关于Python下的Matlab函数对应关系(Numpy)
目录
- Matlab函数对应关系(Numpy)
- Numpy与Matlab互转操作
- 1、常用操作(参考numpy官方说明)
- 2、线性变换(参考numpy官方说明)
Matlab函数对应关系(Numpy)
首先给出官网链接,其中详细说明了在Python下如何用Numpy实现Matlab下相同的函数功能。
博主在用Python撰写代码的时候,想用Python实现在Matlab下某个函数的功能(比如Repmat函数),但是当使用语句
from numpy.matlib import repmat A = repmat(B, 1, 2)
调用工具包时,虽然可以正常实现功能,但是PyCharm下报出警告:
Importing from numpy.matlib is deprecated since 1.19.0. The matrix subclass is not the recommended way to represent matrices or deal with linear algebra (see https://docs.scipy.org/doc/numpy/user/numpy-for-matlab-users.html). Please adjust your code to use regular ndarray.
随后,通过查阅资料,发现是因为从1.19.0版本后,numpy就不再推荐使用numpy.matlib来实现对应功能了。
因此,大家可以对照官网上的说明来实现替换。
这里截取一小部分:
其他的可以从官网上面找到。
Numpy与Matlab互转操作
在日常使用中,matlab作为我们机器学习以及深度学习的模型训练使用的工具,而线上使用python实现模型落地。因为不可避免常遇到matlab与numpy之间有些操作需要相互转换。
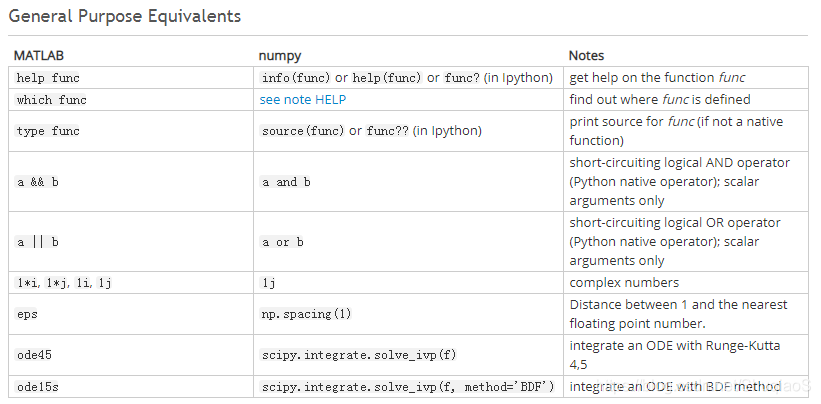
1、常用操作(参考numpy官方说明)
| MATLAB | numpy | 说明 |
| helpfunc | info(func) or help(func) orfunc? (in Ipython) | 获得函数的帮助 |
| whichfunc | see note HELP | 查找函数的定义 |
| typefunc | source(func) or func?? (inIpython) | 查看函数源码 |
| a && b | a and b | 逻辑运算与操作 |
| a || b | a or b | 逻辑运算或操作 |
| 1*i, 1*j,1i, 1j | 1j | 复数 |
| eps | np.spacing(1) | 1与最小浮点数的距离 |
| ode45 | scipy.integrate.solve_ivp(f) | 求解同阶微分方程-Kutta 4,5 |
| ode15s | scipy.integrate.solve_ivp(f, method='BDF') | 求解变阶微分方程 |
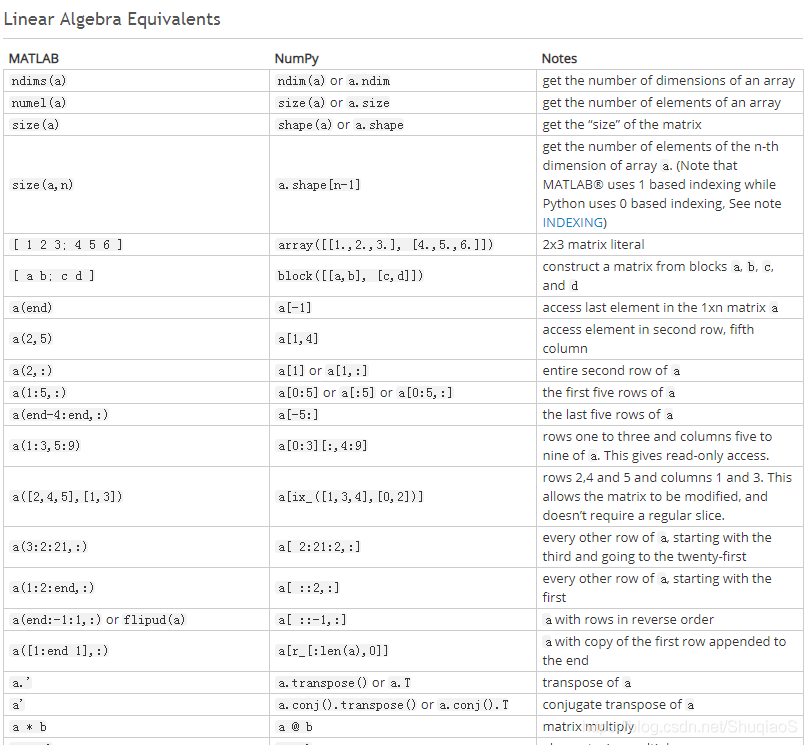
2、线性变换(参考numpy官方说明)
| MATLAB | NumPy |
| ndims(a) | ndim(a) or a.ndim |
| numel(a) | size(a) or a.size |
| size(a) | shape(a) or a.shape |
| size(a,n) | a.shape[n-1] |
| [ 1 2 3; 4 5 6 ] | array([[1.,2.,3.], [4.,5.,6.]]) |
| [ a b; c d ] | vstack([hstack([a,b]), hstack([c,d])]) or bmat('a b; c d') |
| a(end) | a[-1] |
| a(2,5) | a[1,4] |
| a(2,:) | a[1] or a[1,:] |
| a(1:5,:) | a[0:5] or a[:5] or a[0:5,:] |
| a(end-4:end,:) | a[-5:] |
| a(1:3,5:9) | a[0:3][:,4:9] |
| a([2,4,5],[1,3]) | a[ix_([1,3,4],[0,2])] |
| a(3:2:21,:) | a[ 2:21:2,:] |
| a(1:2:end,:) | a[ ::2,:] |
| a(end:-1:1,:) or flipud(a) | a[ ::-1,:] |
| a([1:end 1],:) | a[r_[:len(a),0]] |
| a.' | a.transpose() or a.T |
| a' | a.conj().transpose() or a.conj().T |
| a * b | a.dot(b) |
| a .* b | a * b |
| a./b | a/b |
| a.^3 | a**3 |
| (a>0.5) | (a>0.5) |
| find(a>0.5) | nonzero(a>0.5) |
| a(:,find(v>0.5)) | a[:,nonzero(v>0.5)[0]] |
| a(:,find(v>0.5)) | a[:,v.T>0.5] |
| a(a<0.5)=0 | a[a<0.5]=0 |
| a .* (a>0.5) | a * (a>0.5) |
| a(:) = 3 | a[:] = 3 |
| y=x | y = x.copy() |
| y=x(2,:) | y = x[1,:].copy() |
| y=x(:) | y = x.flatten() |
| 1:10 | arange(1.,11.) or r_[1.:11.] or r_[1:10:10j] |
| 0:9 | arange(10.) or r_[:10.] or r_[:9:10j] |
| [1:10]' | arange(1.,11.)[:, newaxis] |
| zeros(3,4) | zeros((3,4)) |
| zeros(3,4,5) | zeros((3,4,5)) |
| ones(3,4) | ones((3,4)) |
| eye(3) | eye(3) |
| diag(a) | diag(a) |
| diag(a,0) | diag(a,0) |
| rand(3,4) | random.rand(3,4) |
| linspace(1,3,4) | linspace(1,3,4) |
| [x,y]=meshgrid(0:8,0:5) | mgrid[0:9.,0:6.] or meshgrid(r_[0:9.],r_[0:6.] |
| ogrid[0:9.,0:6.] or ix_(r_[0:9.],r_[0:6.] | |
| [x,y]=meshgrid([1,2,4],[2,4,5]) | meshgrid([1,2,4],[2,4,5]) |
| ix_([1,2,4],[2,4,5]) | |
| repmat(a, m, n) | tile(a, (m, n)) |
| [a b] | concatenate((a,b),1) or hstack((a,b)) or column_stack((a,b)) |
| [a; b] | concatenate((a,b)) or vstack((a,b)) or r_[a,b] |
| max(max(a)) | a.max() |
| max(a) | a.max(0) |
| max(a,[],2) | a.max(1) |
| max(a,b) | maximum(a, b) |
| norm(v) | sqrt(dot(v,v)) or np.linalg.norm(v) |
| a & b | logical_and(a,b) |
| a | b | logical_or(a,b) |
| bitand(a,b) | a & b |
| bitor(a,b) | a | b |
| inv(a) | linalg.inv(a) |
| pinv(a) | linalg.pinv(a) |
| rank(a) | linalg.matrix_rank(a) |
| a\b | linalg.solve(a,b) if a is square; linalg.lstsq(a,b) otherwise |
| b/a | Solve a.T x.T = b.T instead |
| [U,S,V]=svd(a) | U, S, Vh = linalg.svd(a), V = Vh.T |
| chol(a) | linalg.cholesky(a).T |
| [V,D]=eig(a) | D,V = linalg.eig(a) |
| [V,D]=eig(a,b) | V,D = np.linalg.eig(a,b) |
| [V,D]=eigs(a,k) | |
| [Q,R,P]=qr(a,0) | Q,R = scipy.linalg.qr(a) |
| [L,U,P]=lu(a) | L,U = scipy.linalg.lu(a) or LU,P=scipy.linalg.lu_factor(a) |
| conjgrad | scipy.sparse.linalg.cg |
| fft(a) | fft(a) |
| ifft(a) | ifft(a) |
| sort(a) | sort(a) or a.sort() |
| [b,I] = sortrows(a,i) | I = argsort(a[:,i]), b=a[I,:] |
| regress(y,X) | linalg.lstsq(X,y) |
| decimate(x, q) | scipy.signal.resample(x, len(x)/q) |
| unique(a) | unique(a) |
| squeeze(a) | a.squeeze() |
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python&Matlab实现炫酷的3D旋转图
目录 前言 1.Python爬取美女照片 1.1 留恋忘返的网址 1.2 Python代码 1.3 结果 2.Python实现 2.1 条件准备 2.2 运行展示 2.3 Python实现 3.Matlab实现 3.1 运行展示 3.2 Matlab代码 前言 我们今天的任务很明确,我先系统梳理一下: 1.先用Python爬取一波漂亮的美女照片: 2.然后Python中炫酷的代码实现: 3.最后用matlab伺候,得到相同的结果. 1.Python爬取美女照片 1.1 留恋忘返的网址 站长素材-
-
python如何处理matlab的mat数据
目录 处理matlab的mat数据 处理matlab的*.mat格式数据及常见错误汇总 一.数据读取错误 二.数据类型错误 处理matlab的mat数据 python 和matlab是2个常用的实验室平台工具,在一些应用下,这2个不同平台下的数据会打交道,因此如何读取和保存显得尤为重要,这里需要用到python的第三方平台下的scipy模块. 先用下面这个命令检查是否下载好scipy import scipy 如果报错,用python install scipy 或者 conda install
-
Python&Matlab实现蚂蚁群算法求解最短路径问题的示例
目录 1知识点 1.1 蚁群算法步骤 1.2 蚁群算法程序 2蚂蚁算法求解最短路径问题——Python实现 2.1源码实现 2.2 ACA_TSP实现 3 蚂蚁算法求解最短路径问题——Matlab实现 3.1流程图 3.2代码实现 3.3结果 1 知识点 详细知识点见:智能优化算法—蚁群算法(Python实现) 我们这一节知识点只讲蚁群算法求解最短路径步骤及流程. 1.1 蚁群算法步骤 设蚂蚁的数量为m,地点的数量为n,地点i与地点j之间相距Dij,t时刻地点i与地点j连接的路径上的信息素浓度为
-
Python&Matlab实现伏羲八卦图的绘制
目录 1 与达尔文对话 2 与老子对话 2.1 Python实现 2.2 Matlab实现 1 与达尔文对话 140年前,1858年7月1日,达尔文在英伦岛发表了自己有关自然选择的杰出论文.他提出,生物的发展规律是物竞天择.经过物竞,自然界选择并存留最具生命优势的物种.这些物种愈竞愈强.直至人,已无所不能,成为统治世界的物种,这已是不争的事实.但在地球的漫长的演化史上,我们又看见,曾经统治地球的庞然大物恐龙消亡了.一-些科学家将其归之于小行星对地球的撞击.但就在我们这一代人眼前,兽中之王的老虎正
-
Python&Matlab实现樱花的绘制
目录 1.锦短情长 2. 一场樱花雨(Matlab) 3.樱花树(Python) 1.锦短情长 为什么选择这个标题,借鉴了一封情书里面的情长纸短,还吻你万千. 锦短情长 都只谓人走茶凉,怎感觉锦短情长? 一提起眼泪汪汪,是明月人心所向? 2. 一场樱花雨(Matlab) function pingba hold on,axis equal axis(0.5+[-10,50,0,50]) set(gca,'xtick',[],'ytick',[],'xcolor','w','ycolor','w'
-
Python&Matlab实现灰狼优化算法的示例代码
目录 1 灰狼优化算法基本思想 2 灰狼捕食猎物过程 2.1 社会等级分层 2.2 包围猎物 2.3 狩猎 2.4 攻击猎物 2.5 寻找猎物 3 实现步骤及程序框图 3.1 步骤 3.2 程序框图 4 Python代码实现 5 Matlab实现 1 灰狼优化算法基本思想 灰狼优化算法是一种群智能优化算法,它的独特之处在于一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进.在了解灰狼优化算法的特点之前,我们有必要了解灰狼群中的等级制度. 灰狼群一般分为4个等级:处于第一等级的灰狼用α表示,处于第
-
关于Python下的Matlab函数对应关系(Numpy)
目录 Matlab函数对应关系(Numpy) Numpy与Matlab互转操作 1.常用操作(参考numpy官方说明) 2.线性变换(参考numpy官方说明) Matlab函数对应关系(Numpy) 首先给出官网链接,其中详细说明了在Python下如何用Numpy实现Matlab下相同的函数功能. 博主在用Python撰写代码的时候,想用Python实现在Matlab下某个函数的功能(比如Repmat函数),但是当使用语句 from numpy.matlib import repmat A =
-
关于Python常用函数中NumPy的使用
目录 1. txt文件 2. CSV文件 3.成交量加权平均价格 = average()函数 4. 算数平均值函数 = mean()函数 5. 时间加权平均价格 6. 最大值和最小值 7. 统计分析 8. 股票收益率 1. txt文件 (1) 单位矩阵 即主对角线上的元素均为1,其余元素均为0的正方形矩阵. 在NumPy中可以用eye函数创建一个这样的二维数组,我们只需要给定一个参数,用于指定矩阵中1的元素个数. 例如,创建3×3的数组: import numpy as np I2 = np.e
-
解决python中os.listdir()函数读取文件夹下文件的乱序和排序问题
1. os.listdir()概述 os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表. 例如: dir ='F:/Home_01/img'#当前目录 filenames=os.listdir(dir)#filenames存储dir下的所有文件名. 注意:os.listdir()返回的文件名不一定是顺序的,也就是说结果是不固定的,如下图,则filenames[0]有可能为'22.jpg',而不是我们所希望的'11.jpg'. 解决办法: filenames=os.l
-
python下对hsv颜色空间进行量化操作
更新:优化了代码,理由numpy的ufunc函数功能替换了之前的双重for循环,测试图片大小为692*1024*3,优化前运行时间为6.9s,优化后为0.8s. 由于工作需要,需要计算颜色直方图来提取颜色特征,但若不将颜色空间进行量化,则直方图矢量维数过高,不便于使用.但是看了opencv API后并未发现提供了相关函数能够在计算颜色直方图的同时进行量化,因此这部分功能只能自己实现.下面分为两个部分进行介绍: 一.颜色空间量化表 由于RGB模型不够直观,不符合人类视觉习惯,因此在进行颜色特征提取
-
Python下opencv使用hough变换检测直线与圆
在数字图像中,往往存在着一些特殊形状的几何图形,像检测马路边一条直线,检测人眼的圆形等等,有时我们需要把这些特定图形检测出来,hough变换就是这样一种检测的工具. Hough变换的原理是将特定图形上的点变换到一组参数空间上,根据参数空间点的累计结果找到一个极大值对应的解,那么这个解就对应着要寻找的几何形状的参数(比如说直线,那么就会得到直线的斜率k与常熟b,圆就会得到圆心与半径等等). 关于hough变换,核心以及难点就是关于就是有原始空间到参数空间的变换上.以直线检测为例,假设有一条直线L,
-
对python中数据集划分函数StratifiedShuffleSplit的使用详解
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数 1.交叉验证(Cross-validation) 交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和.这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型. 下图所示 2.StratifiedShuffleSplit函数的使用 官方文档 用法: from sklearn.
-
在python下读取并展示raw格式的图片实例
raw文件可能有些人没有,因此,先用一张图片创建一个raw格式的文件(其实可以是其他类型的格式文件) import numpy as np import cv2 img = cv2.imread('cat.jpg') # 这里需要我们在当前目录下放一张名为cat.jpg的文件 img.tofile('cat.raw') #利用numpy中array的函数tofile将数据写入文件 #这时我们发现当前目录下新增了一个文件,名为cat.raw 有了raw文件,我们就可以读取这个文件,并显示出来. #
-
python误差棒图errorbar()函数实例解析
这篇文章主要介绍了python误差棒图errorbar()函数实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 函数功能:绘制y轴方向或是x轴方向的误差范围. 调用签名:plt.errorbar(x, y, yerr=a, xerr=b) x:数据点的水平位置 y:数据点的垂直位置 yerr:y轴方向的数据点的误差计算方法 xerr:x轴方向的数据点的误差计算方法 代码实现: import matplotlib.pyplot as plt
-
python中pandas.read_csv()函数的深入讲解
这里将更新最新的最全面的read_csv()函数功能以及参数介绍,参考资料来源于官网. pandas库简介 官方网站里详细说明了pandas库的安装以及使用方法,在这里获取最新的pandas库信息,不过官网仅支持英文. pandas是一个Python包,并且它提供快速,灵活和富有表现力的数据结构.这样当我们处理"关系"或"标记"的数据(一维和二维数据结构)时既容易又直观. pandas是我们运用Python进行实际.真实数据分析的基础,同时它是建立在NumPy之上的
-
Python Pandas pandas.read_sql函数实例用法
Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一.本文主要介绍一下Pandas中read_sql方法的使用. pandas.read_sql(sql,con,index_col = None,coerce_float = True,params