PostgreSQL三种自增列sequence,serial,identity的用法区别
这三个对象都可以实现自增,这里从如下几个维度来看看这几个对象有哪些不同,其中功能性上看,大部分特性都是一致的或者类似的。
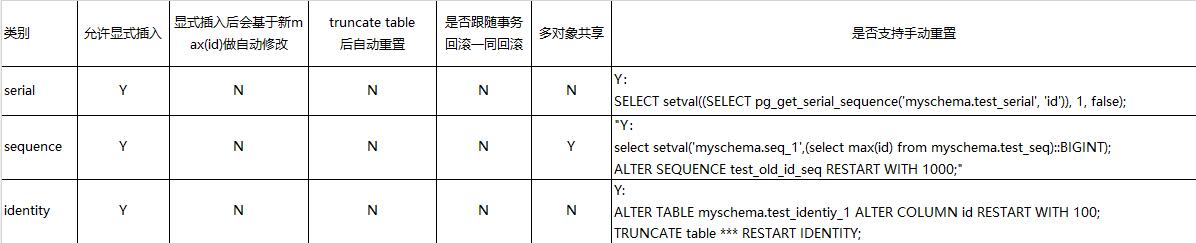
1、sequence在所有数据库中的性质都一样,它是跟具体的字段不是强绑定的,其特点是支持多个对个对象之间共享。
sequence作为自增字段值的时候,对表的写入需要另外单独授权sequence(GRANT USAGE ON SEQUENCE test_old_id_seq;)
sequence类型的字段表,在使用CREATE TABLE new_table LIKE old_table的时候,新表的自增字段会已久指向原始表的sequence
结论:
对于自增字段,无特殊需求的情况下,sequence不适合作为“自增列”,作为最最次选。
2、identity本质是为了兼容标准sql中的语法而新加的,修复了一些serial的缺陷,比如无法通过alter table的方式实现增加或者删除serial字段
2.1 identity定义成generated by default as identity也允许显式插入,
2.2 identity定义成always as identity,加上overriding system value也可以显式不插入
结论:
identity是serial的“增强版”,更适合作为“自增列”使用。
3、sequence,serial,identity共同的缺点是在显式插入之后,无法将自增值更新为表中的最大Id,这一点再显式插入的情况下是潜在自增字段Id冲突的
结论:
自增列在显式插入之后,一定要手动重置为表的最大Id。
4、自增字段的update没有细看,相对来说自增列的显式插入是一种常规操作,那些对自增列的update操作,只要脑子没问题,一般是不会这么干的。
原始手稿,懒得整理了,不涉及原理性的东西,动手试一遍就明白了。
---------------------------------------------------------sequence-------------------------------------------------------------
create sequence myschema.seq_1 INCREMENT BY 1 MINVALUE 1 START WITH 1;
create table myschema.test_seq
(
id int not null default nextval('myschema.seq_1') primary key,
name varchar(10)
);
隐式插入
insert into myschema.test_seq (name) values ('aaa');
insert into myschema.test_seq (name) values ('bbb');
insert into myschema.test_seq (name) values ('ccc');
select * from myschema.test_seq;
显式插入
insert into myschema.test_seq (id,name) values (5,'ddd');
select * from test_seq;
再次隐式插入
--可以正常插入
insert into myschema.test_seq (name) values ('eee');
--插入失败,主键重复,因为序列自身是递增的,不会关心表中被显式插入的数据
insert into myschema.test_seq (name) values ('fff');
--重置序列的最大值
select setval('myschema.seq_1',(select max(id) from myschema.test_seq)::BIGINT);
--事务回滚后,序列号并不会回滚
begin;
insert into myschema.test_seq (name) values ('ggg');
rollback;
-- truncate 表之后,序列不受影响
truncate table myschema.test_seq;
--重置序列
ALTER SEQUENCE myschema.seq_1 RESTART WITH 1;
---------------------------------------------------------serial-------------------------------------------------------------
create table myschema.test_serial
(
id serial primary key,
name varchar(100)
)
select * from test_serial;
insert into myschema.test_serial(name) values ('aaa');
insert into myschema.test_serial(name) values ('bbb');
insert into myschema.test_serial(name) values ('ccc');
select * from myschema.test_serial;
--显式插入,可以执行
insert into myschema.test_serial(id,name) values (5,'ccc');
--再次隐式插入,第二次会报错,因为隐式插入的话,serial会基于显式插入之前的Id做自增,serial无法意识到当前已经存在的最大值
insert into myschema.test_serial(name) values ('xxx');
insert into myschema.test_serial(name) values ('yyy');
select * from myschema.test_serial;
--truncate table 后serial不会重置
truncate table myschema.test_serial;
insert into myschema.test_serial(name) values ('aaa');
insert into myschema.test_serial(name) values ('bbb');
insert into myschema.test_serial(name) values ('ccc');
select * from myschema.test_serial;
--验证是否会随着事务一起回滚,结论:不会
begin;
insert into myschema.test_serial(name) values ('yyy');
rollback;
--重置serial,需要注意的是重置的Id必须要大于相关表的字段最大Id,否则会产生重号
SELECT SETVAL((SELECT pg_get_serial_sequence('myschema.test_serial', 'id')), 1, false);
---------------------------------------------------------identity-------------------------------------------------------------
drop table myschema.test_identiy_1
create table myschema.test_identiy_1
(
id int generated always as identity (cache 100 START WITH 1 INCREMENT BY 1) primary key ,
name varchar(100)
);
create table myschema.test_identiy_2
(
id int generated by default as identity (cache 100 START WITH 1 INCREMENT BY 1) primary key ,
name varchar(100)
);
insert into myschema.test_identiy_1(name) values ('aaa');
insert into myschema.test_identiy_1(name) values ('bbb');
insert into myschema.test_identiy_1(name) values ('ccc');
insert into myschema.test_identiy_2(name) values ('aaa');
insert into myschema.test_identiy_2(name) values ('bbb');
insert into myschema.test_identiy_2(name) values ('ccc');
select * from myschema.test_identiy_1;
--显式插入值,如果定义为generated always as identity则不允许显式插入,除非增加overriding system value 提示
--一旦提示了overriding system value,可以
insert into myschema.test_identiy_1(id,name) values (5,'ccc');
insert into myschema.test_identiy_1(id,name)overriding system value values (5,'ccc');
select * from myschema.test_identiy_2;
--显式插入值,如果定义为generated by default as identity则允许显式插入,
insert into myschema.test_identiy_2(id,name) values (5,'ccc');
--显式插入后,继续隐式插入,第二次插入会报错,identity已久是不识别表中显式插入后的最大值
insert into myschema.test_identiy_2(name) values ('xxx');
insert into myschema.test_identiy_2(name) values ('yyy');
select * from myschema.test_identiy_2;
总之个identity很扯淡,你定义成always as identity,加上overriding system value可以显式不插入
定义成generated by default as identity也允许显式插入
不管怎么样,既然都允许显式插入,那扯什么淡的来个overriding system value
--truncate后再次插入,自增列不会重置
truncate table myschema.test_identiy_1;
select * from myschema.test_identiy_1;
begin;
insert into myschema.test_identiy_1(name) values ('xxx');
rollback;
--truncate并且RESTART IDENTITY后,会重置自增列
TRUNCATE table myschema.test_identiy_1 RESTART IDENTITY;
select * from myschema.test_identiy_1
--identity自增列的重置表或者更改
ALTER TABLE myschema.test_identiy_1 ALTER COLUMN id RESTART WITH 100;
实际中更改identity自增长列的当前起始值(已有的最大值+1):

补充:PostgreSQL不同的表使用不同的自增序列
hibernate 配置文件里面应该是这样的:
<id name="id"> <generator class="sequence"> <param name="sequence">adminuser</param> </generator> </id>
使用xdoclet时 类里面的配置应该是这样的:
/** * @hibernate.id generator-class="sequence" * @hibernate.generator-param name="sequence" value="adminuser" */ private int id;
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
在PostgreSQL中设置表中某列值自增或循环方式
在postgresql中,设置已存在的某列(num)值自增,可以用以下方法: //将表tb按name排序,利用row_number() over()查询序号并将该列命名为rownum,创建新表tb1并将结果保存到该表中 create table tb1 as (select *, row_number() over(order by name) as rownum from tb); //根据两张表共同的字段name,将tb1中rownum对应值更新到tb中num中 update tb set
-
postgresql修改自增序列操作
在 mysql 中,实现 id 自增的方式是依靠加一个 auto_increment 标志,而在 pgsql 中,id 自增是通过序列 SEQUENCE. 创建表时设置自增序列为: CREATE TABLE "config" ( "id" int4 NOT NULL DEFAULT nextval('config_id_seq'::regclass), ... }; 如果需要修改创建表之后的序列,如: ----删除前先解除 id 对该序列的依赖 ALTER TABL
-

postgresql 导入数据库表并重设自增属性的操作
postgresql使用Navicat软件导出数据库表,在导入会数据库的操作. postgresql 的自增字段 是通过 序列 sequence来实现的. 1.先删除导出的数据库表中的自增属性 2.导入数据库表之后,需要创建序列. 注:一般序列名称由数据表名+主键字段+seq组成 (通常情况下主键字段即为自增字段),如下表名为cof_table_hot_analysis,主键字段为 id CREATE SEQUENCE cof_table_hot_analysis_id_seq START WI
-
PostgreSQL 自增语法的用法说明
mysql使用auto_increment的语法实现表字段自增. 在PostgreSQL中,具有数据类型为smallserial,serial,bigserial的字段具有自增特性. create table company( id serial primary key, name text not null, age int not null, address char(50), salary real ); 则在插入该表的时候,可以不插入id列,数据库系统会自动填充. insert into
-
解决postgresql 自增id作为key重复的问题
啥也不说啦,看代码吧~ SELECT setval('data_tracking_au_sec_id_seq', (SELECT MAX(id) FROM data_tracking_au_sec)+1); data_tracking_au_sec_id_seq:可以再DDL查看到 data_tracking_au_sec:表名 补充:[Postgresql]-主键自增,插入数据时提示违背主键唯一性 错误备忘录: 1.主键自增,插入数据时提示违背主键唯一性 报错原因是自增主键的序列值与当前主键的
-
PostgreSQL三种自增列sequence,serial,identity的用法区别
这三个对象都可以实现自增,这里从如下几个维度来看看这几个对象有哪些不同,其中功能性上看,大部分特性都是一致的或者类似的. 1.sequence在所有数据库中的性质都一样,它是跟具体的字段不是强绑定的,其特点是支持多个对个对象之间共享. sequence作为自增字段值的时候,对表的写入需要另外单独授权sequence(GRANT USAGE ON SEQUENCE test_old_id_seq;) sequence类型的字段表,在使用CREATE TABLE new_table LIKE old
-
详解webpack引用jquery(第三方模块)的三种办法
前言 在使用webpack作为构建工具,开发 vue项目的时候,难免会用到 jquery这种第三方插件(毕竟都是从用jquery过来的),那么怎么引用呢?接下来我来说三种方法. 1 html 模板文件引用法,这种方法最直接也是我们最熟悉,直接在项目中的网页模板文件中加入jquery的引用即可 a.引用 b.使用 2 expose-loader 引用法 a. 安装jquery npm i jquery -D b. main.js中引用 jquery import Vue from 'vue' im
-
Oracle中使用触发器(trigger)和序列(sequence)模拟实现自增列实例
问题:在SQL Server数据库中,有自增列这个字段属性,使用起来也是很方便的.而在Oracle中却没有这个功能,该如何实现呢? 答:在Oracle中虽然没有自增列的说法,但却可以通过触发器(trigger)和序列(sequence)来模式实现. 示例: 1.建立表 复制代码 代码如下: create table user ( id number(6) not null, name varchar2(30) not null primary key )
-
SQL 将一列拆分成多列的三种方法
数据表中有一列数据,如图所示: 现在需要将该列数据分成三列. SQL 代码如下所示: 第一种 select max(case when F1%3=1 then F1 else 0 end) a, max(case when F1%3=2 then F1 else 0 end) b, max(case when F1%3=0 then F1 else 0 end) c from HLR151 group by (F1-1)/3 效果 第二种 select c1=a.F1,c2=b.F1,c3=c.
-
浅谈PostgreSQL表分区的三种方式
目录 一.简介 二.三种方式 2.1.Range范围分区 2.2.List列表分区 2.3.Hash哈希分区 三.总结 一.简介 表分区是解决一些因单表过大引用的性能问题的方式,比如某张表过大就会造成查询变慢,可能分区是一种解决方案.一般建议当单表大小超过内存就可以考虑表分区了.PostgreSQL的表分区有三种方式: Range:范围分区: List:列表分区: Hash:哈希分区. 本文通过示例讲解如何进行这三种方式的分区. 二.三种方式 为方便,我们通过Docker的方式启动一个Postg
-
SqlServer Mysql数据库修改自增列的值及相应问题的解决方案
SQL Server 平台修改自增列值 由于之前处理过sql server数据库的迁移工作,尝试过其自增列值的变更,但是通过SQL 语句修改自增列值,是严格不允许的,直接报错(无法更新标识列 '自增列名称').sql server我测试是2008.2012和2014,都不允许变更自增列值,我相信SQL Server 2005+的环境均不允许变更字段列值. 如果非要在SQL Server 平台修改自增列值的,那就手动需要自增列属性,然后修改该列值,修改成功后再手动添加自增列属性.如果在生成环境修改
-
浅谈Java生成唯一标识码的三种方式
目录 前言 正文 UUID实现唯一标识码 SnowFlake实现唯一标识码 通过时间工具生成带有业务标示的唯一标识码 前言 我们经常会遇到这样的场景,需要生成一个唯一的序列号来表明某一个数据的唯一性,在单节点的应用中我们可以简单地使用一个自增的整型来实现实现,但是在分布式情况下这个方式却存在冲突的可能性,那么有什么办法我们可以生成一个唯一的序列号呢,并且如果想使得这个序列号也能展示一些业务信息呢? 正文 UUID实现唯一标识码 UUID 的目的是让分布式系统中的所有元素,都能有唯一的辨识资讯,而
-
sql跨表查询的三种方案总结
目录 前言 方案一:连接多个库,同步执行查询 优点 缺点 代码执行 方案二:在主数据库增加冗余表,通过定时更新,造成同库联表查询 优点 缺点 相似实现场景 方案三:dbLink本地连接多个库,在本地进行数据分析 优点 缺点 前言 最近又个朋友问我,如何进行sql的跨库关联查询? 首先呢,我们知道mysql是不支持跨库连接的,但是老话说得好,只要思想不滑坡,思想总比困难多! PS: 问题摆在这里了,还能不解决是怎么的? 经过一番思考我给他提出了三个方案,虽然都不尽善尽美,但各领风骚! 连接方案,以
-
MySQL中创建表的三种方法汇总
目录 CREATE TABLE CREATE TABLE … LIKE CREATE TABLE … SELECT 总结 SQL 标准使用 CREATE TABLE 语句创建数据表:MySQL 则实现了三种创建表的方法,支持自定义表结构或者通过复制已有的表结构来创建新表,本文给大家分别介绍一下这些方法的使用和注意事项. CREATE TABLE CREATE TABLE 语句的基本语法如下: CREATE TABLE [IF NOT EXISTS] table_name ( column1 da
-
SQL Server 2008怎样添加自增列实现自增序号
在做<机房收费系统>的时候,有的表需要添加自增列,在添加新纪录时自动添加一个序号.下面我给大家介绍两种添加方法: 一.通过T-SQL代码. 复制代码 代码如下: alter table 表名 add 列名 int IDENTITY(1,1) NOT NULL 这里用到了identity关键字:indentity(a,b),a b均为正整数,a表示开始数,b表示步长,indentity(1,1)就代表从1开始,每次增加1 二.通过企业管理器 打开对象资源管理器,新建表,如下图 插入列,设置列属