针指向链表头结点,先让一个走k步,然后两个指针同时开始走,当先走的指针走到末尾时,后走的指针指向的结点就是需要删除的结点. 单链表结构定义: typedef struct Node { int data; struct Node* next; }node, *pLinkedList; 删除倒数第K结点操作代码: //head表示头结
-
利用C++简单实现顺序表和单链表的示例代码
本文主要给大家介绍了关于C++实现顺序表和单链表的相关内容,分享出来供大家参考学习,话不多说,来一起看看详细的介绍: 一.顺序表示例代码: #include <assert.h> #include <iostream> using namespace std; typedef int Datatype; class SeqList { public: SeqList() :_array(NULL) ,_size(0) ,_capacity(0) { } SeqList(const
-
C++ 单链表的基本操作(详解)
链表一直是面试的高频题,今天先总结一下单链表的使用,下节再总结双向链表的.本文主要有单链表的创建.插入.删除节点等. 1.概念 单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素. 链表中的数据是以结点来表示的,每个结点的构成:元素 + 指针,元素就是存储数据的存储单元,指针就是连接每个结点的地址数据.如下图: 2.链表的基本操作 SingleList.cpp: #include "stdafx.h" #include "SingleList.h&
-
C++ 双链表的基本操作(详解)
1.概念 双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱.所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点.一般我们都构造双向循环链表. 结构图如下所示: 2.基本操作实例 DoubleList.cpp #include "stdafx.h" #include "DoubleList.h" #include <stdio.h> #include <malloc.h>
-
Go语言数据结构之单链表的实例详解
目录 任意类型的数据域 实例01 快慢指针 实例02 反转链表 实例03 实例04 交换节点 实例05 任意类型的数据域 之前的链表定义数据域都是整型int,如果需要不同类型的数据就要用到 interface{}. 空接口 interface{} 对于描述起不到任何的作用(因为它不包含任何的method),但interface{}在需要存储任意类型的数值的时候相当有用,因为它可以存储任意类型的数值. 一个函数把interface{}作为参数,那么它可以接受任意类型的值作为参数:如果一个函数返回i
-
C#数据结构之单链表(LinkList)实例详解
本文实例讲述了C#数据结构之单链表(LinkList)实现方法.分享给大家供大家参考,具体如下: 这里我们来看下"单链表(LinkList)".在上一篇<C#数据结构之顺序表(SeqList)实例详解>的最后,我们指出了:顺序表要求开辟一组连续的内存空间,而且插入/删除元素时,为了保证元素的顺序性,必须对后面的元素进行移动.如果你的应用中需要频繁对元素进行插入/删除,那么开销会很大. 而链表结构正好相反,先来看下结构: 每个元素至少具有二个属性:data和next.data
-
深入单链表的快速排序详解
单链表的快排序和数组的快排序基本思想相同,同样是基于划分,但是又有很大的不同:单链表不支持基于下标的访问.故书中把待排序的链表拆分为2个子链表.为了简单起见,选择链表的第一个节点作为基准,然后进行比较,比基准小得节点放入左面的子链表,比基准大的放入右边的子链表.在对待排序链表扫描一遍之后,左边子链表的节点值都小于基准的值,右边子链表的值都大于基准的值,然后把基准插入到链表中,并作为连接两个子链表的桥梁.然后分别对左.右两个子链表进行递归快速排序,以提高性能.但是,由于单链表不能像数组那样随机存储
-
C语言单链表实现方法详解
本文实例讲述了C语言单链表实现方法.分享给大家供大家参考,具体如下: slist.h #ifndef __SLIST_H__ #define __SLIST_H__ #include<cstdio> #include<malloc.h> #include<assert.h> typedef int ElemType; typedef struct Node { //定义单链表中的结点信息 ElemType data; //结点的数据域 struct Node *next
-
C语言实现线性表的基本操作详解
目录 前言 一.实训名称 二.实训目的 三.实训要求 四.实现效果 五.顺序存储代码实现 六.链式存储代码实现 前言 这里使用的工具是DEV C++ 可以借鉴一下 一.实训名称 线性表的基本操作 二.实训目的 1.掌握线性表的基本概念 2.掌握线性表的存储结构(顺序存储与链式存储) 3.掌握线性表的基本操作 三.实训要求 1.线性表可以顺序表也可以用单链表实现,鼓励大家用两种方式实现. 2.创建线性表时,数据从键盘输入整形数据 3.线性表类型定义和或各种操作的实现,可以用教材给出的方法,也可以自
-
Go语言学习之链表的使用详解
目录 1. 什么是链表 2. 单项链表的基本操作 3. 使用 struct 定义单链表 4. 尾部添加节点 5. 头部插入节点 6. 指定节点后添加新节点 7. 删除节点 1. 什么是链表 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的. 链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成.每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域. 使用链表结构可以避免在使用数组时需要预先知
-
Python 列表与链表的区别详解
目录 python 列表和链表的区别 列表的实现机制 链表 链表与列表的差异 python 列表和链表的区别 python 中的 list 并不是我们传统意义上的列表,传统列表--通常也叫作链表(linked list)是由一系列节点来实现的,其中每个节点都持有一个指向下一节点的引用. class Node: def __init__(self, value, next=None): self.value = value self.next = next 接下来,我们就可以将所有的节点构造成一个
-
Asp.Net MVC4通过id更新表单内容的思路详解
用户需求是:一个表单一旦创建完,其中大部分的字段便不可再编辑.只能编辑其中部分字段. 而不可编辑是通过对input输入框设置disabled属性实现的,那么这时候直接向数据库中submit表单中的内容就会报错,因为有些不能为null的字段由于disabled属性根本无法在前端被获取而后更新至数据库. 有下面两种思路: 1.通过创建隐藏表单,为每一个disabled控件分别创建一个隐藏控件,但是这样的问题是工作量太大(如果表单有一千个属性,你懂的) 2.通过获取该表单在数据库中的id,把该id和可