教你用Python爬取英雄联盟皮肤原画
一、推理原理
1.先去《英雄联盟》官网找到英雄及皮肤图片的网址:
http://lol.qq.com/data/info-heros.shtml

2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中。这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典——里面就包含了所有英雄的名字(英文)以及对应的编号。
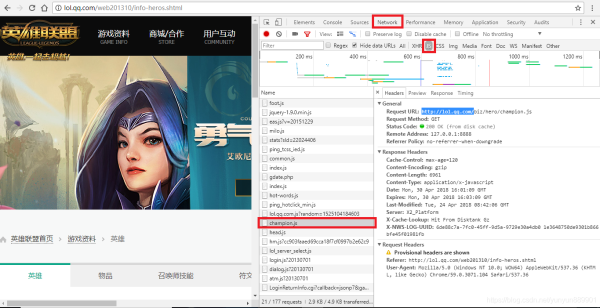
3.但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是回到网页,随便点开一个英雄,跳转页面后发现英雄及皮肤的图片都在,但要下载还需要找到原地址,这是鼠标右击选择“在新标签页中打开”,新的网页才是图片的原地址。

4.图中红色框就是我们需要的图片地址,经过分析知道:每一个英雄及皮肤的地址只有编号不一样(http://ossweb-img.qq.com/images/lol/web201310/skin/big266000.jpg),而该编号有6位,前3位表示英雄,后三位表示皮肤。刚才找到的js文件中恰好有英雄的编号,而皮肤的编码可以自己定义,反正每个英雄皮肤不超过20个,然后组合起来就可以了。
{kind=link}

二、推理代码
第一步:获取js字典
def path_js(url_js):
res_js = requests.get(url_js, verify = False).content
html_js = res_js.decode("gbk")
pat_js = r'"keys":(.*?),"data"'
enc = re.compile(pat_js)
list_js = enc.findall(html_js)
dict_js = eval(list_js[0])
return dict_js
第二步:从 js字典中提取到key值生成url列表
def path_url(dict_js):
pic_list = []
for key in dict_js:
for i in range(20):
xuhao = str(i)
if len(xuhao) == 1:
num_houxu = "00" + xuhao
elif len(xuhao) == 2:
num_houxu = "0" + xuhao
numStr = key+num_houxu
url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big'+numStr+'.jpg'
pic_list.append(url)
print(pic_list)
return pic_list
第三步:从 js字典中提取到value值生成name列表
def name_pic(dict_js, path):
list_filePath = []
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filePath.append(file_path)
return list_filePath

第四步:下载并保存数据
def writing(url_list, list_filePath):
try:
for i in range(len(url_list)):
res = requests.get(url_list[i], verify = False).content
with open(list_filePath[i], "wb") as f:
f.write(res)
except Exception as e:
print("下载图片出错,%s" %(e))
return False
第五步:执行主程序
if __name__ == '__main__':
url_js = r'http://lol.qq.com/biz/hero/champion.js'
path = r'./data/' #图片存在的文件夹
dict_js = path_js(url_js)
url_list = path_url(dict_js)
list_filePath = name_pic(dict_js, path)
writing(url_list, list_filePath)
运行后会在控制台打印出每一张图片的网址:
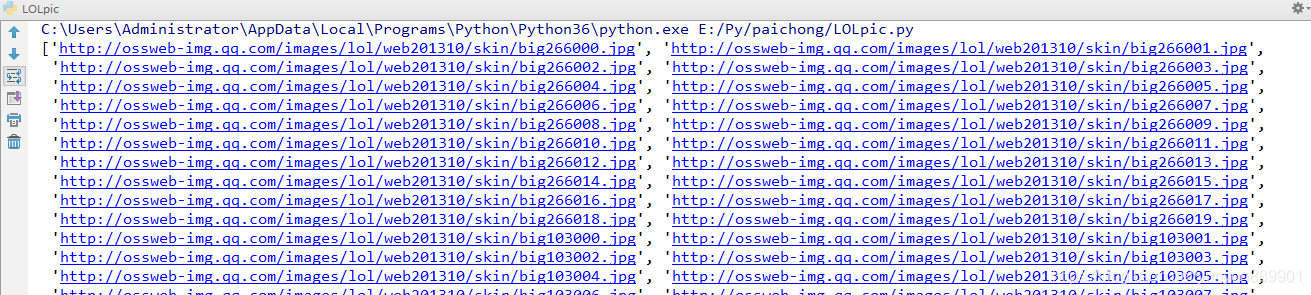
在文件夹中可以看到图片已经下载好
如图:

到此这篇关于教你用Python爬取英雄联盟皮肤原画的文章就介绍到这了,更多相关Python爬取皮肤内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
用Python爬取LOL所有的英雄信息以及英雄皮肤的示例代码
实现思路:分为两部分,第一部分,获取网页上数据并使用xlwt生成excel(当然你也可以选择保存到数据库),第二部分获取网页数据使用IO流将图片保存到本地 一.爬取所有英雄属性并生成excel 1.代码 import json import requests import xlwt # 设置头部信息,防止被检测出是爬虫 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (
-

python结合多线程爬取英雄联盟皮肤(原理分析)
1.什么是多线程? 多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率.线程是在同一时间需要完成多项任务的时候实现的. 为什么要使用多线程 线程在程序中是独立的.并发的执行流.与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存.文件句柄和其他进程应有的状态. 因为线程的划分尺度小于进程,使得多线程程序的并发性高.进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率. 线程比进程具有更高的性能,这是由于同一个进程
-
python 爬取英雄联盟皮肤图片
一开始都是先去<英雄联盟>官网找到英雄及皮肤图片的网址: URL = r'https://lol.qq.com/data/info-heros.shtml' 从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号(如下图). 但是只有英雄的名字(英文)以及对应的编号并不能找到
-
python 爬取英雄联盟皮肤并下载的示例
爬取结果: 爬取代码 import os import json import requests from tqdm import tqdm def lol_spider(): # 存放英雄信息 heros = [] # 存放英雄皮肤 hero_skins = [] # 获取所有英雄信息 url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js' hero_text = requests.get(url).t
-
Python3爬取英雄联盟英雄皮肤大图实例代码
爬虫思路 初步尝试 我先查看了network,并没有发现有可用的API:然后又用bs4去分析英雄列表页,但是请求到html里面,并没有英雄列表,在英雄列表的节点上,只有"正在加载中"这样的字样:同样的方法,分析英雄详情也是这种情况,所以我猜测,这些数据应该是Javascript负责加载的. 继续尝试 然后我就查看了 英雄列表的源代码 ,查看外部引入的js文件,以及行内的js脚本,大概在368行,发现了有处理英雄列表的js注释,然后继续往下读这些代码,发现了第一个彩蛋,也就是他引入了一个
-
python爬取王者荣耀全皮肤的简单实现代码
相信现在很多人都喜欢玩王者荣耀这款手游,里面好看的皮肤令人爱不释手.那么你有没有想过把王者荣耀高清皮肤设置为壁纸,像下面这样 今天就来教大家如何利用python16行代码,实现王者荣耀全部高清皮肤的下载. 具体的操作分为两步: 1. 找到皮肤图片的地址 2. 下载图片 1. 寻找皮肤图片的地址 1. 找到英雄列表 百度"王者荣耀"进入官网 https://pvp.qq.com/.这里以Goole Chrome浏览器为例,在更多工具中选择开发者工具,或直接按F12进入调试界面,然后按F5
-
教你用Python爬取英雄联盟皮肤原画
一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: http://lol.qq.com/data/info-heros.shtml 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号. 3.但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
用Python爬取英雄联盟的皮肤详细示例
目录 一.推理原理 二.推理代码 第一步:获取js字典 第二步:从 js字典中提取到key值生成url列表 第三步:从 js字典中提取到value值生成name列表 第四步:下载并保存数据 第五步:执行主程序 一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: lol.qq.com 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中. 这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.j
-
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能.分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.com/snowyme/loldesk 开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了 首先,创建项目 scrapy startproject loldesk 生成项目的目录结构 首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接 import scrapy
-
教你如何用python爬取王者荣耀月收入流水线
前言 王者荣耀是最近几年包括现在一直都是最热销的手游,收益主要来源是游戏里面人物皮肤.今天就来爬取展示王者荣耀近一年收入流水线动图,看看王者荣耀有多赚钱(哈哈哈哈) 主要可视化内容: 一.App收入排行流水线 1.1.获取数据 数据来源于:七麦数据,里面数据都是通过异步加载,因此只需要找到异步链接,修改参数就可以直接获取到数据. 备注:需要cookie才可以获取数据. 请求链接 https://api.qimai.cn/pred/appMonthPred?analysis=eEcbRhNVVB9