TensorFlow的自动求导原理分析
原理:
TensorFlow使用的求导方法称为自动微分(Automatic Differentiation),它既不是符号求导也不是数值求导,而类似于将两者结合的产物。
最基本的原理就是链式法则,关键思想是在基本操作(op)的水平上应用符号求导,并保持中间结果(grad)。
基本操作的符号求导定义在\tensorflow\python\ops\math_grad.py文件中,这个文件中的所有函数都用RegisterGradient装饰器包装了起来,这些函数都接受两个参数op和grad,参数op是操作,第二个参数是grad是之前的梯度。
链式求导代码:

举个例子:




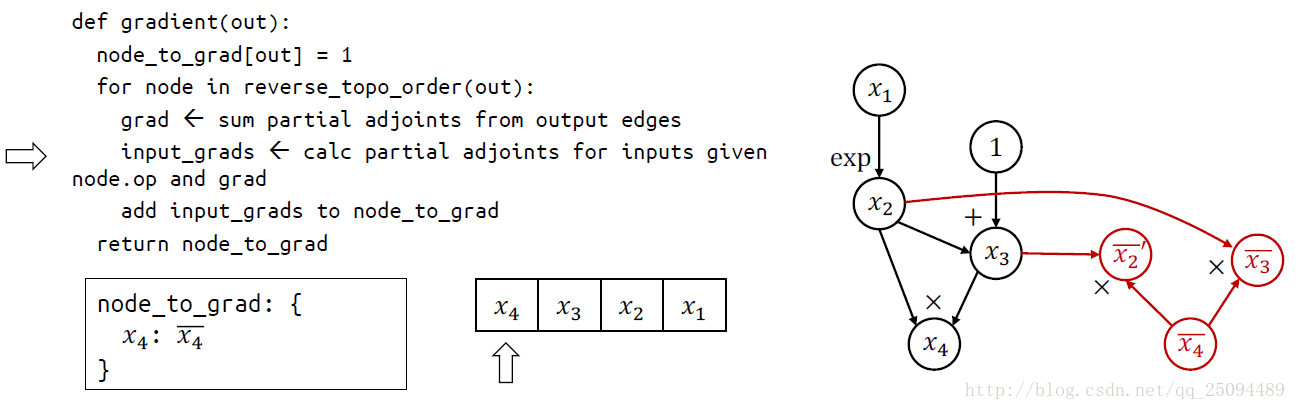



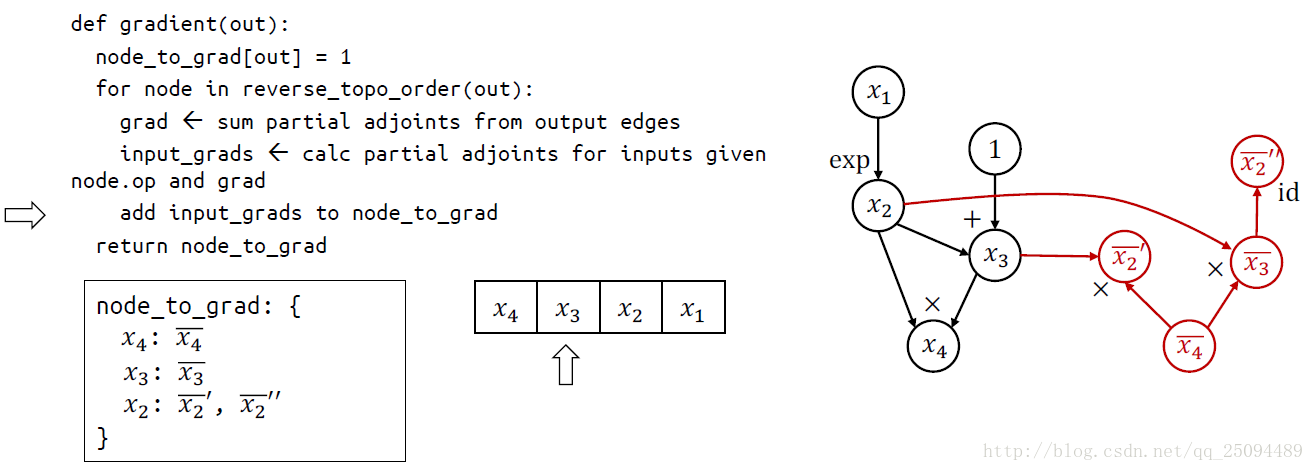

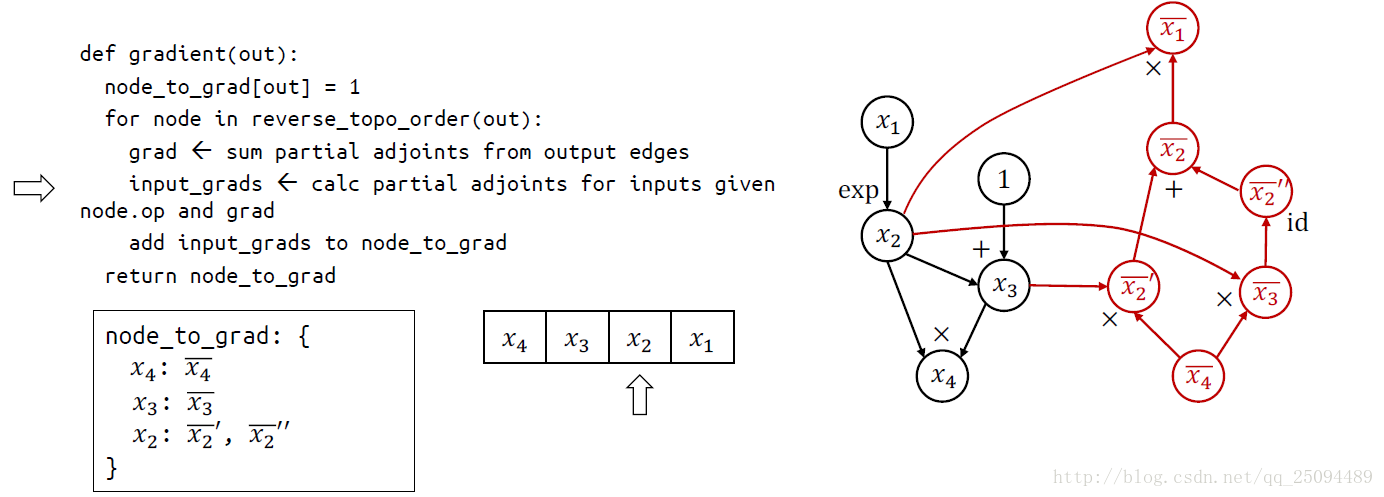

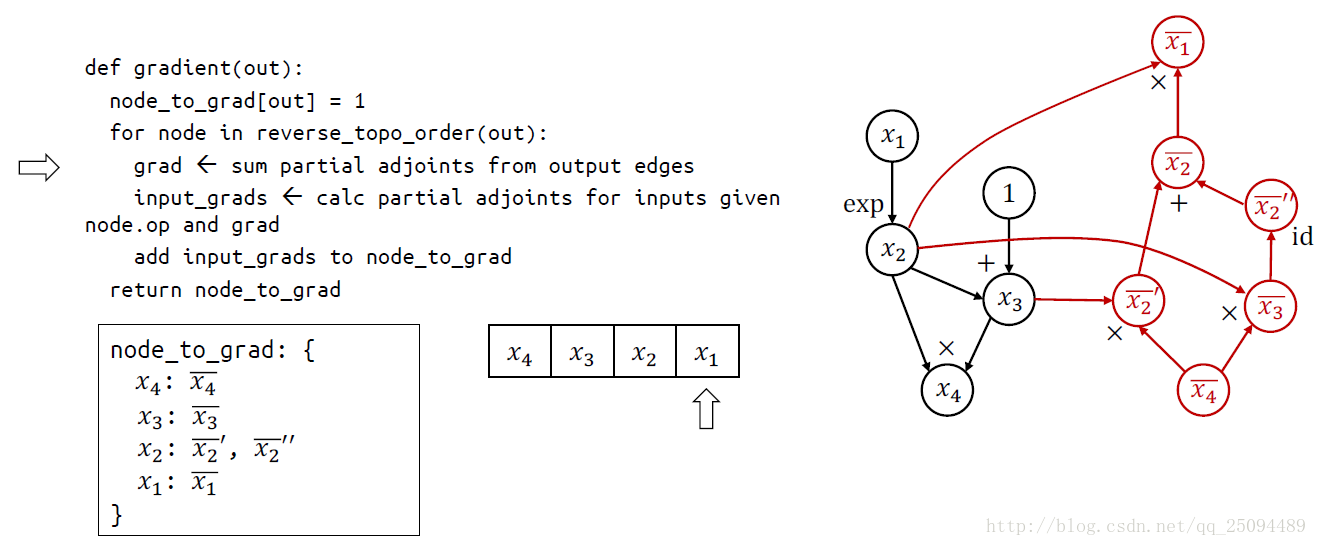
补充:聊聊Tensorflow自动求导机制
自动求导机制
在即时执行模式下,Tensorflow引入tf.GradientTape()这个“求导记录器”来实现自动求导。
计算函数y(x)=x^2在x = 3时的导数:
import tensorflow as tf
#定义变量
x = tf.Variable(initial_value = 3.)
#在tf.GradientTape()的上下文内,所有计算步骤都会被记录以用于求导
with tf.GradientTape() as tape:
#y = x^2
y = tf.square(x)
#计算y关于x的导数(斜率,梯度)
y_grad = tape.gradient(y,x)
print([y,y_grad])
输出:
[<tf.Tensor: shape=(), dtype=float32, numpy=9.0>, <tf.Tensor: shape=(), dtype=float32, numpy=6.0>]
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

使用tensorflow 实现反向传播求导
看代码吧~ X=tf.constant([-1,-2],dtype=tf.float32) w=tf.Variable([2.,3.]) truth=[3.,3.] Y=w*X # cost=tf.reduce_sum(tf.reduce_sum(Y*truth)/(tf.sqrt(tf.reduce_sum(tf.square(Y)))*tf.sqrt(tf.reduce_sum(tf.square(truth))))) cost=Y[1]*Y optimizer = tf.train.Gra
-
解决tensorflow 与keras 混用之坑
在使用tensorflow与keras混用是model.save 是正常的但是在load_model的时候报错了在这里mark 一下 其中错误为:TypeError: tuple indices must be integers, not list 再一一番百度后无结果,上谷歌后找到了类似的问题.但是是一对鸟文不知道什么东西(翻译后发现是俄文).后来谷歌翻译了一下找到了解决方法.故将原始问题文章贴上来警示一下 原训练代码 from tensorflow.python.keras.preproce
-
tensorflow中的梯度求解及梯度裁剪操作
1. tensorflow中梯度求解的几种方式 1.1 tf.gradients tf.gradients( ys, xs, grad_ys=None, name='gradients', colocate_gradients_with_ops=False, gate_gradients=False, aggregation_method=None, stop_gradients=None, unconnected_gradients=tf.UnconnectedGradients.NONE )
-
Python3安装tensorflow及配置过程
简介 TensorFlow 是一个端到端开源机器学习平台.它拥有一个全面而灵活的生态系统,其中包含各种工具.库和社区资源,可助力研究人员推动先进机器学习技术的发展,并使开发者能够轻松地构建和部署由机器学习提供支持的应用.那它能干什么用呢? 轻松地构建模型:在即刻执行环境中使用 Keras 等直观的高阶 API 轻松地构建和训练机器学习模型,该环境使我们能够快速迭代模型并轻松地调试模型. 随时随地进行可靠的机器学习生产:无论您使用哪种语言,都可以在云端.本地.浏览器中或设备上轻松地训练和部署模型.
-
Tensorflow 如何从checkpoint文件中加载变量名和变量值
假设你已经经过上千次的迭代,并且得到了以下模型: 则从这些checkpoint文件中加载变量名和变量值代码如下: model_dir = './ckpt-182802' import tensorflow as tf from tensorflow.python import pywrap_tensorflow reader = pywrap_tensorflow.NewCheckpointReader(model_dir) var_to_shape_map = reader.get_varia
-
TensorFlow的自动求导原理分析
原理: TensorFlow使用的求导方法称为自动微分(Automatic Differentiation),它既不是符号求导也不是数值求导,而类似于将两者结合的产物. 最基本的原理就是链式法则,关键思想是在基本操作(op)的水平上应用符号求导,并保持中间结果(grad). 基本操作的符号求导定义在\tensorflow\python\ops\math_grad.py文件中,这个文件中的所有函数都用RegisterGradient装饰器包装了起来,这些函数都接受两个参数op和grad,参数op是
-
关于PyTorch 自动求导机制详解
自动求导机制 从后向中排除子图 每个变量都有两个标志:requires_grad和volatile.它们都允许从梯度计算中精细地排除子图,并可以提高效率. requires_grad 如果有一个单一的输入操作需要梯度,它的输出也需要梯度.相反,只有所有输入都不需要梯度,输出才不需要.如果其中所有的变量都不需要梯度进行,后向计算不会在子图中执行. >>> x = Variable(torch.randn(5, 5)) >>> y = Variable(torch.rand
-
在 pytorch 中实现计算图和自动求导
前言: 今天聊一聊 pytorch 的计算图和自动求导,我们先从一个简单例子来看,下面是一个简单函数建立了 yy 和 xx 之间的关系 然后我们结点和边形式表示上面公式: 上面的式子可以用图的形式表达,接下来我们用 torch 来计算 x 导数,首先我们创建一个 tensor 并且将其requires_grad设置为True表示随后反向传播会对其进行求导. x = torch.tensor(3.,requires_grad=True) 然后写出 y = 3*x**2 + 4*x + 2 y.ba
-
Spring Boot自动注入的原理分析
前言 我们经常会被问到这么一个问题:SpringBoot相对于spring有哪些优势呢?其中有一条答案就是SpringBoot自动注入.那么自动注入的原理是什么呢? 我们进行如下分析. 1:首先我们分析项目的启动类时,发现都会加上@SpringBootApplication这个注解,我们分析这个继续进入这个注解会发现,它是由多个注解组成的,如下 @Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @Documented @I
-
浅谈Pytorch中的自动求导函数backward()所需参数的含义
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿. 对标量自动求导 首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的. import torch from torch.autograd import Variable a = Variable(torch.Te
-
Pytorch自动求导函数详解流程以及与TensorFlow搭建网络的对比
一.定义新的自动求导函数 在底层,每个原始的自动求导运算实际上是两个在Tensor上运行的函数.其中,forward函数计算从输入Tensor获得的输出Tensors.而backward函数接收输出,Tensors对于某个标量值得梯度,并且计算输入Tensors相对于该相同标量值得梯度. 在Pytorch中,可以容易地通过定义torch.autograd.Function的子类实现forward和backward函数,来定义自动求导函数.之后就可以使用这个新的自动梯度运算符了.我们可以通过构造一
-
pytorch中的自定义反向传播,求导实例
pytorch中自定义backward()函数.在图像处理过程中,我们有时候会使用自己定义的算法处理图像,这些算法多是基于numpy或者scipy等包. 那么如何将自定义算法的梯度加入到pytorch的计算图中,能使用Loss.backward()操作自动求导并优化呢.下面的代码展示了这个功能` import torch import numpy as np from PIL import Image from torch.autograd import gradcheck class Bicu
-
Pytorch中的自动求梯度机制和Variable类实例
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性:Varibale的Tensor本身的.data,对应Tensor的梯度.grad,以及这个Variable是通过什么方式得到的.grad_fn,根据最新消息,在pytorch0.4更新后,torch和torch.autograd.Variab
-
python人工智能自定义求导tf_diffs详解
目录 自定义求导:(近似求导数的方法) 多元函数的求导 在tensorflow中的求导 使用tf.GradientTape() 对常量求偏导 求二阶导数的方法 结合optimizers进行梯度下降法 自定义求导:(近似求导数的方法) 让x向左移动eps得到一个点,向右移动eps得到一个点,这两个点形成一条直线,这个点的斜率就是x这个位置的近似导数. eps足够小,导数就足够真. def f(x): return 3. * x ** 2 + 2. * x - 1 def approximate_d