JavaScript中关于递归与回溯的实例详解
目录
- 何为递归
- 构成递归条件
- 关于回溯
- 实际业务
- 组合问题
何为递归
递归作为一种算法在程序设计语言中广泛应用。 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。递归的能力在于用有限的语句来定义对象的无限集合。需要注意的是,递归必须要用边界条件,否则很容易导致死循环
构成递归条件
- 子问题须与原始问题为同样的事,且更为简单
- 不能无限制地调用本身,须有个出口,化简为非递归状况处理
但是递归函数并不容易一下子就能想的出来,所以我们可以先通过一个子问题来逐步延申。
问题一: 假设我们需要求1+2+3+...+100的值,我们很容易想出下面的代码
function calcNum(n) {
let sum = 0
for (let i = 0; i <= 100; i++) {
sum += i
}
return sum
}
console.log(calcNum()) // 5050
这样的代码是不满足于递归中,直接或者间接调用本身的定义。那么如何变成递归版本呢?(任何的循环,都可以写成递归)
- 寻找相同的子问题 该题目相同的子问题很明显是sum+=i,该过程是重复调用的过程。
- 寻找终止条件 寻找递归的终止条件,该问题的终止条件是i>100的情况
这两大要素都找到了,就很容易写出下面的递归版本
function calcNum(n) {
let sum = 0
function dfs(n) {
if (n > 100) {
return
}
sum += n
n++
dfs(n)
}
dfs(n)
return sum
}
console.log(calcNum(1)) // 5050
关于回溯
递归一定伴随着回溯,那么什么是回溯呢?以上面的代码为例子,我们分别在这两处地方输出n的值
function calcNum(n) {
let sum = 0
function dfs(n) {
if (n > 100) {
return
}
sum += n
n++
console.log(n, '递归前的n')
dfs(n)
console.log(n, '递归后的n')
}
dfs(n)
return sum
}
毫无疑问,"递归前的n"会按照1-100输出,而"递归后的n"则会100-1输出,这就说明了一个很重要的知识点,递归函数是类似一个栈迭代的过程,它的值输出的顺序为先进后出。通俗一点说,递归函数后面的参数,会反转输出。
要想理解回溯的含义,最为经典的还是二叉树的遍历。二叉树的遍历,又分为前序遍历,中序遍历,后序遍历,分别通过代码来感受一下这三种遍历的方式。 前序遍历
// 基本结构
const treeNode = {
val: 1,
left: null,
right: {
val: 2,
left: {
val: 3,
left: null,
right: null
},
right: null
}
}
来看下leetcode 前序遍历原题
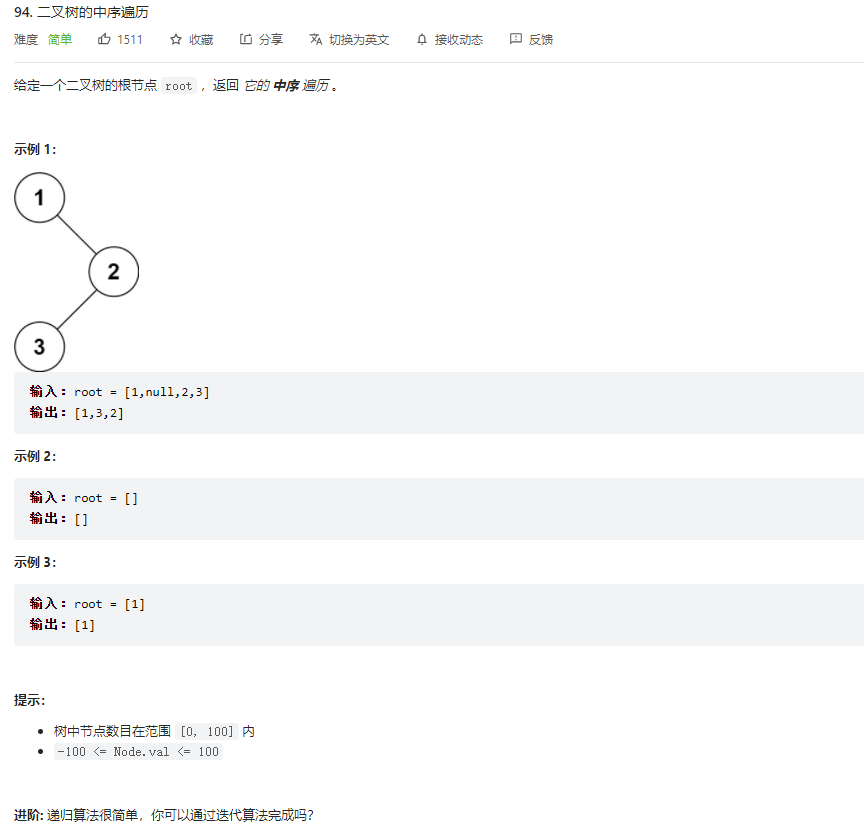
const root = {
val: 5,
left: {
val: 4,
left: {
val: 1,
right: null,
left: null
},
right: {
val: 2,
right: null,
left: null
}
},
right: {
val: 6,
left: {
val: 7,
left: null,
right: null
},
right: {
val: 8,
left: null,
right: null
}
}
}
function getRoot(root) {
const res = []
function dfs(root) {
if (!root) {
return
}
res.push(root.val)
dfs(root.left)
dfs(root.right)
}
dfs(root)
return res
}
console.log(getRoot(root)) // 5 4 1 2 6 7 8
中序遍历
function getRoot(root) {
const res = []
function dfs(root) {
if (!root) {
return
}
dfs(root.left)
res.push(root.val)
dfs(root.right)
}
dfs(root)
return res
}
console.log(getRoot(root)) // 1 4 2 5 6 7 8
后续遍历
function getRoot(root) {
const res = []
function dfs(root) {
if (!root) {
return
}
dfs(root.left)
dfs(root.right)
res.push(root.val)
}
dfs(root)
return res
}
console.log(getRoot(root)) // 1 2 4 7 8 6 5
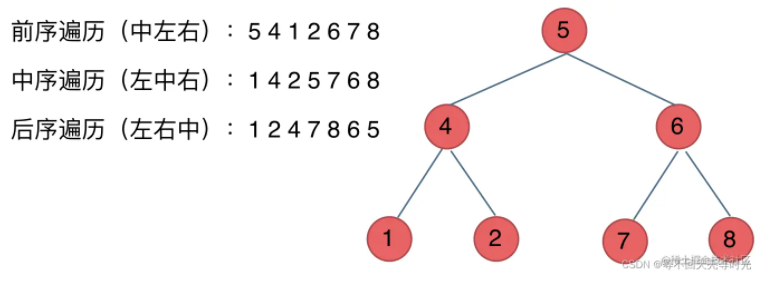
在写递归的时候,时刻都要注意边界,以上场景的边界,则是找不到节点(节点为null)的时候,就退出。
通过输出的结果可以得知以下规律:
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
而实现该规律的主要依据,是通过递归的回溯导致,我们以中序遍历为例子:
dfs(root.left) res.push(root.val) dfs(root.right)
当第一个dfs(root.left)递归结束后,就会弹出'1'的节点,然后就进了dfs(root.right)的节点,发现是个null,说明这个dfs(root.right)递归结束,那么此时则回到了'4'的节点,然后就进入了dfs(root.right)节点...
实际业务
二叉树的遍历,其实类比于我们常见操作菜单树,或着树形结构的操作...
let tree = [
{
id: '1',
title: '节点1',
children: [
{
id: '1-1',
title: '节点1-1'
},
{
id: '1-2',
title: '节点1-2'
}
]
},
{
id: '2',
title: '节点2',
children: [
{
id: '2-1',
title: '节点2-1'
}
]
}
]
当我们要寻找遍历每个节点的时候,同样需要注意边界,当我们操作的数据没有的时候或者不存在的时候,则退出当次遍历。
function getRootData(tree) {
const res = []
function dfs(tree) {
if (!tree || tree.length === 0) {
return res
}
for (let i = 0; i < tree.length; i++) {
const t = tree[i]
if (t.children && t.children.length > 0) {
dfs(t.children) // 开始递归
} else {
res.push(t.title) // ['节点1-1', '节点1-2', '节点2-1']
}
}
}
dfs(tree)
return res
}
可能有人会有疑问,这也没有利用到回溯的操作啊,那么我就换个场景,假如我给个你节点的id,你帮我找出他所有的父节点,那么你可能会怎么操作呢?
const tree = [
{
id: '1',
title: '节点1',
children: [
{
id: '1-1',
title: '节点1-1'
},
{
id: '1-2',
title: '节点1-2'
}
]
},
{
id: '2',
title: '节点2',
children: [
{
id: '2-1',
title: '节点2-1',
children: [
{
id: '2-1-1',
title: '节点2-1-1'
}
]
}
]
}
]
function pathTree(tree, id) {
const res = []
function dfs(tree, path) {
if (!tree || tree.length === 0) {
return
}
for (let i = 0; i < tree.length; i++) {
const t = tree[i]
path.push(t.id)
if (path.includes(id)) {
res.push(path.slice())
}
if (t.children && t.children.length > 0) {
dfs(t.children, path)
}
path.pop() // 路径回溯
}
}
dfs(tree, [])
return res
}
console.log(pathTree(tree, '2-1-1')) // [2,2-1,2-1-1]
其实以上核心的代码为path.pop(),为什么需要这句代码呢?我们可以通过leetcode上的排列组合问题来进行讨论。
组合问题
经典的组合问题
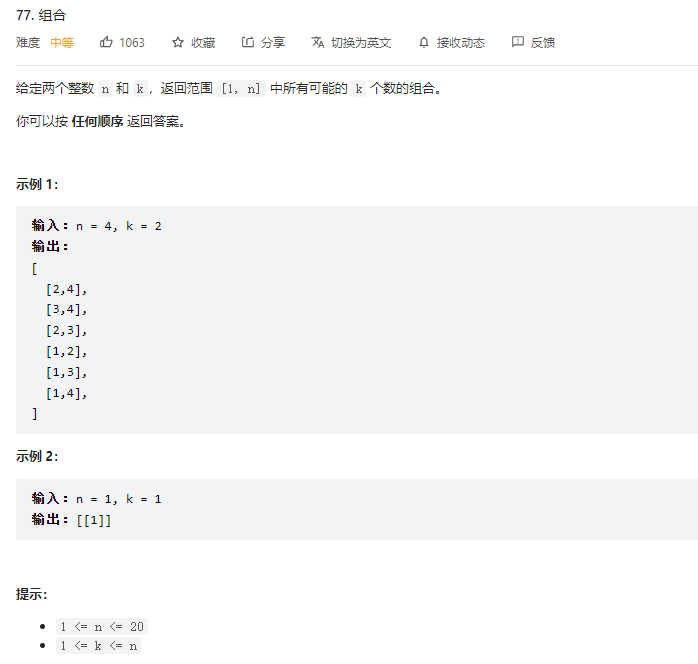
以上面题目为例子,从1-4(n)的数字中,排列2(k)个数的组合。解这个题目,可以使用暴力的做法,嵌套for循环来完成该功能。
function combine(n) {
const res = []
for (let i = 1; i <= n; i++) {
for (let j = i + 1; j <= n; j++) {
res.push([i, j])
}
}
return res
}
console.log(combine(4), 'res') // [1,2][1,3][1,4][2,3][3,4][2,4]
细心朋友就会发现,它嵌套for次数则是等于它排列(k)的次数,那么我假如k的次数是10,或者20,那么岂不是要嵌套10个或者20个for循环。这套代码写下来,估计是个人都会晕了。在以上代码块中也可以发现重复的子问题也就是for循环,它想要的结果则为当我们找个了k个数的时候就停止。那么我们可以尝试通过递归来解决该问题(递归for循环),但是这样的过程还是很抽象的,需要借助图例理解。(任何的组合问题,都可以理解成为n叉树的遍历)
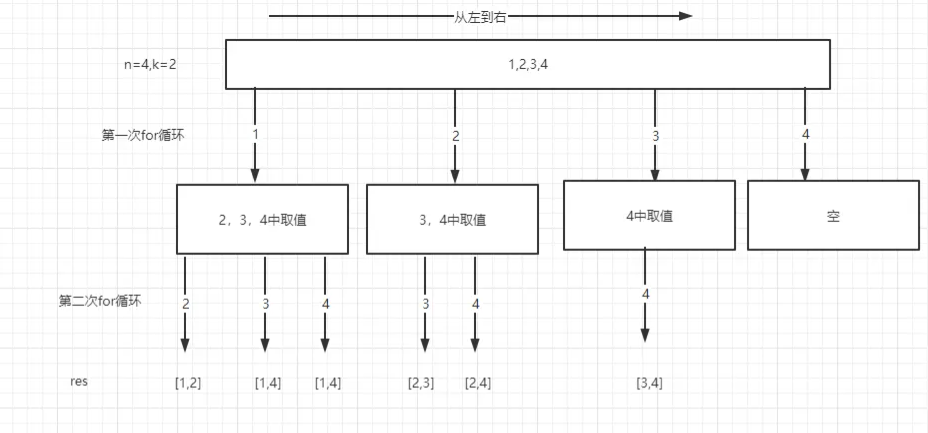
function combine(n, k) {
const res = []
function dfs(n, path, startIndex) {
if (path.length === k) {
res.push(path.slice())
return
}
for (let i = startIndex; i <= n; i++) {
path.push(i)
dfs(n, path, i + 1)
path.pop()
}
}
dfs(n, [], 1)
return res
}
当我们选择到了[1,2]之后,则需要回到1的位置,因为这个时候需要选择3选项,形成[1,3],那么回到'1'的操作,就类似于二叉树遍历回到父节点的操作,如果此时我们不操作,path.pop(),那么此时就会形成了[1,2,3],这样的结果明显不是我们想要,所以在操作push "3"的过程,需要先把2给pop掉。而递归的终止条件则为当路径的长度等于k的时候则退出。 另外在函数体中,还发现了startIndex的存在,这个是作为横向for循环开始的位置,我们结合上面两个for循环的代码,是不是发现了j = i + 1的操作,而这个startIndex则是还原了这个操作而已。
到此这篇关于JavaScript中关于递归与回溯的实例详解的文章就介绍到这了,更多相关JavaScript递归 回溯内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
编写高质量的js之正确理解正则表达式回溯
当一个正则表达式扫描目标字符串时,从左到右逐个扫描正则表达式的组成部分,在每个位置上测试能不能找到一个匹配.对于每一个量词和分支,都必须确定如何继续进行.如果是一个量词(如*.+?或者{2,}),那么正则表达式必须确定何时尝试匹配更多的字符:如果遇到分支(通过|操作符),那么正则表达式必须从这些选项中选择一个进行尝试. 当正则表达式做出这样的决定时,如果有必要,它会记住另一个选项,以备返回后使用.如果所选方案匹配成功,正则表达式将继续扫描正则表达式模板,如果其余部分匹配也成功了,那么匹配就结束了
-

js回溯法计算最佳旅行线路代码实例
回溯法 假如有 A,B,C,D四个城市,他们之间的距离用 G[V][E] 表示,为 无穷大,则表示两座城市不相通 现在从计算从某一个城市出发,把所有的城市不重复旅行一次,最短路径 其中G为: (Infinity表示城市不相通) var g = [ [Infinity,3 ,Infinity,8 ,9], [ 3 ,Infinity,3 ,10 ,5], [Infinity, 3 ,Infinity,4 ,3], [8 ,10 ,4 ,Infinity,20], [9 ,5 ,3 ,20 ,Inf
-
javascript递归回溯法解八皇后问题
下面给大家分享的是回溯法解八皇后, 带详细注解,这里就不多废话了. function NQueens(order) { if (order < 4) { console.log('N Queens problem apply for order bigger than 3 ! '); return; } var nQueens = []; var backTracking = false; rowLoop: for (var row=0; row<order; row++) { //若出现ro
-
JS尾递归的实现方法及代码优化技巧
本文实例讲述了JS尾递归的实现方法及代码优化技巧.分享给大家供大家参考,具体如下: 在学习数据结构和算法的时候,我们都知道所有的递归都是可以优化成栈+循环的. 对于特定的递归函数,一般我们都是手动对它们进行优化的. 在学习scala的时候,接触到尾递归的概念.我们只要将递归写成尾递归方式,编译器会自动帮助我们优化. ps:并不是所有的递归都可以改写成尾递归 在js中,尾递归通常会被解释器优化.然而,并不是所有的js解释器都支持尾递归优化. 对于不支持尾递归优化的环境,我们需要手动将递归优化成栈+
-
JavaScript递归详述
目录 一.什么是递归? 二.利用递归求数学题 1.求1 * 2 * 3 * 4 -*n的阶乘 2. 求斐波那契数列 三.利用递归求对应数据对象 一.什么是递归? 如果一个函数在内部可以调用其本身,那么这个函数就是递归函数.简单理解:函数内部自己调用自己, 这个函数就是递归函数. 如下所示: function fn(){ fn(); } fn(); 这个函数就是一个递归函数,当我们直接打印时,会: 发现打印错误,这是为什么呢?因为递归函数的作用和循环效果一样.当没有给他返回值的时候,它就会一直死循
-
Javascript迭代、递推、穷举、递归常用算法实例讲解
累加和累积 累加:将一系列的数据加到一个变量里面.最后的得到累加的结果 比如:将1到100的数求累加和 小球从高处落下,每次返回到原来一半,求第十次小球落地时小球走过的路程 <script> var h=100; var s=0; for(var i=0;i<10;i++){ h=h/2; s+=h; } s=s*2+100; </script> 累积:将一系列的数据乘积到一个变量里面,得到累积的结果. 常见的就是n的阶乘 var n=100; var result= 1;
-
JavaScript中关于递归与回溯的实例详解
目录 何为递归 构成递归条件 关于回溯 实际业务 组合问题 何为递归 递归作为一种算法在程序设计语言中广泛应用. 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量.递归的能力在于用有限的语句来定义对象的无限集合.需要注意的是,递归必须要用边界条件,否则很容易导致死循环 构成递归条件 子问题须与原始问题为同样的事,且更为简单
-
javascript中2个感叹号的用法实例详解
在javascript代码中经常会见到!!的情况,本文即以实例形式较为深入的分析javascript中2个感叹号的用法.分享给大家供大家参考之用.具体分析如下: javascript中的!!是逻辑"非非",即是在逻辑"非"的基础上再"非"一次.通过!或!!可以将很多类型转换成bool类型,再做其它判断. 一.应用场景:判断一个对象是否存在 假设有这样一个json对象: { color: "#E3E3E3", "fon
-
Javascript中的方法和匿名方法实例详解
本文实例讲述了Javascript中的方法和匿名方法.分享给大家供大家参考.具体分析如下: Javascript方法(函数) 声明函数 以function开头,后跟函数名,与C#.java不同,Javascript不需要声明返回值类型.参数类型.没有返回值就是undefined. 举个例子更清楚: 无参数无返回值的方法: function f1(){ alert('这是一个方法'); } f1();//调用方法 无参数有返回值的方法: function f2(){ return 100; }
-
Javascript中函数分类&this指向的实例详解
JS中定义函数的三种方式 通过实例来说明吧 <script> //method1 function fn() { console.log('fn created '); } //method2 var fn2 = function () { console.log('fn2 created'); } //method3 var fn3 = new Function('test', 'console.log(test);'); fn3('fn3 test'); console.dir(fn3);
-
JavaScript中变量提升和函数提升实例详解
js 执行 词法分析阶段:包括分析形参.分析变量声明.分析函数声明三个部分.通过词法分析将我们写的 js 代码转成可以执行的代码. 执行阶段 变量提升 只有声明被提升,初始化不会被提升 声明会被提升到当前作用域的顶端
-
Javascript 中AJAX的图书管理代码实例详解
目录 1.接口文档 2.代码结构 3.案例效果 总结 1.接口文档 2.代码结构 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewpor
-
Angular中$cacheFactory的作用和用法实例详解
先说下缓存: 一个缓存就是一个组件,它可以透明地储存数据,以便以后可以更快地服务于请求.多次重复地获取资源可能会导致数据重复,消耗时间.因此缓存适用于变化性不大的一些数据,缓存能够服务的请求越多,整体系统性能就能提升越多. $cacheFactory介绍: $cacheFactory是一个为Angular服务生产缓存对象的服务.要创建一个缓存对象,可以使用$cacheFactory通过一个ID和capacity.其中,ID是一个缓存对象的名称,capacity则是描述缓存键值对的最大数量. 1.
-
JAVA 中解密RSA算法JS加密实例详解
JAVA 中解密RSA算法JS加密实例详解 有这样一个需求,前端登录的用户名密码,密码必需加密,但不可使用MD5,因为后台要检测密码的复杂度,那么在保证安全的前提下将密码传到后台呢,答案就是使用RSA非对称加密算法解决 . java代码 需要依赖 commons-codec 包 RSACoder.Java import org.apache.commons.codec.binary.Base64; import javax.crypto.Cipher; import java.security.
-
vue组件中使用props传递数据的实例详解
在 Vue 中,父子组件的关系可以总结为 props向下传递,事件向上传递.父组件通过 props 给子组件下发数据,子组件通过事件给父组件发送消息.看看它们是怎么工作的. 一.基本用法 组件不仅仅是要把模板的内容进行复用,更重要的是组件间要进行通信. 在组件中,使用选项props 来声明需要从父级接收的数据, props 的值可以是两种, 一种是字符串数组,一种是对象. 1.1 字符串数组: <div id="app4"> <my-component4 messa
-
JavaScript中变量提升和函数提升的详解
第一篇文章中提到了变量的提升,所以今天就来介绍一下变量提升和函数提升.这个知识点可谓是老生常谈了,不过其中有些细节方面博主很想借此机会,好好总结一下. 今天主要介绍以下几点: 1. 变量提升 2. 函数提升 3. 为什么要进行提升 4. 最佳实践 那么,我们就开始进入主题吧. 1. 变量提升 通常JS引擎会在正式执行之前先进行一次预编译,在这个过程中,首先将变量声明及函数声明提升至当前作用域的顶端,然后进行接下来的处理.(注:当前流行的JS引擎大都对源码进行了编译,由于引擎的不同,编译形式也会有