C语言 详细讲解#pragma的使用方法
目录
- 一、#pragma 简介
- 二、#pragma message
- 三、#pragma once
- 四、#pragma pack
- 五、小结
一、#pragma 简介
#pragma 用于指示编译器完成一些特定的动作
#pragma 所定义的很多指示字是编译器特有的
#pragma 在不同的编译器间是不可移植的
- 预处理器将忽略它不认识的 #pragma 指令
- 不同的编译器可能以不同的方式解释同一条 #pragma 指令
一般用法:
#pragma parameter
注:不同的 parameter 参数语法和意义各不相同
二、#pragma message
- message 参数在大多数的编译器中都有相似的实现
- message 参数在编译时输出消息到编译输出窗口中
- message 用于条件编译中可提示代码的版本信息
例如:
#if defined(ANDROID20)
#pragma message("Compile Android SDK 2.0...")
#define VERSION "Android 2.0 "
#endif
注:#error 和 #warning 不同,#pragma message 仅仅代表一条编译消息,不代表程序错误。
下面看一个 #pragma message 使用示例:
test.c:
#include <stdio.h>
#if defined(ANDROID20)
#pragma message("Compile Android SDK 2.0...")
#define VERSION "Android 2.0"
#elif defined(ANDROID23)
#pragma message("Compile Android SDK 2.3...")
#define VERSION "Android 2.3"
#elif defined(ANDROID40)
#pragma message("Compile Android SDK 4.0...")
#define VERSION "Android 4.0"
#else
#error Compile Version is not provided!
#endif
int main()
{
printf("%s\n", VERSION);
return 0;
}
下面为输出结果:

三、#pragma once
- #pragma once 用于保证头文件只被编译一次
- #pragma once 是编译器相关的,不一定被支持
下面两种方式的区别是:前者是被 C 语言所支持的,并不是只包含一次头文件,而是包含多次,然后通过宏控制是否嵌入到源代码中,也就是说通过宏的方式,可以保证头文件里面的内容只被嵌入一次,但是由于包含了多次,预处理器还是处理了多次,所以效率上来说比较低;后者是告诉预处理器当前文件只编译一次,所以说效率较高。

下面看一个 #pragma once 的使用示例:
global.h:
#pragma once int g_value = 1;
test.c:
#include <stdio.h>
#include "global.h"
#include "global.h"
int main()
{
printf("g_value = %d\n", g_value);
return 0;
}
下面为输出结果,可以看到虽然在test.c 定义了两次global.h,但是程序编译没有报错,且能正常运行,这就是 #pragma once 作用的结果:

工程应用中既想要移植性,又想要保证效率,可以采用以下做法:
global.h:
#ifndef _GLOBAL_H_ #define _GLOBAL_H_ #pragma once int g_value = 1; #endif
四、#pragma pack
什么是内存对齐?
- 不同类型的数据在内存中按照一定的规则排列
- 而不一定是顺序的一个接一个的排列
下面想想 Test1 和 Test2 所占的内存空间是否相同?

答案是否定的,Test1 占用 12 个字节,而 Test 占用 8 个字节
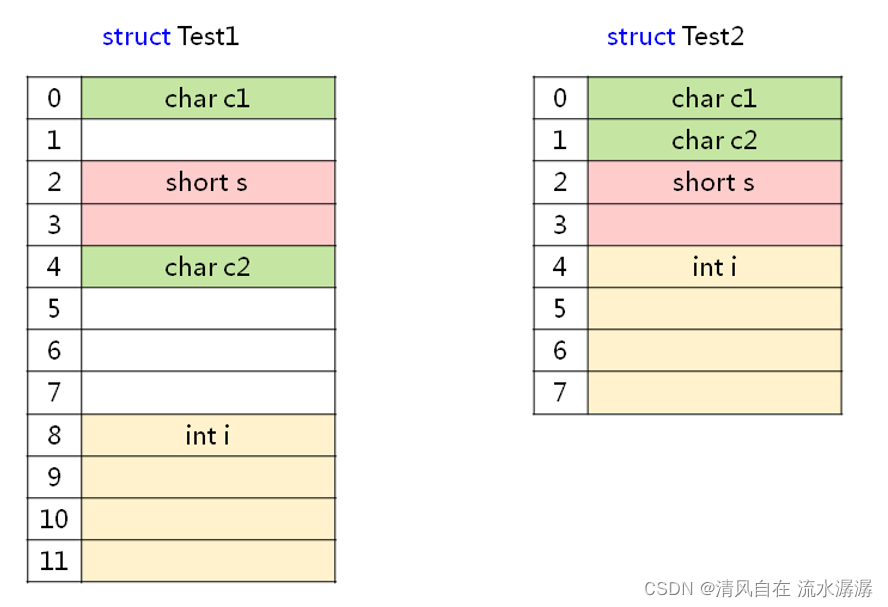
为什么需要内存对齐?
- CPU对内存的读取不是连续的,而是分成块读取的,块的大小只能是1、2、4、8、16...字节
- 当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
- 某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则产生硬件异常
#pragma pack 用于指定内存对齐方式
#pragma pack 能够改变编译器的默认对齐方式
例如,下面代码中,Test1 和 Test2 的内存均为 8 个字节

struct 占用的内存大小
第一个成员起始于 0 偏移处
每个成员按其类型大小和 pack 参数中较小的一个进行对齐
- 偏移地址必须能被对齐参数整除
- 结构体成员的大小取其内部长度最大的数据成员作为其大小
结构体总长度必须为所有对齐参数的整数倍
编译器在默认情况下按照 4 字节对齐。
下面通过代码,手工计算结构体所占用的内存大小
test.c:
#include <stdio.h>
#pragma pack(4)
struct Test1
{ //对齐参数 偏移地址 大小
char c1; //1 0 1
short s; //2 2 2
char c2; //1 4 1
int i; //4 8 4
};
#pragma pack()
#pragma pack(4)
struct Test2
{ //对齐参数 偏移地址 大小
char c1; //1 0 1
char c2; //1 1 1
short s; //2 2 2
int i; //4 4 4
};
#pragma pack()
int main()
{
printf("sizeof(Test1) = %d\n", sizeof(struct Test1));
printf("sizeof(Test2) = %d\n", sizeof(struct Test2));
return 0;
}
以 Test1 为例,c1 类型大小为 1 字节,而 pack 参数默认为 4,所以对齐参数取最小为 1;同理 s 的对齐参数为 2,偏移地址要被 2 整除,所以为 2;同理 c 的对齐参数为 1,偏移地址为 4;同理,i 的对齐参数为 4,因为偏移地址要能被 对齐参数 4 整除,在偏移地址 4 之后能被 4 整除的最小偏移地址为 8,所以 i 的偏移地址为 8,而 i 占用 4 个字节,所以 Test1 结构体占用的总字节数为 12 字节,这就和上面的图对应起来了。
下面再通过一个例子感受一下:
在 gcc 编译器下,test.c:
#include <stdio.h>
#pragma pack(8)
struct S1
{ //对齐参数 偏移地址 大小
short a; //2 0 2
long b; //4 4 4
};
struct S2
{ //对齐参数 偏移地址 大小
char c; //1 0 1
struct S1 d; //4 4 8
double e; //4 12 8
};
#pragma pack()
int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}
下面为输出结果:

这里注意两点:
1.结构体成员的大小取其内部长度最大的数据成员作为其大小,所以 S1 的内存大小为 4,而pack 参数默认为 8,所以对齐参数为 4
2.一般的 pack 对齐格式分别是 1,2,4,8,16,默认的对齐格式,也就是:#pragmapack() 的情况下,会在结构体中挑选占用字节最多的类型,例如 double 占用 8 个字节
3.gcc 编译器暂时不支持 8 字节对齐,默认按照 4 字节对齐,所以 S2 中的 e 的对齐参数为 4,故 S2 占用内存大小为 20 字节。(学习采用的为 ubuntu 10.10)
如果把代码放在 VS2012 里运行,那结果就是和分析的一样,S2 占用 24 字节。
#include <stdio.h>
#pragma pack(8)
struct S1
{ //对齐参数 偏移地址 大小
short a; //2 0 2
long b; //4 4 4
};
struct S2
{ //对齐参数 偏移地址 大小
char c; //1 0 1
struct S1 d; //4 4 8
double e; //8 16 8
};
#pragma pack()
int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}
结果:

五、小结
#pragma 用于指示编译器完成一些特定的动作
#pragma 所定义的很多指示字是编译器特有的
- #pragma message 用于自定义编译消息
- #pragma once 用于保证头文件只被编译一次
- #pragma pack 用于指定内存对齐方式
到此这篇关于C语言 详细讲解#pragma的使用方法的文章就介绍到这了,更多相关C语言 #pragma内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言宏定义#define的使用
目录 无参宏定义 定义形式 带参宏定义 定义形式 #和##运算 #运算 用法: ##运算 用法: 变参宏 #ifndef 条件编译 宏定义是高级语言编译器提供的常用语法,其目的是利用某一标识符标识某个文本字符串.在编写程序时,如果程序中反复地使用某个数据或某段程序片段,就可以考虑将这个数据或程序片段定义为宏,然后每个出现该数据或程序片段的地方用宏名替代,选择宏定义来做的好处是程序简洁,可读性好,而且当需要修改这些相同的程序片段时,只要修改宏定义中的字符串即可,不需要修改多处. 宏定义命令:def
-
C语言详细讲解#error与#line如何使用
目录 一.#error 的用法 二.#line 的用法 三.小结 一.#error 的用法 #error 用于生成一个编译错误消息 用法 #error message,message不需要用双引号包围 #error 编译指示字用于自定义程序员特有的编译错误消息,类似的,#warning 用于生成编译警告. #error 是一种预编译器指示字 #error 可用于提示编译条件是否满足 用法示例如下: 编译过程中的任意错误信息意味着无法生成最终的可执行程序. 下面初探一下 #error #inclu
-
C语言 详细讲解#pragma的使用方法
目录 一.#pragma 简介 二.#pragma message 三.#pragma once 四.#pragma pack 五.小结 一.#pragma 简介 #pragma 用于指示编译器完成一些特定的动作 #pragma 所定义的很多指示字是编译器特有的 #pragma 在不同的编译器间是不可移植的 预处理器将忽略它不认识的 #pragma 指令 不同的编译器可能以不同的方式解释同一条 #pragma 指令 一般用法: #pragma parameter 注:不同的 parameter
-
C语言详细讲解位运算符的使用
目录 一.位运算符分析 二.小贴士 三.位运算与逻辑运算 四.小结 一.位运算符分析 C语言中的位运算符 位运算符直接对 bit 位进行操作,其效率最高. & 按位与 | 按位或 ^ 按位异或 ~ 取反 << 左移 >> 右移 左移和右移注意点 左操作数必须为整数类型 char 和 short 被隐式转换为 int 后进行移位操作 右操作数的范围必须为:[0,31] 左移运算符<< 将运算数的二进制位左移 规则:高位丢弃,低位补0 右移运算符>> 把
-
C语言简明讲解队列的实现方法
目录 前言 队列的表示和实现 队列的概念及结构 代码实现 束语 前言 大家好啊,我又双叒叕来水博客了,道路是曲折的,前途是光明的,事物是呈螺旋式上升的,事物最终的发展结果还是我们多多少少能够决定的,好啦,吹水结束,这与这篇博客的主题并没有太多联系.关于栈和队列这一板块本来是想不写(就是想偷懒),但是想了想,觉得这样不太好,关于数据结构这一块可能会有缺失,所以最终还是决定写,必须补齐这一块,恰好最近有时间写博客,所以还是写了,这篇博客将介绍队列的知识点,理解链表那一块的操作后,栈和队列的相关操作还
-
C语言详细讲解二分查找用法
目录 [力扣题号]704.二分查找 力扣题目链接 示例 1: 输入: nums = [-1,0,3,5,9,12], target = 9 输出: 4 解释: 9 出现在 nums 中并且下标为 4 示例 2: 输入: nums = [-1,0,3,5,9,12], target = 2 输出: -1 解释: 2 不存在 nums 中因此返回 -1 提示: 你可以假设 nums中的所有元素是不重复的. n将在[1, 10000]之间. nums的每个元素
-
C语言详细讲解指针数组的用法
目录 1. 指针数组定义方法 2. 指针的指针(二级指针) 3. 字符串和指针 4. 数组指针 定义方法 数组指针的用法 1. 指针数组定义方法 格式: 类型说明符 *数组名[ 元素个数 ] int *p[10]; // 定义了一个整型指针数组p,有10个元素,都是int *类型的变量 指针数组的分类: 同指针类型的分类,见上一篇 大多数情况下,指针数组都用来保存多个字符串. #include <stdio.h> int main() { char *name[5] = {"Hell
-
C语言 详细讲解逻辑运算符的使用
目录 一.&& 与 II 分析 二.!分析 三.小结 一.&& 与 II 分析 下面的程序运行结束后,i, j,k 的值分别为多少? #include <stdio.h> int main() { int i = 0; int j = 0; int k = 0; ++i || ++j && ++k; printf("i = %d\n", i); printf("j = %d\n", j); printf(&
-
C语言详细讲解注释符号的使用
目录 一.注释规则 二.注释中一个有趣的问题 三.教科书型注释 四.迷惑型的注释 五.忽悠型注释 六.搞笑型注释 七.漂亮的程序注释 八.小结 一.注释规则 编译器在编译过程中使用空格替换整个注释 字符串字面量中的 // 和 /*...*/ 不代表注释符号 /*......*/ 型注释不能被嵌套 下面看一下这样一段代码: #include <stdio.h> int main() { int/*...*/i; char* s = "abcdefgh //hijklmn";
-
C语言详细讲解多维数组与多维指针
目录 一.指向指针的指针 二.二维数组与二维指针 三.数组名 四.小结 一.指向指针的指针 指针的本质是变量 指针会占用一定的内存空间 可以定义指针的指针来保存指针变量的地址值 为什么需要指向指针的指针? 指针在本质上也是变量 对于指针也同样存在传值调用与传址调用 下面看一个重置动态空间大小(从 size 到 new_size)的代码: #include <stdio.h> #include <malloc.h> int reset(char** p, int size, int
-
C语言 详细讲解数组参数与指针参数
目录 一.C语言中的数组参数退化为指针的意义 二.二维数组参数 三.等价关系 四.被忽视的知识点 五.小结 一.C语言中的数组参数退化为指针的意义 C 语言中只会以值拷贝的方式传递参数 当向函数传递数组时: 将整个数组拷贝一份传入函数 × 将数组名看做常量指针传数组首元素地址 √ C 语言以高效作为最初设计目标: a) 参数传递的时候如果拷贝整个数组执行效率将大大下降. b) 参数位于栈上,太大的数组拷贝将导致栈溢出. 二.二维数组参数 二维数组参数同样存在退化的问题 二维数
-
C语言详细讲解循环语句的妙用
目录 一.循环语句分析 二.do ... while 语句的循环方式 三.while 语句的循环方式 四.for 语句的循环方式 五.break和 continue 的区别 六.do 和 break 的妙用 七.小结 一.循环语句分析 循环语句的基本工作方式 通过条件表达式判定是否执行循环体 条件表达式遵循 if 语句表达式的原则 do,while,for的区别 do 语句先执行后判断,循环体至少执行一次 while 语句先判断后执行,循环体可能不执行 for 语句先判断后执行,相比 while