几行代码让 Python 函数执行快 30 倍
目录
- 1、Python 多线程处理的基本指南
- 2、多处理入门
- 3、它为什么如此重要?
- 4、实现
- 5、基准测试
Python 是一种流行的编程语言,也是数据科学社区中最受欢迎的语言。与其他流行编程语言相比,Python 的主要缺点是它的动态特性和多功能属性拖慢了速度表现。Python 代码是在运行时被解释的,而不是在编译时被编译为原生代码。
1、Python 多线程处理的基本指南
C 语言的执行速度比 Python 代码快 10 到 100 倍。但如果对比开发速度的话,Python 比 C 语言要快。对于数据科学研究来说,开发速度远比运行时性能更重要。由于存在大量 API、框架和包,Python 更受数据科学家和数据分析师的青睐,只是它在性能优化方面落后太多了。
2、多处理入门
考虑一个单核心 CPU,如果它被同时分配多个任务,就必须不断地中断当前执行的任务并切换到下一个任务才能保持所有进程正常运行。对于多核处理器来说,CPU 可以在不同内核中同时执行多个任务,这一概念被称为并行处理。
3、它为什么如此重要?
数据整理、特征工程和数据探索都是数据科学模型开发管道中的重要元素。在输入机器学习模型之前,原始数据需要做工程处理。对于较小的数据集来说,执行过程只需几秒钟就能完成;但对于较大的数据集而言,这项任务就比较繁重了。
并行处理是提高 Python 程序性能的一种有效方法。Python 有一个多处理模块,让我们能够跨 CPU 的不同内核并行执行程序。
4、实现
我们将使用来自 multiprocessing 模块的 Pool 类,针对多个输入值并行执行一个函数。这个概念称为数据并行性,它是 Pool 类的主要目标。
我将使用从
Kaggle下载的Quora问题对相似性数据 集来演示这个模块。
上述数据集包含了很多在 Quora 平台上提出的文本问题。我将在一个 Python 函数上执行多处理模块,这个函数通过删除停用词、删除 HTML 标签、删除标点符号、词干提取等过程来处理文本数据。
preprocess()就是执行上述文本处理步骤的函数。
可以在 这里 找到托管在我的 GitHub 上的函数 preprocess() 的代码片段。
现在,我们使用 multiprocessing 模块中的 Pool 类为数据集的不同块并行执行该函数。数据集的每个块都将并行处理。
import multiprocessing
from functools import partial
from QuoraTextPreprocessing import preprocess
BUCKET_SIZE = 50000
def run_process(df, start):
df = df[start:start+BUCKET_SIZE]
print(start, "to ",start+BUCKET_SIZE)
temp = df["question"].apply(preprocess)
chunks = [x for x in range(0,df.shape[0], BUCKET_SIZE)]
pool = multiprocessing.Pool()
func = partial(run_process, df)
temp = pool.map(func,chunks)
pool.close()
pool.join()
该数据集有 537,361 条记录(文本问题)需要处理。对于 50,000 的桶大小,数据集被分成 11 个较小的数据块,这些块可以并行处理以加快程序的执行时间。
5、基准测试
人们常问的问题是使用多处理模块后执行速度能快多少。我在实现了数据并行性,对整个数据集执行一次 preprocess() 函数后对比了基准执行时间。
运行测试的机器有 64GB 内存和 10 个 CPU 内核。
多处理和单处理执行的基准时间:
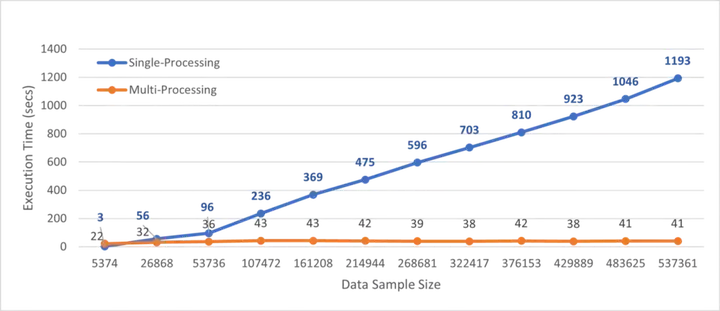
从上图中,我们可以观察到 Python 函数的并行处理将执行速度提高了近 30 倍。
我们可以在我的
GitHub中找到用于记录基准测试数据的Python文件。
基准测试过程:

结 论:
在本文中,我们讨论了 Python 中多处理模块的实现,该模块可用于加速 Python 函数的执行。添加几行多处理代码后,具有 537k 实例的数据集的执行时间几乎快了 30 倍。
处理大型数据集的时候,我建议大家使用并行处理,因为它可以节省大量时间并加快工作流程。
到此这篇关于几行代码让 Python 函数执行快 30 倍的文章就介绍到这了,更多相关Python 函数执行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用eval函数执行动态标表达式过程详解
英文文档: eval(expression, globals=None, locals=None) The arguments are a string and optional globals and locals. If provided, globals must be a dictionary. If provided, localscan be any mapping object. The expression argument is parsed and evaluated as
-
Python 执行字符串表达式函数(eval exec execfile)
仔细研读后学习了三个函数: eval:计算字符串中的表达式 exec:执行字符串中的语句 execfile:用来执行一个文件 需注意的是,exec是一个语句,而eval()和execfile()则是内建built-in函数. Python 2.7.2 (default, Jun 12 2011, 15:08:59) [MSC v.1500 32 bit (Intel)] on win32 Type "help", "copyright", "credits
-
python 执行函数的九种方法
方法一:直接调用函数运行 这种是最简单且直观的方法 def task(): print("running task") task() 如果是在类中,也是如此 class Task: def task(self): print("running task") Task().task() 方法二:使用偏函数来执行 在 functools 这个内置库中,有一个 partial 方法专门用来生成偏函数. def power(x, n):
-
python 轮询执行某函数的2种方式
目标:python中每隔特定时间执行某函数 方法1:使用python的Thread类的子类Timer,该子类可控制指定函数在特定时间后执行一次: 所以为了实现多次定时执行某函数,只需要在一个while循环中多次新建Timer即可. from threading import Timer import time def printHello(): print ("Hello") print("当前时间戳是", time.time()) def loop_func(fu
-
Python利用PyExecJS库执行JS函数的案例分析
在Web渗透流程的暴力登录场景和爬虫抓取场景中,经常会遇到一些登录表单用DES之类的加密方式来加密参数,也就是说,你不搞定这些前端加密,你的编写的脚本是不可能Login成功的.针对这个问题,现在有三种解决方式: ①看懂前端的加密流程,然后用脚本编写这些方法(或者找开源的源码),模拟这个加密的流程.缺点是:不懂JS的话,看懂的成本就比较高了: ②selenium + Chrome Headless.缺点是:因为是模拟点击,所以效率相对①.③低一些: ③使用语言调用JS引擎来执行JS函数.缺点是
-
解决python调用自己文件函数/执行函数找不到包问题
写python程序的时候很多人习惯创建一个utils.py文件,存放一些经常使用的函数,方便其他文件调用,同时也更好的管理一些通用函数,方便今后使用.或是两个文件之间的class或是函数调用情况. 就像下面的工程目录一样: 工程目录 Project\ ... src\ main.py utils.py test.py ... python调用其他文件中的函数 在main.py文件中加入一下语句即可调用utils.py下面的函数:'' import src.utils as utils X, y
-

几行代码让 Python 函数执行快 30 倍
目录 1.Python 多线程处理的基本指南 2.多处理入门 3.它为什么如此重要? 4.实现 5.基准测试 Python 是一种流行的编程语言,也是数据科学社区中最受欢迎的语言.与其他流行编程语言相比,Python 的主要缺点是它的动态特性和多功能属性拖慢了速度表现.Python 代码是在运行时被解释的,而不是在编译时被编译为原生代码. 1.Python 多线程处理的基本指南 C 语言的执行速度比 Python 代码快 10 到 100 倍.但如果对比开发速度的话,Python 比 C 语言要
-
几行代码让 Python 函数执行快 30 倍
目录 1.Python 多线程处理的基本指南 2.多处理入门 3.它为什么如此重要? 4.实现 5.基准测试 Python 是一种流行的编程语言,也是数据科学社区中最受欢迎的语言.与其他流行编程语言相比,Python 的主要缺点是它的动态特性和多功能属性拖慢了速度表现.Python 代码是在运行时被解释的,而不是在编译时被编译为原生代码. 1.Python 多线程处理的基本指南 C 语言的执行速度比 Python 代码快 10 到 100 倍.但如果对比开发速度的话,Python 比 C 语言要
-
500行代码使用python写个微信小游戏飞机大战游戏
这几天在重温微信小游戏的飞机大战,玩着玩着就在思考人生了,这飞机大战怎么就可以做的那么好,操作简单,简单上手. 帮助蹲厕族.YP族.饭圈女孩在无聊之余可以有一样东西让他们振作起来!让他们的左手 / 右手有节奏有韵律的朝着同一个方向来回移动起来! 这是史诗级的发明,是浓墨重彩的一笔,是-- 在一阵抽搐后,我结束了游戏,瞬时觉得一切都索然无味,正在我进入贤者模式时,突然想到,如果我可以让更多人已不同的方式体会到这种美轮美奂的感觉岂不美哉? 所以我打开电脑,创建了一个 plan_game.py-- 先
-
不到20行代码用Python做一个智能聊天机器人
伴随着自然语言技术和机器学习技术的发展,越来越多的有意思的自然语言小项目呈现在大家的眼前,聊天机器人就是其中最典型的应用,今天小编就带领大家用不到20行代码,运用两种方式搭建属于自己的聊天机器人. 1.神器wxpy库 首先,小编先向大家介绍一下本次运用到的python库,本次项目主要运用到的库有wxpy和chatterbot. wxpy是在 itchat库 的基础上,通过大量接口优化,让模块变得简单易用,并进行了功能上的扩展.什么是接口优化呢,简单来说就是用户直接调用函数,并输入几个参数,就可以
-
程序员的七夕用30行代码让Python化身表白神器
转眼又到了咱们中国传统的情人节七夕了,今天笔者就带大家来领略一下用Python表白的方式.让程序员的恋人们感受一下IT人的浪漫. 一.词云制作 首先咱们可以用之前介绍过的wordcould包制作词云.wordcloud包安装十分简单.pip即可完成安装 pip install wordclould 然后需要制作一个背景图片,为了应急我用艺术字做了个七夕的图片,如果大家来不及直接图片另存为使用下图即可. 具体制作的词云的代码如下: from wordcloud import WordClou
-
用60行代码实现Python自动抢微信红包
春节来到,红包们大概率在微信各大群中肆虐,大家是否都一样不抢到红包们心里就感觉错过了一个亿,可总会被这事那事耽误而遗憾错过,下面用 Python 写一个自动抢红包代码 启动入口 启动程序的配置和公众号文章<用 Python + Appium 的方式自动化清理微信僵尸好友>的配置一样 from appium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui
-
8行代码实现Python文件去重
目录 需求描述 撸代码ing 需求描述 上周突然接到一个任务,要通过XX网站导出XX年-XX年之间的数据,导出后的文件名就是对应日期,导出后发现,竟然有的文件大小是一样,但文件名又没有重复,所以打开文件看了下,确实重复了,原因暂时不清楚,预测是网站的原因,最后发现大概只有 30% 的数据没有重复.我淦! 啥也不说,首要任务还是把那些没有重复的文件给筛选出来,或是删除重复的文件.文件很多几百个,通过一个个的对比文件去删除估计又要加班,然后突然想到 Python 有个内置的 filecmp 能够貌似
-
一行代码让 Python 的运行速度提高100倍
python一直被病垢运行速度太慢,但是实际上python的执行效率并不慢,慢的是python用的解释器Cpython运行效率太差. "一行代码让python的运行速度提高100倍"这绝不是哗众取宠的论调. 我们来看一下这个最简单的例子,从1一直累加到1亿. 最原始的代码: import time def foo(x,y): tt = time.time() s = 0 for i in range(x,y): s += i print('Time used: {} sec'.form
-
如何在Python函数执行前后增加额外的行为
首先来看一个小程序,这个是计量所花费时间的程序,以下是以往的解决示例 from functools import wraps, partial from time import time def timing(func=None, frequencies=1): if func is None: # print("+None") return partial(timing, frequencies=frequencies) # else: # print("-None&quo
-
不到40行代码用Python实现一个简单的推荐系统
什么是推荐系统 维基百科这样解释道:推荐系统属于资讯过滤的一种应用.推荐系统能够将可能受喜好的资讯或实物(例如:电影.电视节目.音乐.书籍.新闻.图片.网页)推荐给使用者. 本质上是根据用户的一些行为数据有针对性的推荐用户更可能感兴趣的内容.比如在网易云音乐听歌,听得越多,它就会推荐越多符合你喜好的音乐. 推荐系统是如何工作的呢?有一种思路如下: 用户 A 听了 收藏了 a,b,c 三首歌.用户 B 收藏了 a, b 两首歌,这时候推荐系统就把 c 推荐给用户 B.因为算法判断用户 A,B 对音