Python编译结果之code对象与pyc文件详解
目录
- 1、Python程序执行过程
- 2、PyCodeObject对象与.pyc文件
- 3、pyc文件的生成
- 总结
1、Python程序执行过程
与java类似,Python将.py编译为字节码,然后通过虚拟机执行。编译过程与虚拟机执行过程均在python25.dll中。Python虚拟机比java更抽象,离底层更远。
编译过程不仅生成字节码,还要包含常量、变量、占用栈的空间等,Pyton中编译过程生成code对象PyCodeObject。将PyCodeObject写入二进制文件,即.pyc。
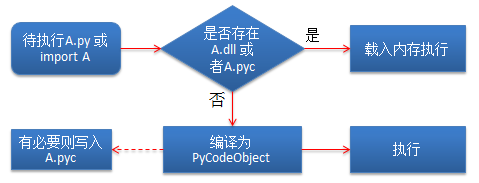
有必要则写入A.pyc指的是该.py是否只运行一次,如果import的模块,肯定会生成.pyc。
2、PyCodeObject对象与.pyc文件
Python解释器将.py程序编译为PyCodeObject对象,具体过程与编译原理类似。
typedef struct {
PyObject_HEAD
int co_argcount; // Code Block的参数的个数,比如说一个函数的参数
int co_nlocals; // Code Block中局部变量的个数
int co_stacksize; // 执行该段Code Block需要的栈空间
int co_flags; // N/A
PyObject *co_code; // Code Block编译所得的byte code,以PyStringObject的形式存在
PyObject *co_consts; // PyTupleObject对象,保存Code Block中的常量
PyObject *co_names; // PyTupleObject对象,保存Code Block中的所有符号
PyObject *co_varnames; // Code Block中局部变量名集合
PyObject *co_freevars; // 实现闭包所需东西
PyObject *co_cellvars; // Code Block内部嵌套函数所引用的局部变量名集合
PyObject *co_filename; // Code Block所对应的.py文件的完整路径
PyObject *co_name; // Code Block的名字,通常是函数名或类名
int co_firstlineno; // Code Block在对应的.py文件中的起始行
PyObject *co_lnotab; // byte code与.py文件中source code行号的对应关系,以PyStringObject的形式存在
void *co_zombieframe;
PyObject *co_weakreflist;
} PyCodeObject;
一个Code Block生成一个PyCodeObject,进入一个名字空间成为进入一个Code Block。如下.py文件编译完成后会生成三个PyCodeObject,一个对应整个.py文件一个对应Class A,一个对应def Fun。实际这三个code对象是嵌套的,后两个code对象位于第一个code对象的co_consts属性中。其实,字节码位于co_code中。
class A: pass def Fun(): pass a = A() Fun()
pyc文件包括三部分:
(1)四字节的Magic int,表示pyc版本信息
(2)四字节的int,是pyc产生时间,若与py文件时间不同会重新生成
(3)序列化了的PyCodeObject对象。
3、pyc文件的生成
写入pyc文件的函数包括以下几个步骤:
PyMarshal_WriteLongToFile(pyc_magic, fp, Py_MARSHAL_VERSION); // 写入版本信息 PyMarshal_WriteLongToFile(0L, fp, Py_MARSHAL_VERSION); // 写入时间信息 PyMarshal_WriteObjectToFile((PyObject *)co, fp, Py_MARSHAL_VERSION); // 写入PyCodeObject对象
关键在于code对象的写入:
{
WFILE wf;
wf.fp = fp;
……
w_object(x, &wf);
}
用到了一个WFILE结构体,可以认为是对FILE *fp 的一个封装:
typedef struct {
FILE *fp;
int error;
int depth;
PyObject *strings; // 存储字符串,写入时以dict形式,读出时以list形式
} WFILE;
关键在于w_object()函数:
static void w_object(PyObject *v, WFILE *p){
if (v == NULL) ……
else if (PyInt_CheckExact(v)) ……
else if (PyFloat_CheckExact(v)) ……
else if (PyString_CheckExact(v)) ……
else if (PyList_CheckExact(v)) ……
}
w_code实质为根据不同的对象类型选取不同的策略,例如tuple对象:
else if (PyTuple_CheckExact(v)) {
w_byte(TYPE_TUPLE, p);
n = PyTuple_Size(v);
W_SIZE(n, p);
for (i = 0; i < n; i++)
w_object(PyTuple_GET_ITEM(v, i), p);
而所有类型最终可分解为写入数值与写入字符串两种操作,涉及以下几部分:
#define w_byte(c, p) putc((c), (p)->fp) // 用于写入类型
static void w_long(long x, WFILE *p){ // 用于写入数字
w_byte((char)( x & 0xff), p); // 实质为用四个字节存储一个数字
w_byte((char)((x>> 8) & 0xff), p);
w_byte((char)((x>>16) & 0xff), p);
w_byte((char)((x>>24) & 0xff), p);
}
static void w_string(char *s, int n, WFILE *p){ //用于写入字符串
fwrite(s, 1, n, p->fp);
}
由于序列化写入文件后丢失了结构信息,故写入每个对象时写入类型信息w_byte:
#define TYPE_INT 'i'
#define TYPE_LIST '['
#define TYPE_DICT '{'
#define TYPE_CODE 'c'
由于Python皆对象,w_object(PyObject*)便可针对不同类型选取不同写入方法,不断细分,最终分解为PyInt_Object或PyString_Object,利用w_long或w_string写入。
数字比较简单:
else if (PyInt_CheckExact(v)) {
w_byte(TYPE_INT, p);
w_long(x, p);
}
字符串则比较复杂:
else if (PyString_CheckExact(v)) {
if (p->strings && PyString_CHECK_INTERNED(v)) {
PyObject *o = PyDict_GetItem(p->strings, v); // 获取在strings中的序号
if (o) { // inter对象的非首次写入
long w = PyInt_AsLong(o);
w_byte(TYPE_STRINGREF, p);
w_long(w, p);
goto exit;
}
else { // intern对象的首次写入
int ok;
ok = o && PyDict_SetItem(p->strings, v, o) >= 0;
Py_XDECREF(o);
w_byte(TYPE_INTERNED, p);
}
}
else { // 写入普通string
w_byte(TYPE_STRING, p);
}
n = PyString_GET_SIZE(v);
W_SIZE(n, p);
w_string(PyString_AS_STRING(v), n, p);
}
(1)若写入普通字符串,写入字符串类型信息"S",然后写入字符串长度及string值。
(2)若写入inter字符串,先到WFILE的strings中查找:
(a)若找到,则写入引用类型信息"R",然后写入序号
(b)若未找到,创建对象放入strings,并写入intern类型信息"t",然后写入字符串长度及string值。
若依次写入"efei"、"snow"、"efei",则会如下:
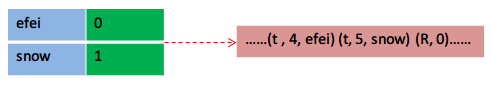
从pyc文件读入时,依靠list,那么序号就可以利用上了。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

python编译pyc文件的过程解析
什么是pyc文件 pyc是一种二进制文件,是由py文件经过编译后,生成的文件,是一种byte code,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚拟机来执行的,这个是类似于JAVA或者.NET的虚拟机的概念.pyc的内容,是跟python的版本相关的,不同版本编译后的pyc文件是不同的,2.5编译的pyc文件,2.4版本的 python是无法执行的. 什么是pyo文件 pyo是优化编译后的程序 python -O 源文件即可将源程序编译为p
-
浅谈python中str字符串和unicode对象字符串的拼接问题
str字符串 s = '中文' # s: <type 'str'> s是个str对象,中文字符串.存储方式是字节码.字节码是怎么存的: 如果这行代码在python解释器中输入&运行,那么s的格式就是解释器的编码格式: 如果这行代码是在源码文件中写入.保存然后执行,那么解释器载入代码时就将s初始化为文件指定编码(比如py文件开头那行的utf-8): unicode对象字符串 unicode是一种编码标准,具体的实现可能是utf-8,utf-16,gbk等等,这就是中文字符串和unicod
-
Python函数属性和PyC详解
目录 函数属性 自定义属性 查看函数对象属性 属性和字节码对象PyCodeObject 总结 函数属性 python中的函数是一种对象,它有属于对象的属性.除此之外,函数还可以自定义自己的属性.注意,属性是和对象相关的,和作用域无关. 自定义属性 自定义函数自己的属性方式很简单.假设函数名称为myfunc,那么为这个函数添加一个属性var1: myfunc.var1="abc" 那么这个属性var1就像是全局变量一样被访问.修改.但它并不是全局变量. 可以跨模块自定义函数的属性.例如,
-
Python编译结果之code对象与pyc文件详解
目录 1.Python程序执行过程 2.PyCodeObject对象与.pyc文件 3.pyc文件的生成 总结 1.Python程序执行过程 与java类似,Python将.py编译为字节码,然后通过虚拟机执行.编译过程与虚拟机执行过程均在python25.dll中.Python虚拟机比java更抽象,离底层更远. 编译过程不仅生成字节码,还要包含常量.变量.占用栈的空间等,Pyton中编译过程生成code对象PyCodeObject.将PyCodeObject写入二进制文件,即.pyc. 有必
-
python中requests库session对象的妙用详解
在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有时候需要保持一些共用的数据,例如cookies信息. 妙用1 requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies. 举个栗子,跨请求保持cookies,在命令行上输入下面命令: # 创建一个session对象 s = requests.Session() # 用session对象发出get请求,设置cookies s.get('http://ht
-
Python利用operator模块实现对象的多级排序详解
前言 最近在工作中碰到一个小的排序问题,需要按嵌套对象的多个属性来排序,于是发现了Python里的operator模块和sorted函数组合可以实现这个功能.本文介绍了Python用operator模块实现对象的多级排序的相关内容,分享出来供大家参考学习,下面来看看详细的介绍: 比如我有如下的类关系,A对象引用了一个B对象, class A(object): def __init__(self, b): self.b = b def __str__(self): return "[%s, %s,
-
Python中的类与对象之描述符详解
描述符(Descriptors)是Python语言中一个深奥但却重要的一部分.它们广泛应用于Python语言的内核,熟练掌握描述符将会为Python程序员的工具箱添加一个额外的技巧.为了给接下来对描述符的讨论做一些铺垫,我将描述一些程序员可能会在日常编程活动中遇到的场景,然后我将解释描述符是什么,以及它们如何为这些场景提供优雅的解决方案.在这篇总结中,我会使用新样式类来指代Python版本. 1.假设一个程序中,我们需要对一个对象属性执行严格的类型检查.然而,Python是一种动态语言,所以并不
-
对Python中小整数对象池和大整数对象池的使用详解
1. 小整数对象池 整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间. Python 对小整数的定义是 [-5, 256] 这些整数对象是提前建立好的,不会被垃圾回收.在一个 Python 的程序中,无论这个整数处于LEGB中的哪个位置, 所有位于这个范围内的整数使用的都是同一个对象.同理,单个字母也是这样的. In [1]: a=-5 In [2]: b=-5 In [3]: a is b Out[3]: True In [4]: a
-
python中类与对象之间的关系详解
在搜索平台上关于类以及对象都已经被霸屏了,主要的问题无非就是两个,一个是理解二者,另一个就是理解二者之间的使用关系,对于小编来说,两者统一跟大家讲清,相信也很难被大家消化,这不,给大家想出来比较好理解的方式,用最简单的话,快速交大家上手,可别不信,简单易懂内容如下. 二者关系: 女生口红是一种类,但是mac.完美日记是口红里的个体,被称作是对象.这就是二者之间的关系,有人理解成包含情况也可以. 定义类/对象: class 类名(父类): class Human(object): pass man
-
Python统计可散列的对象之容器Counter详解
一.初始化Counter Counter支持3种形式的初始化,比如提供一个数组,一个字典,或单独键值对"="式赋值.具体初始化的代码如下所示: import collections a = collections.Counter(['a', 'a', 'b', 'b', 'b', 'c']) b = collections.Counter({"a": 2, "b": 3, "c": 1}) c = collections.Co
-
python获取对象信息的实例详解
1.获取对象类型,基本类型可以用type()来判断. >>> type(123) <class 'int'> >>> type('str') <class 'str'> >>> type(None) <type(None) 'NoneType'> 2.如果想获得一个对象的所有属性和方法,可以使用dir()函数返回包含字符串的list. >>> dir('ABC') ['__add__', '__cl
-
python 函数中的内置函数及用法详解
今天来介绍一下Python解释器包含的一系列的内置函数,下面表格按字母顺序列出了内置函数: 下面就一一介绍一下内置函数的用法: 1.abs() 返回一个数值的绝对值,可以是整数或浮点数等. print(abs(-18)) print(abs(0.15)) result: 18 0.15 2.all(iterable) 如果iterable的所有元素不为0.''.False或者iterable为空,all(iterable)返回True,否则返回False. print(all(['a','b',
-
python学习字符串驻留与常量折叠隐藏特性详解
下面是Python字符串的一些微妙的特性,绝对会让你大吃一惊. 案例一: 案例二: 案例三: 很好理解, 对吧? 说明: 这些行为是由于 Cpython 在编译优化时, 某些情况下会尝试使用已经存在的不可变对象而不是每次都创建一个新对象. (这种行为被称作字符串的驻留[string interning]) 发生驻留之后, 许多变量可能指向内存中的相同字符串对象. (从而节省内存) 在上面的代码中, 字符串是隐式驻留的. 何时发生隐式驻留则取决于具体的实现. 这里有一些方法可以用来猜测字符串是否会