tensorflow2.0实现复杂神经网络(多输入多输出nn,Resnet)
常见的‘融合'操作
复杂神经网络模型的实现离不开"融合"操作。常见融合操作如下:
(1)求和,求差
# 求和 layers.Add(inputs) # 求差 layers.Subtract(inputs)
inputs: 一个输入张量的列表(列表大小至少为 2),列表的shape必须一样才能进行求和(求差)操作。
例子:
input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='relu')(input1) input2 = keras.layers.Input(shape=(32,)) x2 = keras.layers.Dense(8, activation='relu')(input2) added = keras.layers.add([x1, x2]) out = keras.layers.Dense(4)(added) model = keras.models.Model(inputs=[input1, input2], outputs=out)
(2)乘法
# 输入张量的逐元素乘积(对应位置元素相乘,输入维度必须相同) layers.multiply(inputs) # 输入张量样本之间的点积 layers.dot(inputs, axes, normalize=False)
dot即矩阵乘法,例子1:
x = np.arange(10).reshape(1, 5, 2) y = np.arange(10, 20).reshape(1, 2, 5) # 三维的输入做dot通常像这样指定axes,表示矩阵的第一维度和第二维度参与矩阵乘法,第0维度是batchsize tf.keras.layers.Dot(axes=(1, 2))([x, y]) # 输出如下: <tf.Tensor: shape=(1, 2, 2), dtype=int64, numpy= array([[[260, 360], [320, 445]]])>
例子2:
x1 = tf.keras.layers.Dense(8)(np.arange(10).reshape(5, 2)) x2 = tf.keras.layers.Dense(8)(np.arange(10, 20).reshape(5, 2)) dotted = tf.keras.layers.Dot(axes=1)([x1, x2]) dotted.shape TensorShape([5, 1])
(3)联合:
# 所有输入张量通过 axis 轴串联起来的输出张量。 layers.add(inputs,axis=-1)
- inputs: 一个列表的输入张量(列表大小至少为 2)。
- axis: 串联的轴。
例子:
x1 = tf.keras.layers.Dense(8)(np.arange(10).reshape(5, 2)) x2 = tf.keras.layers.Dense(8)(np.arange(10, 20).reshape(5, 2)) concatted = tf.keras.layers.Concatenate()([x1, x2]) concatted.shape TensorShape([5, 16])
(4)统计操作
求均值layers.Average()
input1 = tf.keras.layers.Input(shape=(16,)) x1 = tf.keras.layers.Dense(8, activation='relu')(input1) input2 = tf.keras.layers.Input(shape=(32,)) x2 = tf.keras.layers.Dense(8, activation='relu')(input2) avg = tf.keras.layers.Average()([x1, x2]) # x_1 x_2 的均值作为输出 print(avg) # <tf.Tensor 'average/Identity:0' shape=(None, 8) dtype=float32> out = tf.keras.layers.Dense(4)(avg) model = tf.keras.models.Model(inputs=[input1, input2], outputs=out)
layers.Maximum()用法相同。
具有多个输入和输出的模型
假设要构造这样一个模型:
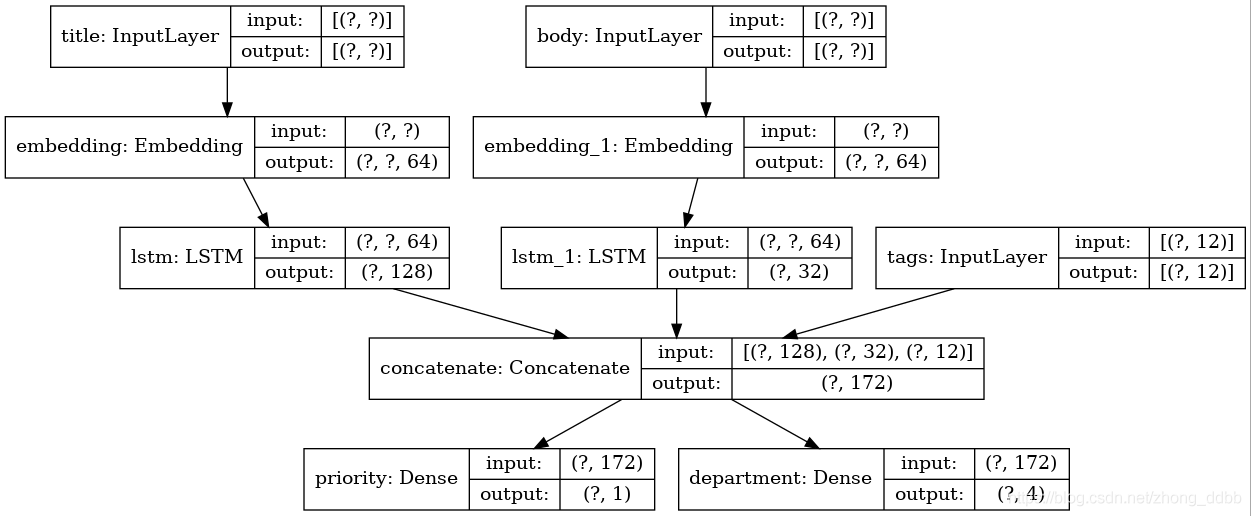
(1)模型具有以下三个输入
工单标题(文本输入),工单的文本正文(文本输入),以及用户添加的任何标签(分类输入)
(2)模型将具有两个输出:
- 介于 0 和 1 之间的优先级分数(标量 Sigmoid 输出)
- 应该处理工单的部门(部门范围内的 Softmax 输出)。
模型大概长这样:
接下来开始创建这个模型。
(1)模型的输入
num_tags = 12 num_words = 10000 num_departments = 4 title_input = keras.Input(shape=(None,), name="title") # Variable-length sequence of ints body_input = keras.Input(shape=(None,), name="body") # Variable-length sequence of ints tags_input = keras.Input(shape=(num_tags,), name="tags") # Binary vectors of size `num_tags`
(2)将输入的每一个词进行嵌入成64-dimensional vector
title_features = layers.Embedding(num_words,64)(title_input) body_features = layers.Embedding(num_words,64)(body_input)
(3)处理结果输入LSTM模型,得到 128-dimensional vector
title_features = layers.LSTM(128)(title_features) body_features = layers.LSTM(32)(body_features)
(4)concatenate融合所有的特征
x = layers.concatenate([title_features, body_features, tags_input])
(5)模型的输出
# 输出1,回归问题 priority_pred = layers.Dense(1,name="priority")(x) # 输出2,分类问题 department_pred = layers.Dense(num_departments,name="department")(x)
(6)定义模型
model = keras.Model( inputs=[title_input, body_input, tags_input], outputs=[priority_pred, department_pred], )
(7)模型编译
编译此模型时,可以为每个输出分配不同的损失。甚至可以为每个损失分配不同的权重,以调整其对总训练损失的贡献。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"priority": keras.losses.BinaryCrossentropy(from_logits=True),
"department": keras.losses.CategoricalCrossentropy(from_logits=True),
},
loss_weights=[1.0, 0.2],
)
(8)模型的训练
# Dummy input data
title_data = np.random.randint(num_words, size=(1280, 10))
body_data = np.random.randint(num_words, size=(1280, 100))
tags_data = np.random.randint(2, size=(1280, num_tags)).astype("float32")
# Dummy target data
priority_targets = np.random.random(size=(1280, 1))
dept_targets = np.random.randint(2, size=(1280, num_departments))
# 通过字典的形式将数据fit到模型
model.fit(
{"title": title_data, "body": body_data, "tags": tags_data},
{"priority": priority_targets, "department": dept_targets},
epochs=2,
batch_size=32,
)
ResNet 模型
通过add来实现融合操作,模型的基本结构如下:
# 实现第一个块 _input = keras.Input(shape=(32,32,3)) x = layers.Conv2D(32,3,activation='relu')(_input) x = layers.Conv2D(64,3,activation='relu')(x) block1_output = layers.MaxPooling2D(3)(x) # 实现第二个块 x = layers.Conv2D(64,3,padding='same',activation='relu')(block1_output) x = layers.Conv2D(64,3,padding='same',activation='relu')(x) block2_output = layers.add([x,block1_output]) # 实现第三个块 x = layers.Conv2D(64, 3, activation="relu", padding="same")(block2_output) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) block_3_output = layers.add([x, block2_output]) # 进入全连接层 x = layers.Conv2D(64,3,activation='relu')(block_3_output) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(10)(x)
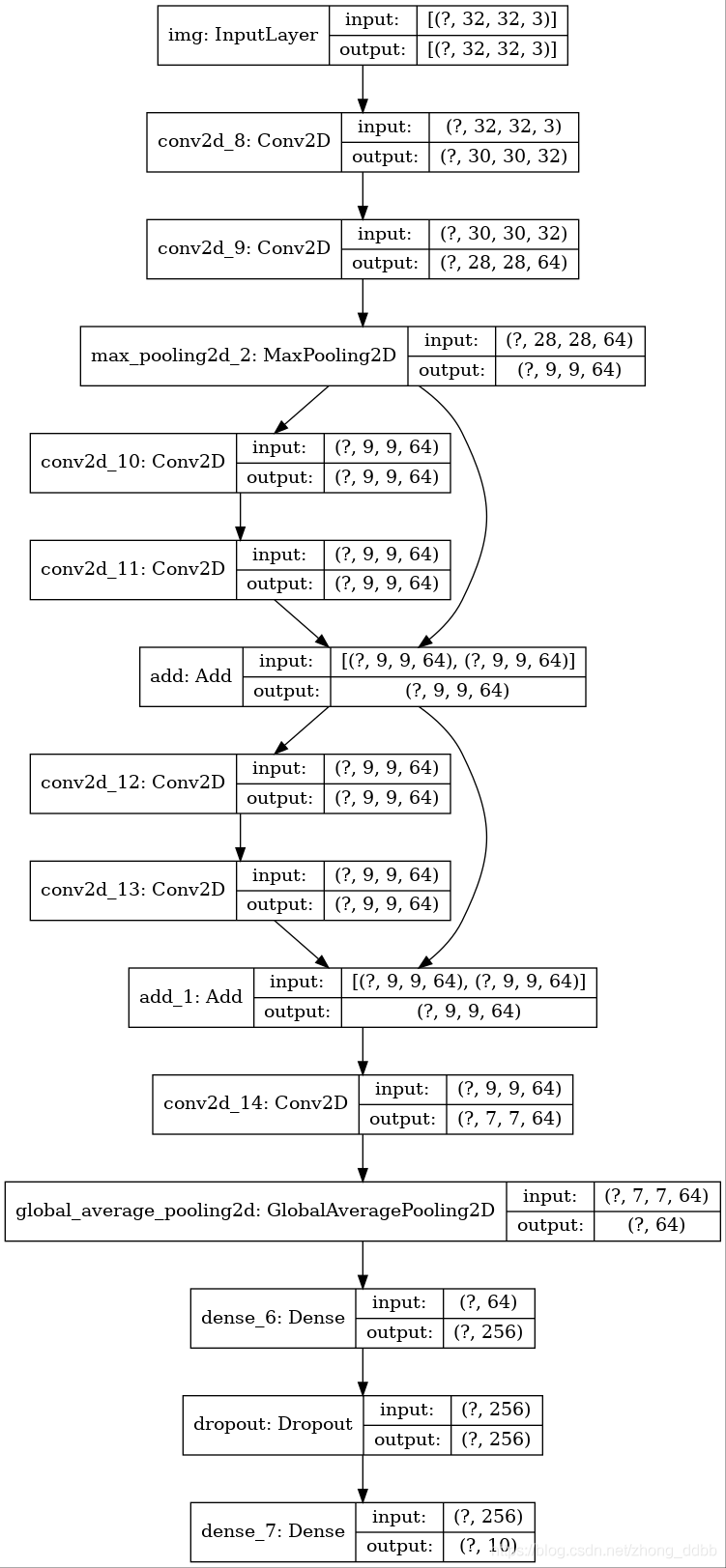
模型的定义与编译:
model = keras.Model(_input,outputs,name='resnet') model.compile( optimizer=keras.optimizers.RMSprop(1e-3), loss='sparse_categorical_crossentropy', metrics=["acc"], )
模型的训练
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 归一化
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
model.fit(tf.expand_dims(x_train,-1), y_train, batch_size=64, epochs=1, validation_split=0.2)
注:当loss = =keras.losses.CategoricalCrossentropy(from_logits=True)时,需对标签进行one-hot:
y_train = keras.utils.to_categorical(y_train, 10)
到此这篇关于tensorflow2.0实现复杂神经网络(多输入多输出nn,Resnet)的文章就介绍到这了,更多相关tensorflow2.0复杂神经网络内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
TensorFlow平台下Python实现神经网络
本篇文章主要通过一个简单的例子来实现神经网络.训练数据是随机产生的模拟数据集,解决二分类问题. 下面我们首先说一下,训练神经网络的一般过程: 1.定义神经网络的结构和前向传播的输出结果 2.定义损失函数以及反向传播优化的算法 3.生成会话(Session)并且在训练数据上反复运行反向传播优化算法 要记住的一点是,无论神经网络的结构如何变化,以上三个步骤是不会改变的. 完整代码如下: import tensorflow as tf #导入TensorFlow工具包并简称为tf from numpy
-
TensorFlow keras卷积神经网络 添加L2正则化方式
我就废话不多说了,大家还是直接看代码吧! model = keras.models.Sequential([ #卷积层1 keras.layers.Conv2D(32,kernel_size=5,strides=1,padding="same",data_format="channels_last",activation=tf.nn.relu,kernel_regularizer=keras.regularizers.l2(0.01)), #池化层1 keras.l
-
tensorflow入门之训练简单的神经网络方法
这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入.也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数. 2.定义神经网络的结构,并定义如何从神经网络的输入得到输出.也就是说定义输入层,隐藏层以及输出层. 3.通过训练数据来调整神经网络中的参数取值,这是训练神经网络的过程.一般来说要定义模型的损失函数,以及参数优化的方法,如交叉熵损失函数和梯度下降法调优等. 4.利用训练好的模型预测
-
tensorflow构建BP神经网络的方法
之前的一篇博客专门介绍了神经网络的搭建,是在python环境下基于numpy搭建的,之前的numpy版两层神经网络,不能支持增加神经网络的层数.最近看了一个介绍tensorflow的视频,介绍了关于tensorflow的构建神经网络的方法,特此记录. tensorflow的构建封装的更加完善,可以任意加入中间层,只要注意好维度即可,不过numpy版的神经网络代码经过适当地改动也可以做到这一点,这里最重要的思想就是层的模型的分离. import tensorflow as tf import nu
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-

tensorflow建立一个简单的神经网络的方法
本笔记目的是通过tensorflow实现一个两层的神经网络.目的是实现一个二次函数的拟合. 如何添加一层网络 代码如下: def add_layer(inputs, in_size, out_size, activation_function=None): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) bia
-
TensorFlow 实战之实现卷积神经网络的实例讲解
本文根据最近学习TensorFlow书籍网络文章的情况,特将一些学习心得做了总结,详情如下.如有不当之处,请各位大拿多多指点,在此谢过. 一.相关性概念 1.卷积神经网络(ConvolutionNeural Network,CNN) 19世纪60年代科学家最早提出感受野(ReceptiveField).当时通过对猫视觉皮层细胞研究,科学家发现每一个视觉神经元只会处理一小块区域的视觉图像,即感受野.20世纪80年代,日本科学家提出神经认知机(Neocognitron)的概念,被视为卷积神经网络最初
-
Tensorflow实现卷积神经网络用于人脸关键点识别
今年来人工智能的概念越来越火,AlphaGo以4:1击败李世石更是起到推波助澜的作用.作为一个开挖掘机的菜鸟,深深感到不学习一下deep learning早晚要被淘汰. 既然要开始学,当然是搭一个深度神经网络跑几个数据集感受一下作为入门最直观了.自己写代码实现的话debug的过程和运行效率都会很忧伤,我也不知道怎么调用GPU- 所以还是站在巨人的肩膀上,用现成的框架吧.粗略了解一下,现在比较知名的有caffe.mxnet.tensorflow等等.选哪个呢?对我来说选择的标准就两个,第一要容易安
-
TensorFlow神经网络优化策略学习
在神经网络模型优化的过程中,会遇到许多问题,比如如何设置学习率的问题,我们可通过指数衰减的方式让模型在训练初期快速接近较优解,在训练后期稳定进入最优解区域:针对过拟合问题,通过正则化的方法加以应对:滑动平均模型可以让最终得到的模型在未知数据上表现的更加健壮. 一.学习率的设置 学习率设置既不能过大,也不能过小.TensorFlow提供了一种更加灵活的学习率设置方法--指数衰减法.该方法实现了指数衰减学习率,先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训
-
tensorflow学习笔记之简单的神经网络训练和测试
本文实例为大家分享了用简单的神经网络来训练和测试的具体代码,供大家参考,具体内容如下 刚开始学习tf时,我们从简单的地方开始.卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始. 神经网络没有卷积功能,只有简单的三层:输入层,隐藏层和输出层. 数据从输入层输入,在隐藏层进行加权变换,最后在输出层进行输出.输出的时候,我们可以使用softmax回归,输出属于每个类别的概率值.借用极客学院的图表示如下: 其中,x1,x2,x3为输入数据,经过运算后,