Python实战快速上手BeautifulSoup库爬取专栏标题和地址
目录
- 安装
- 解析标签
- 解析属性
- 根据class值解析
- 根据ID解析
- 多层筛选
- 提取a标签中的网址
- 实战-获取博客专栏 标题+网址
BeautifulSoup库快速上手
安装
pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
使用PyCharm的命令行

解析标签
from bs4 import BeautifulSoup
import requests
url='https://blog.csdn.net/weixin_42403632/category_11076268.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
s=BeautifulSoup(html,'html.parser')
title =s.select('h2')
for i in title:
print(i.text)
第一行代码:导入BeautifulSoup库
第二行代码:导入requests
第三、四、五行代码:获取url的html
第六行代码:激活BeautifulSoup库 'html.parser'设置解析器为HTML解析器
第七行代码:选取所有<h2>标签

解析属性
BeautifulSoup库 支持根据特定属性解析网页元素
根据class值解析
from bs4 import BeautifulSoup
import requests
url='https://blog.csdn.net/weixin_42403632/category_11076268.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
s=BeautifulSoup(html,'html.parser')
title =s.select('.column_article_title')
for i in title:
print(i.text)

根据ID解析
from bs4 import BeautifulSoup
html='''<div class="crop-img-before">
<img src="" alt="" id="cropImg">
</div>
<div id='title'>
测试成功
</div>
<div class="crop-zoom">
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-reduce">-</a><a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-add">+</a>
</div>
<div class="crop-img-after">
<div class="final-img"></div>
</div>'''
s=BeautifulSoup(html,'html.parser')
title =s.select('#title')
for i in title:
print(i.text)

多层筛选
from bs4 import BeautifulSoup
html='''<div class="crop-img-before">
<img src="" alt="" id="cropImg">
</div>
<div id='title'>
456456465
<h1>测试成功</h1>
</div>
<div class="crop-zoom">
<a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-reduce">-</a><a href="javascript:;" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="bt-add">+</a>
</div>
<div class="crop-img-after">
<div class="final-img"></div>
</div>'''
s=BeautifulSoup(html,'html.parser')
title =s.select('#title')
for i in title:
print(i.text)
title =s.select('#title h1')
for i in title:
print(i.text)
提取a标签中的网址
title =s.select('a')
for i in title:
print(i['href'])

实战-获取博客专栏 标题+网址
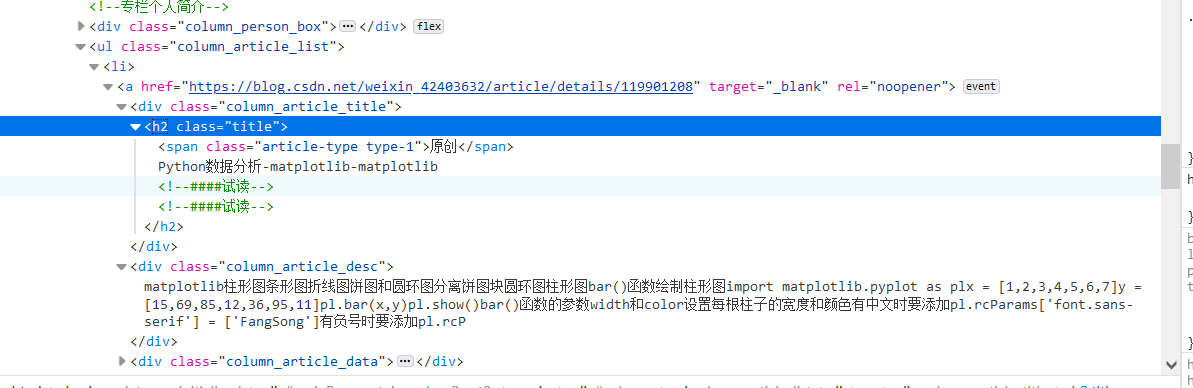
from bs4 import BeautifulSoup
import requests
import re
url='https://blog.csdn.net/weixin_42403632/category_11298953.html'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
html=requests.get(url,headers=headers).text
s=BeautifulSoup(html,'html.parser')
title =s.select('.column_article_list li a')
for i in title:
print((re.findall('原创.*?\n(.*?)\n',i.text))[0].lstrip())
print(i['href'])

到此这篇关于Python实战快速上手BeautifulSoup库爬取专栏标题和地址的文章就介绍到这了,更多相关Python BeautifulSoup库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
python BeautifulSoup库的安装与使用
1.BeautifulSoup简介 BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据. BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器. Beautiful Soup自动将输入文档转换为Unicode编码,
-
python数据解析BeautifulSoup爬取三国演义章节示例
目录 数据解析 Beautiful Soup Beautiful Soup用法 案例-爬取三国演义章节及对应的内容 数据解析 数据解析就是将爬取到的整个页面中的局部的内容进行提取.python中常用的数据解析方式有以下三种: bs4(python中独有的) xpath(推荐,通用型强) 正则 数据解析原理概述: 首先我们知道需要解析(提取)的内容都会在标签之间或者标签对应的属性中进行存储 所以我们需进行指定标签的定位 然后将标签或者标签对应的属性中存储的数据值进行提取(解析) Beautiful
-
Python BeautifulSoup基本用法详解(通过标签及class定位元素)
如下: 将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parser tmp_soup.select里面的参数为: div标签中class中带有listbg 下面 span标签中带有title,这种意思: 并且他们的类型如下: 都是ResultSet类型. 可以通过下面这种方式获取, find('某个标签')['中包含的域'] 当为li标签的时候,可以通过这样的方式获取: 到此这篇关于Python BeautifulSoup基本用法(通过标签及class定位元素)的
-
使用Python爬取小姐姐图片(beautifulsoup法)
Python有许多强大的库用于爬虫,如beautifulsoup.requests等,本文将以网站https://www.xiurenji.cc/XiuRen/为例(慎点!!),讲解网络爬取图片的一般步骤. 为什么选择这个网站?其实与网站的内容无关.主要有两项技术层面的原因:①该网站的页面构造较有规律,适合新手对爬虫的技巧加强认识.②该网站没有反爬虫机制,可以放心使用爬虫. 第三方库需求 beautifulsoup requests 步骤 打开网站,点击不同的页面: 发现其首页是https://
-
Python实战快速上手BeautifulSoup库爬取专栏标题和地址
目录 安装 解析标签 解析属性 根据class值解析 根据ID解析 多层筛选 提取a标签中的网址 实战-获取博客专栏 标题+网址 BeautifulSoup库快速上手 安装 pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 使用PyCharm的命令行 解析标签 from bs4 import BeautifulS
-
python实战之Scrapy框架爬虫爬取微博热搜
前言:大概一年前写的,前段时间跑了下,发现还能用,就分享出来了供大家学习,代码的很多细节不太记得了,也尽力做了优化. 因为毕竟是微博,反爬技术手段还是很周全的,怎么绕过反爬的话要在这说都可以单独写几篇文章了(包括网页动态加载,ajax动态请求,token密钥等等,特别是二级评论,藏得很深,记得当时想了很久才成功拿到),直接上代码. 主要实现的功能: 0.理所应当的,绕过了各种反爬. 1.爬取全部的热搜主要内容. 2.爬取每条热搜的相关微博. 3.爬取每条相关微博的评论,评论用户的各种详细信息.
-
python实战项目scrapy管道学习爬取在行高手数据
目录 爬取目标站点分析 编码时间 爬取结果展示 爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据. 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示. 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕. class ZaihangItem(scrapy.Item): # define the fields for your item here like: name
-
通过python爬虫mechanize库爬取本机ip地址的方法
目录 需求分析 实现分析 实际使用 完整代码演示 需求分析 最近,各平台更新的ip属地功能非常火爆,因此呢,也出现了许多新的网络用语,比如说“xx加几分”,“xx扣大分”等等,非常的有趣啊 可是呢,最近一个小伙伴和我说,“仙草哥哥,我也想查看一下自己的ip地址,可是我不会啊,我应该怎么样才能查看到自己的ip地址呢?” 关于如何查看自己的ip地址,这个我记得我在很早之前已经写过了,有兴趣的话可以查看一下我的这篇文章,当然这次呢,我会换一个复古的方式,使用mechanize进行爬取 实现分析 pyt
-
Python用requests库爬取返回为空的解决办法
首先介紹一下我們用360搜索派取城市排名前20. 我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html 我们要爬取的内容: html字段: robots协议: 现在我们开始用python IDLE 爬取 import requests r = requests.get("https://baike.so.com/doc/24368318-25185095.html") r.status_code r.text 结果分析,我们可以
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
python使用requests库爬取拉勾网招聘信息的实现
按F12打开开发者工具抓包,可以定位到招聘信息的接口 在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字 使用python构建post请求 data = { 'first': 'true', 'pn': '1', 'kd': 'python' } headers = { 'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&a
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模