Python超简单分析评论提取关键词制作精美词云流程
目录
- 一、抓取全部评论
- 1、找到评论接口
- 2、Python 获取评论
- 二、文本分词、词云制作
- 1、文本分析
- 2、生成词云
- 3、初步效果-模糊不清
- 4、最终效果-高清无马
一、抓取全部评论
吾的这篇文章,有 1022 次评论,一条条看,吾看不过来,于是想到 Python 词云,提取关键词,倒也是一桩趣事。

评论情况: {'android': 545 次, 'ios': 110 次, 'pc': 44 次, 'uniapp': 1 次}
一个小细节:给我评论的设备中,安卓苹果比是 5:1。
Building prefix dict from the default dictionary ... Loading model cost 0.361 seconds. Prefix dict has been built successfully.
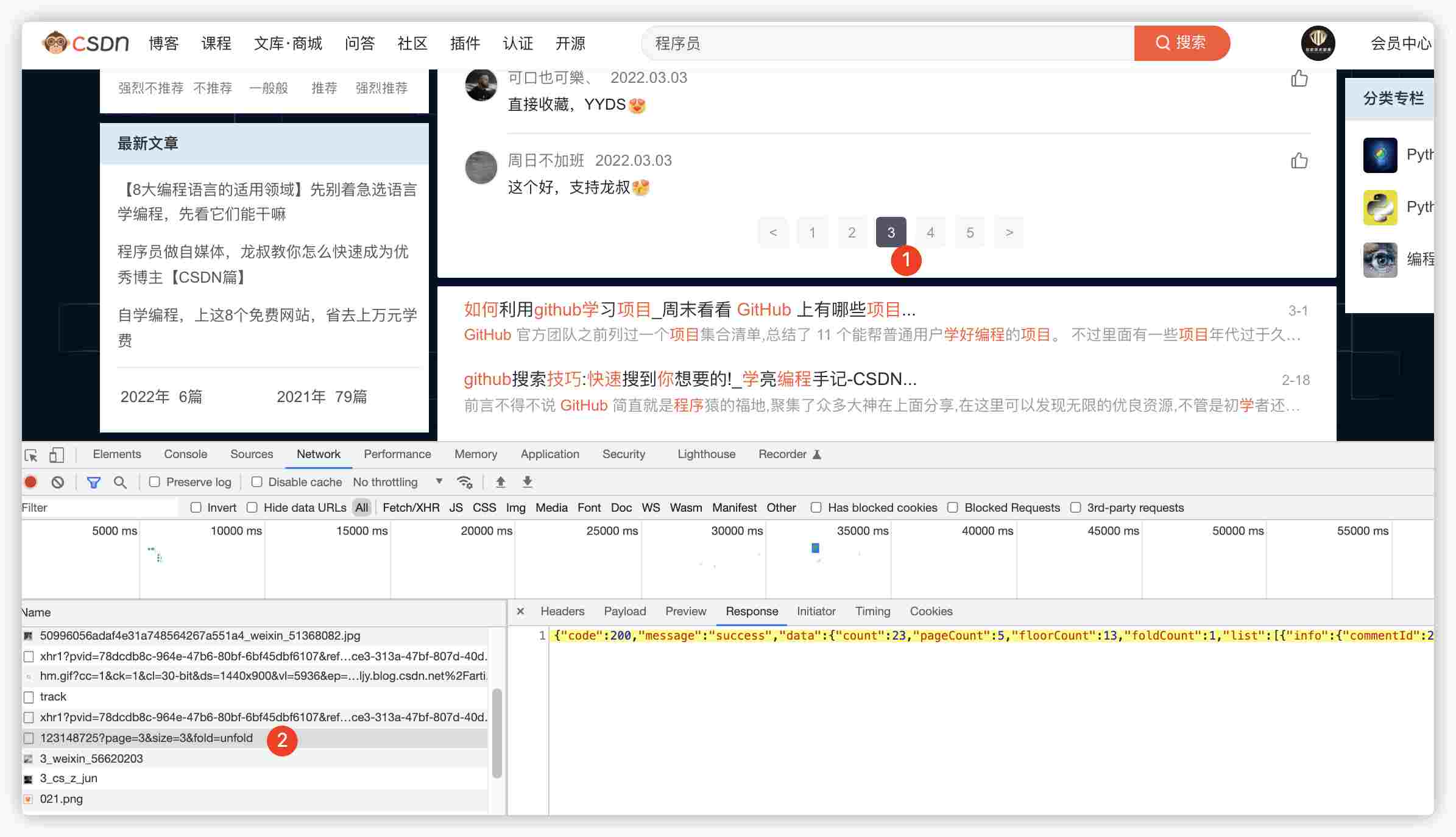
1、找到评论接口
- 打开 chrome 浏览器,开发者模式
- 点击评论列表(图标 1)
- 点击接口链接(图标 2)
- 查看 response 返回值(评论结果的 json 格式)
2、Python 获取评论
def get_comments(articleId):
# 确定评论的页数
main_res = get_commentId(articleId,1)
pageCount = json.loads(main_res)['data']['pageCount']
comment_list,comment_list2 = [],[]
source_analy = {}
for p in range(1,pageCount+1):
res = get_commentId(articleId, p)
try:
commentIds = json.loads(res)['data']['list']
for i in commentIds:
commentId = i['info']['commentId']
userName = i['info']['userName']
nickName = i['info']['nickName'] ## 获取用户名
source_dvs = i['info']['commentFromTypeResult']['key'] # 操作设备
content = i['info']['content']
comment_list.append([commentId, userName, nickName, source_dvs, content])
comment_list2.append("%s 丨 %s"%(userName, nickName))
if source_dvs not in source_analy.keys():
source_analy[source_dvs] = 1
else:
source_analy[source_dvs] = source_analy[source_dvs] + 1
# print(source_analy)
except:
print('本页失败!')
print('评论数:' + str(len(comment_list)))
return source_analy, comment_list, comment_list2
二、文本分词、词云制作
1、文本分析
西红柿采用的是 结巴 分词, 和 wordcloud。
# -*- coding:utf8 -*- import jieba import wordcloud
代码实现:
seg_list = jieba.cut(comments, cut_all=False) # 精确模式
word = ' '.join(seg_list)
2、生成词云
背景图 西红柿采用的是 心形图片
pic = mpimg.imread('/Users/pray/Downloads/aixin.jpeg')
完整代码::
def word_cloud(articleId):
source_analy, comment_list, comment_list2 = get_comments(articleId)
print("评论情况:", source_analy)
comments = ''
for one in comment_list:
comment = one[4]
if 'face' not in comment:
comments = comments + comment
seg_list = jieba.cut(comments, cut_all=False) # 精确模式
word = ' '.join(seg_list)
pic = mpimg.imread('/Users/pray/Downloads/aixin.jpeg')
wc = wordcloud.WordCloud(mask=pic, font_path='/Library/Fonts/Songti.ttc', width=1000, height=500,
background_color='white').generate(word)
3、初步效果-模糊不清

西红柿发现文字模糊、图像曲线边缘不清晰的问题。
于是,指定分辨率,高清整起来。
# 保存
plt.savefig('xin300.png', dpi=300) #指定分辨率保存
4、最终效果-高清无马

到此这篇关于Python超简单分析评论提取关键词制作精美词云流程的文章就介绍到这了,更多相关Python 制作词云内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python制作个性化的词云图实例讲解
目录 1. 引言 2. 举个栗子 2.1 安装stylecloud库 2.2 生成词云图 2.3 美化显示效果 2.4 处理停用词 2.5 使用自定义背景图像 3. 总结 1. 引言 词云图可以让我们方便地识别出文本中的关键词,其中单词的大小代表它们的频率.有了这个,我们甚至在阅读之前就可以很好地了解文本的内容.虽然有很多免费的工具可以在线制作文字云,但我们可以使用万能的Python来定制个性化的词云图. 在本文中,我们将使用第三方Python库stylecloud,有了该库,可以通过简短的几行
-
用Python采集《雪中悍刀行》弹幕做成词云实例
目录 前言 知识点介绍 环境介绍 代码实现 1. 导入模块 2. 发送网络请求 3. 获取数据 弹幕内容 4. 解析数据(筛选数据) 提取想要的一些内容 不想要的忽略掉 5. 保存数据 6. 词云图可视化 总结 前言 最近已经播完第一季的电视剧<雪中悍刀行>,从播放量就可以看出观众对于这部剧的期待,总播放量达到50亿,可让人遗憾的是,豆瓣评分只有5.7,甚至都没有破6. 很多人会把这个剧和<庆余年>做对比,因为主创班底相同 400余万字的同名小说曾被捧为网文界里的“名著”,不少粉丝
-
Python爬取百度春节祝福语并生成心形词云
目录 前言 环境 思路 源代码 前言 最近刚好在看爬虫,就爬取一下春节祝福语,生成个词云玩一玩,大家有兴趣可以试试,会奉上源代码,很简单.效果图如下: 环境 环境:windows, 语言:python,python版本是3.7 所依赖的第三方包: selenium----爬取网站,收集祝福语,这个库做UI自动化测试的估计会比较常见,我这里没采用使用requests库去爬取,用这个库的好处是爬取的过程中页面是实时可见的 wordcloud---用来生成词云 PIL---使词云生成想要的轮廓, 这里
-
Python selenium把歌词评论做成词云图
目录 前言 本次目的 本次用到的模块和包: 驱动安装 一.下载歌曲评论 1.代码实现 2.爬取评论运行效果 二.制作词云图 总结 前言 一首歌热门了,参与评论的人也很多,这时无论好坏评论都来了,没有人控评得话,指不定乱七八糟 但是自己有喜欢看评论,不想影响好心情,想看看精彩评论,看看歌词立意,那怎么办呢? 那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析… 本次目的 用selenium自动把歌词评论下载下来,做成好看的词云图 本次用到的模块和包: re # 正则表达式 内置模块
-
Python采集电视剧《开端》弹幕做成词云图
目录 知识点介绍 环境介绍 网站分析 完整爬虫代码实现 结果展示 总结 知识点介绍 爬虫基本思路流程 requests模块的使用 pandas保存表格数据 pyecharts做词云图可视化 环境介绍 python 3.8 pycharm requests >>> pip install requests pyecharts >>> pip install pyecharts 网站分析 打开X讯视频的网页,点开<开端>,播放视频,弹幕随之出现再屏幕之上. 首先
-
python如何用pyecharts制作词云图
需要安装pyecharts pip install pyecharts -U 创建[demo6.py]并输入以下编码: from pyecharts import options as opts from pyecharts.charts import Page, WordCloud words = [ ("神医", 10000), ("马良", 6181), ("玛丽", 4386), ("终结者", 4055), (&qu
-
用python实现词云效果实例介绍
目录 什么是词云 一.特效预览 二.程序原理 三.程序源码 总结 什么是词云 词云其实就是就是对网络文本中出现频率较高的〝关键词〞予以视觉上的突出,形成〝关键词云层〞或〝关键词渲染〞从而过滤掉大量的文本信息 词云也是数据可视化的一种形式.给出一段文本,根据关键词的出现频率而生成的一幅图像,人们只要扫一眼就能够明白其文章主旨. 一.特效预览 词云图 二.程序原理 从给出的文本中,进行分词处理,然后将每个词出现的的频率进行统计从给出的背景图片上,读出图片信息将文本按照出现的频率进行画图,出现频率越高
-
Python超简单分析评论提取关键词制作精美词云流程
目录 一.抓取全部评论 1.找到评论接口 2.Python 获取评论 二.文本分词.词云制作 1.文本分析 2.生成词云 3.初步效果-模糊不清 4.最终效果-高清无马 一.抓取全部评论 吾的这篇文章,有 1022 次评论,一条条看,吾看不过来,于是想到 Python 词云,提取关键词,倒也是一桩趣事. 评论情况: {'android': 545 次, 'ios': 110 次, 'pc': 44 次, 'uniapp': 1 次} 一个小细节:给我评论的设备中,安卓苹果比是 5:1. Bu
-
python超简单解决约瑟夫环问题
本文实例讲述了python超简单解决约瑟夫环问题的方法.分享给大家供大家参考.具体分析如下: 约瑟环问题大家都熟悉.题目是这样的.一共有三十个人,从1-30依次编号.每次隔9个人就踢出去一个人.求踢出的前十五个人的号码: 明显的约瑟夫环问题,python实现代码如下: a = [ x for x in range(1,31) ] #生成编号 del_number = 8 #该删除的编号 for i in range(15): print a[del_number] del a[del_numbe
-
Python实现简单自动评论自动点赞自动关注脚本
目录 前言 开发环境 原理: 1. 请求伪装 2. 获取搜索内容的方法 3. 获取作品评论 4. 自动评论 5. 点赞操作 6. 关注操作 7. 获取创作者信息 8. 获取创作者视频 9. 调用函数 前言 今天的这个脚本,是一个别人发的外包,交互界面的代码就不在这里说了,但是可以分享下自动评论.自动点赞.自动关注.采集评论和视频的数据是如何实现的 开发环境 python 3.8 运行代码pycharm 2021.2 辅助敲代码requests 第三方模块 原理: 模拟客户端,向服务器发送请求 代
-
Python超简单容易上手的画图工具库(适合新手)
前言 今天,在网上发现一款很棒的python画图工具库.很简单的api调用就能生成漂亮的图表.并且可以进行一些互动. pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 JS 库.用 Echarts 生成的图可视化效果非常棒.废话不多说下来直接看效果(对于我这种没审美感的人来是我觉得挺漂亮的). 使用之前需要安装一下:安装命令很简单:Pip就可以安装: 这里我安装在我的虚拟环境中了:pip install pyecharts . 官方的文档
-
Python超简单容易上手的画图工具库推荐
今天,在网上发现一款很棒的python画图工具库.很简单的api调用就能生成漂亮的图表.并且可以进行一些互动. pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 JS 库.用 Echarts 生成的图可视化效果非常棒.废话不多说下来直接看效果(对于我这种没审美感的人来是我觉得挺漂亮的). 使用之前需要安装一下:安装命令很简单:Pip就可以安装: 这里我安装在我的虚拟环境中了:pip install pyecharts . 官方的文档和de
-
Python制作圣诞树和圣诞树词云
目录 一.前言 二.Python画圣诞树 1. 圣诞树1号 2. 圣诞树2号 3. 圣诞树3号 三.Python制作圣诞树词云 四.彩蛋 一.前言 圣诞节庆祝和送礼物貌似现在已经成为全球流行的习惯~ 本文利用 Python 制作圣诞树和词云,教会你多种方法,代码直接运行即可,学会拿去送给你想要祝福的人吧~~ 二.Python画圣诞树 1. 圣诞树1号 # -*- coding: UTF-8 -*- """ @Author :叶庭云 @公众号 :AI庭云君 @CSDN :htt
-
Python 微信之获取好友昵称并制作wordcloud的实例
最近看到网上有人用Python获取微信的一些信息,感觉挺有意思,对于我一个Python刚入门的人来说,正需要一些代码片段来激起我的兴趣,所以自己也写了一些,废话不多说,直接上代码!!! coding:utf-8 微信好友昵称WordCloud import itchat import re import os import matplotlib.pyplot as plt from wordcloud import WordCloud, ImageColorGenerator import nu
-
Python将QQ聊天记录生成词云的示例代码
在这个情人节前夕,我把现任对象回收掉了,这段感情积攒了太多的失望,也给了我太多的伤害,所以我看到这个活动的第一反应是拒绝的.然而人生嘛,最重要的就是体验,沉浸在过去的回忆里没有意义,积极面对才能让自己更好地重振旗鼓. 所以,当大家都一致地在这个活动里各种秀恩爱时,我决定走一条不一样的路来为单身狗和刚分手的小伙伴们打打气:时间能改变的,是那些原本就不坚定的东西,未来的路还很长,笑一笑,一切都会过去的! 言归正传,我们要做的任务是,把 QQ 分手聊天记录导出,使用 Python 分词后做成分开的桃心
-
利用python实现简单的情感分析实例教程
目录 1 数据导入及预处理 1.1 数据导入 1.2 数据描述 1.3 数据预处理 2 情感分析 2.1 情感分 2.2 情感分直方图 2.3 词云图 2.4 关键词提取 3 积极评论与消极评论 3.1 积极评论与消极评论占比 3.2 消极评论分析 总结 python实现简单的情感分析 1 数据导入及预处理 1.1 数据导入 # 数据导入 import pandas as pd data = pd.read_csv('../data/京东评论数据.csv') data.head() 1.2 数据