C语言数据存储详解
目录
- 一、数据类型
- 二、整型在内存中的存储
- 1.原码、反码、补码
- 大小端介绍
- 三、浮点型在内存中的存储
- 1.举一个浮点数存储的例子:
- 2.浮点数存储规则:
- 总结
一、数据类型
char:字符数字类型。有无符号取决于编译器,大部分编译器有符号(signed char)
而short、int、long都是有符号的。
unsigned char c1=255;内存中存放二进制的补码:11111111 都是有效位,没有符号位
char c2=255;结果为-1

同理可推出short、int等
二、整型在内存中的存储
1.原码、反码、补码
原码:将二进制按照正负数的形式翻译成二进制
反码:将原码的符号位不变,其他位依次按位取反
补码:反码+1
**对于整型来说:数据存放在内存中的是补码。**使用补码,可以将符号位和数值域统一处理。
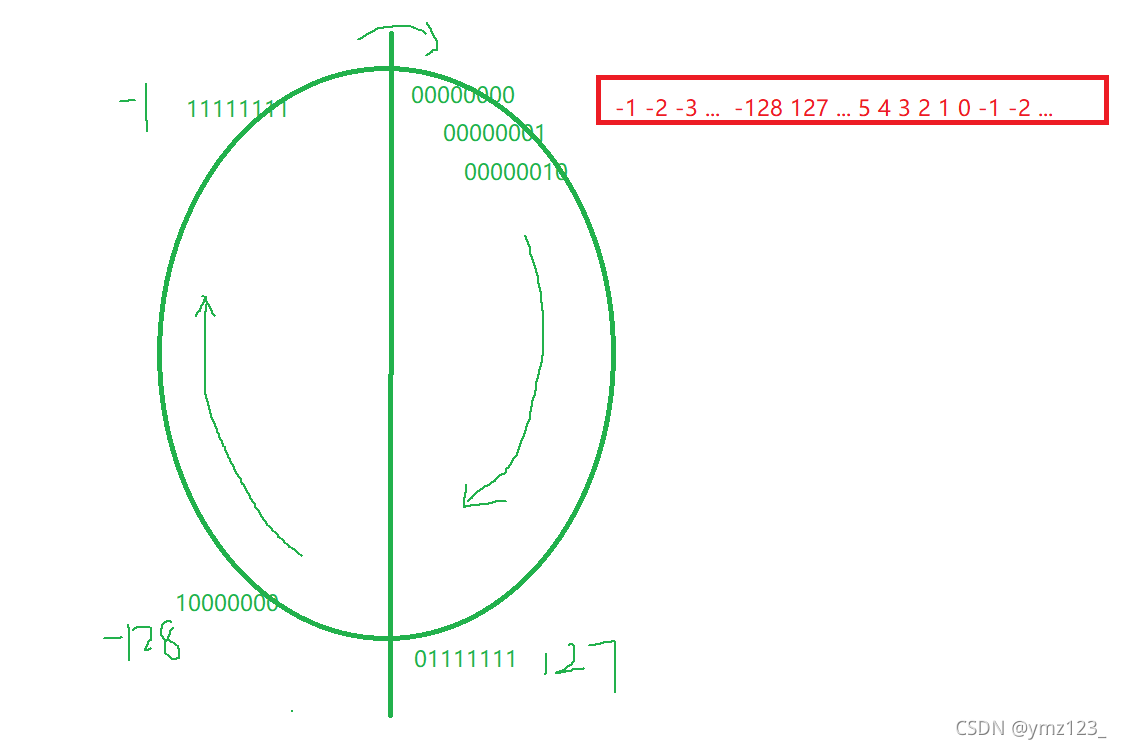
大小端介绍
1.大端字节序存储:是指数据的低位保存在内存的高地址中,数据的高位保存在内存的低地址中。
2.小段字节序存储:是指数据的低位保存在内存的低地址中,数据的高位保存在内存的高地址中。
例1:
#include<stdio.h>int main(){//输出什么?//有符号数整型提升:根据符号位提升高位//无符号数整型提升:高位补0char a = -1; //11111111//11111111111111111111111111111111//11111111111111111111111111111110//10000000000000000000000000000001 原码signed char b = -1; //与a相同unsigned char c = -1; //11111111//00000000000000000000000011111111//00000000000000000000000011111111//00000000000000000000000011111111//%d 以有符号数进行打印printf("a=%d,b=%d,c=%d", a, b, c); //a=-1,b=-1;c=255return 0;}
例2:

以无符号数形式打印,无原码补码反码概念,该补码就是打印出的数字
例3:

例4:
int main(){char a[1000];int i;for (i = 0;i < 1000;i++){a[i] = -1 - i;}printf("%d", strlen(a)); //255return 0;}
当a[i]到第255个数字时停止,因为i到254时a[i]为0,即\0
三、浮点型在内存中的存储
1.举一个浮点数存储的例子:
2.浮点数存储规则:
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。
那么,按照上面V的格式,可以得出s=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,s=1,M=1.01,E=2。
IEEE 754规定:对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0255;如果E为11位,它的取值范围为02047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
然后,指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1:
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。比如:0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1),其阶码为-1+127=126,表示为01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为: 0 01111110 00000000000000000000000
E全为0:
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
E全为1:
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s)
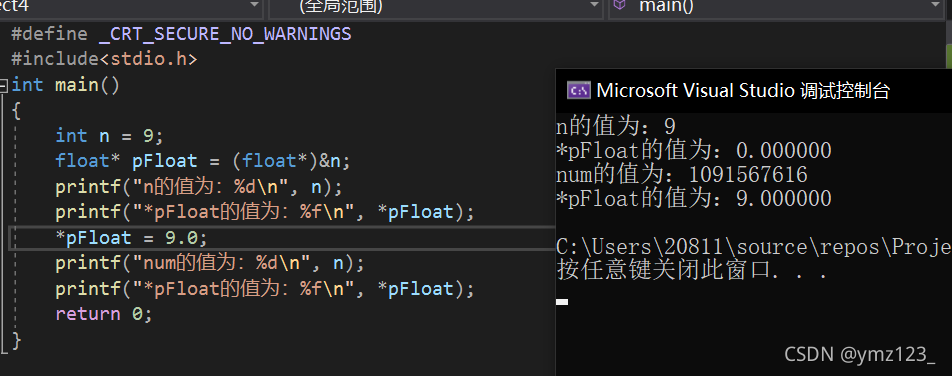
下面,让我们回到一开始的问题:为什么 0x00000009 还原成浮点数,就成了 0.000000 ?
首先,将 0x00000009 拆分,s=0,E=00000000 ,最后23位的有效数字M=000 0000 0000 0000 0000 1001。
由于指数E全为0,所以符合上一节的第二种情况。因此,浮点数V就写成:
V=(-1)^0 × 0.00000000000000000001001×2(-126)=1.001×2(-146)
显然,V是一个很小的接近于0的正数,所以用十进制小数表示就是0.000000。
第二部分:9.0 -> 1001.0 ->(-1)01.00123 -> s=0, M=1.001,E=3+127=130
那么,第一位的符号位s=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130, 即10000010。
所以,写成二进制形式,应该是s+E+M,即0 10000010 001 0000 0000 0000 0000 0000
这个32位的二进制数,还原成十进制,正是 1091567616
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
C语言 数据存储方式知识点详解
C语言 数据存储方式 一.源码 一个数的原码(原始的二进制码)有如下特点: 最高位做为符号位,0表示正,为1表示负 其它数值部分就是数值本身绝对值的二进制数 负数的原码是在其绝对值的基础上,最高位变为1 下面数值以1字节的大小描述: 十进制数 原码 +15 0000 1111 -15 1000 1111 +0 0000 0000 -0 1000 0000 注:原码表示法简单易懂,与带符号数本身转换方便,只要符号还原即可,但当两个正数相减或不同符号数相加时,必须比较两个数哪个绝对值大,才能决定谁减
-

C语言数据的存储和取出详细讲解
数据的存储和取出 整形的储存 我们知道一个整形的存储是以补码的形式储存取出是原码的形式. 比如:int a = 5;的二进制是101 那它的原码应该是:00000000 00000000 00000000 00000101 正数的原反补相同那它存进去和取出来都是:00000000 00000000 00000000 00000101 那float a = 5.5;也是四个字节它和整形存储的方式一样吗? 浮点型的储存方式 例子: #define _CRT_SECURE_NO_WARNINGS 1
-
C语言数据在内存中的存储详解
目录 文章摘要 一.C语言的数据类型 数据类型基本分为: 二.隐式类型转换 1.什么是隐式类型转换 2.整型提升 3.类型转换 三.机器大小端 1.什么是大小端 2.大小端在截断的应用 3.判断当前机器的字节序是大端还是小端 四.整型在内存中的存储 1.原码.反码.补码 2.举例实践整型数据在内存的存储 总结 文章摘要 本文通过内存底层原理,帮你透彻了解数据存储进内存与从内存中读取的区别以及不同数据类型下数据计算.赋值的变化情况 要透彻理解这些,必须知道隐式类型转换以及机器大小端的概念,本文会对
-
C语言编程数据在内存中的存储详解
目录 变量在计算机中有三种表示方式,原码反码,补码 原码 反码 补码 总结一下 浮点数在内存的储存 C语言中,有几种基本内置类型. int unsigned int signed int char unsigned char signed char long unsigned long signed long float double 在内存中创建变量,会在内存中开辟空间,并为其赋值. int a=10; 在计算机中,所有数据都是以二进制的形式存储在内存中. 变量在计算机中有三种表示方式,原码反
-
带你了解C语言的数据的存储
目录 C语言当中使用的数据类型 使用的类型 整型类 浮点类型 内存当中的存储 原码.反码.补码 大小端 什么是大小端 浮点数的存储 浮点数的存储 浮点数的存储规则 指数 E 从内存当中取出 总结 C语言当中使用的数据类型 使用的类型 char 字符数据类型 short 短整型 int 整形 long 长整型 long long 更长的整形 float 单精度浮点数 double 双精度浮点数 这些里面又分为整型和浮点型 整型类 整型又分为有符号整型和无符号整型,[int] 可以省略掉,就像 sh
-
C语言数据存储详解
目录 一.数据类型 二.整型在内存中的存储 1.原码.反码.补码 大小端介绍 三.浮点型在内存中的存储 1.举一个浮点数存储的例子: 2.浮点数存储规则: 总结 一.数据类型 char:字符数字类型.有无符号取决于编译器,大部分编译器有符号(signed char) 而short.int.long都是有符号的. unsigned char c1=255;内存中存放二进制的补码:11111111 都是有效位,没有符号位 char c2=255;结果为-1 同理可推出short.int等 二.整型在
-
IOS 数据存储详解及实例代码
iOS应用数据存储的常用方式 XML属性列表(plist)归档 Preference(偏好设置) NSKeyedArchiver归档(NSCoding) SQLite3 Core Data 1. XML属性列表(plist)归档 每个iOS应用都有自己的应用沙盒(应用沙盒就是文件系统目录),与其他文件系统隔离.应用必须待在自己的沙盒里,其他应用不能访问该沙盒. 应用沙盒结构分析: 应用程序包:包含了所有的资源文件和可执行文件 Documents:保存应用运行时生成的需要持久化的数据,iTunes
-
java8中NIO缓冲区(Buffer)的数据存储详解
java8新特性NIO缓冲区(Buffer)的数据存储. ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatBuffer, DoubleBuffer. 1.缓冲区在java nio中负责数据的存储.缓冲区就是数组.用于存储不同数据类型的数据.根据数据类型不同(boolean除外),提供了相应类型的缓冲区. ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatB
-
基于R语言 数据检验详解
目录 1.W检验(Shapiro–Wilk(夏皮罗–威克尔)W统计量检验) 2.K检验(经验分布的Kolmogorov-Smirnov检验) 3.相关性检验: 4.T检验 5.正态总体方差检验 6.二项分布总体假设检验 7.Pearson拟合优度χ2检验 8.Fisher精确的独立检验: 9.McNemar检验: 10.秩相关检验 11.Wilcoxon秩检验 1. W检验(Shapiro–Wilk (夏皮罗–威克尔 ) W统计量检验) 目标:检验数据是否符合某正态分布,如:标准正态分布N(0,
-
C语言数据的存储详解
目录 数据类型的介绍 整形 浮点型 构造类型 指针类型 void空类型 整数在内存中的存储 原反补的介绍 大小端的介绍 面试例题 练习 浮点数在内存中的存储 存储规则讲解 举例 IEEE754的特别规定 案例 float用%d打印的特例讲解 数据类型的介绍 数据类型存在的意义 为变量开辟的空间大小(大小决定了使用范围) 取数据的时候按照什么格式取出(先看大小端,在看数据类型(用来解析二进制数据的方式)) 整形 char unsigned char signed char short unsign
-
C语言数据结构之单链表存储详解
目录 1.定义一个链表结点 2.初始化单链表 3.输出链表数据 4.完整代码 如果说,顺序表的所占用的内存空间是连续的,那么链表则是随机分配的不连续的,那么为了使随机分散的内存空间串联在一起形成一种前后相连的关系,指针则起到了关键性作用. 单链表的基本结构: 头指针:永远指向链表第一个节点的位置. 头结点:不存任何数据的空节点,通常作为链表的第一个节点.对于链表来说,头节点不是必须的,它的作用只是为了方便解决某些实际问题. 首元结点:首个带有元素的结点. 其他结点:链表中其他的节点. 1.定义一
-
MySQL教程数据定义语言DDL示例详解
目录 1.SQL语言的基本功能介绍 2.数据定义语言的用途 3.数据库的创建和销毁 4.数据库表的操作(所有演示都以student表为例) 1)创建表 2)修改表 3)销毁表 如果你是刚刚学习MySQL的小白,在你看这篇文章之前,请先看看下面这些文章.有些知识你可能掌握起来有点困难,但请相信我,按照我提供的这个学习流程,反复去看,肯定可以看明白的,这样就不至于到了最后某些知识不懂却不知道从哪里下手去查. <MySQL详细安装教程> <MySQL完整卸载教程> <这点基础都不懂
-
R语言使用cgdsr包获取TCGA数据示例详解
目录 TCGA数据源 TCGA数据库探索工具 查看任意数据集的样本列表方式 选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据 选定样本列表获取临床信息 综合性获取 下载mRNA数据 获取病例列表的临床数据 从cBioPortal下载点突变信息 从cBioPortal下载拷贝数变异数据 把拷贝数及点突变信息结合画热图 TCGA数据源 众所周知,TCGA数据库是目前最综合全面的癌症病人相关组学数据库,包括的测序数据有: DNA Sequencing miRNA Sequencing P