Pytorch十九种损失函数的使用详解
损失函数通过torch.nn包实现,
1 基本用法
criterion = LossCriterion() #构造函数有自己的参数 loss = criterion(x, y) #调用标准时也有参数
2 损失函数
2-1 L1范数损失 L1Loss
计算 output 和 target 之差的绝对值。
torch.nn.L1Loss(reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-2 均方误差损失 MSELoss
计算 output 和 target 之差的均方差。
torch.nn.MSELoss(reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-3 交叉熵损失 CrossEntropyLoss
当训练有 C 个类别的分类问题时很有效. 可选参数 weight 必须是一个1维 Tensor, 权重将被分配给各个类别. 对于不平衡的训练集非常有效。
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。

torch.nn.CrossEntropyLoss(weight=None, ignore_index=-100, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor
ignore_index (int, optional) – 设置一个目标值, 该目标值会被忽略, 从而不会影响到 输入的梯度。
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-4 KL 散度损失 KLDivLoss
计算 input 和 target 之间的 KL 散度。KL 散度可用于衡量不同的连续分布之间的距离, 在连续的输出分布的空间上(离散采样)上进行直接回归时 很有效.
torch.nn.KLDivLoss(reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-5 二进制交叉熵损失 BCELoss
二分类任务时的交叉熵计算函数。用于测量重构的误差, 例如自动编码机. 注意目标的值 t[i] 的范围为0到1之间.
torch.nn.BCELoss(weight=None, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个 batch 元素的 loss 的权重. 必须是一个长度为 “nbatch” 的 的 Tensor
pos_weight(Tensor, optional) – 自定义的每个正样本的 loss 的权重. 必须是一个长度 为 “classes” 的 Tensor
2-6 BCEWithLogitsLoss
BCEWithLogitsLoss损失函数把 Sigmoid 层集成到了 BCELoss 类中. 该版比用一个简单的 Sigmoid 层和 BCELoss 在数值上更稳定, 因为把这两个操作合并为一个层之后, 可以利用 log-sum-exp 的 技巧来实现数值稳定.
torch.nn.BCEWithLogitsLoss(weight=None, reduction='mean', pos_weight=None)
参数:
weight (Tensor, optional) – 自定义的每个 batch 元素的 loss 的权重. 必须是一个长度 为 “nbatch” 的 Tensor
pos_weight(Tensor, optional) – 自定义的每个正样本的 loss 的权重. 必须是一个长度 为 “classes” 的 Tensor
2-7 MarginRankingLoss
torch.nn.MarginRankingLoss(margin=0.0, reduction='mean')
对于 mini-batch(小批量) 中每个实例的损失函数如下:

参数:
margin:默认值0
2-8 HingeEmbeddingLoss
torch.nn.HingeEmbeddingLoss(margin=1.0, reduction='mean')
对于 mini-batch(小批量) 中每个实例的损失函数如下:

参数:
margin:默认值1
2-9 多标签分类损失 MultiLabelMarginLoss
torch.nn.MultiLabelMarginLoss(reduction='mean')
对于mini-batch(小批量) 中的每个样本按如下公式计算损失:

2-10 平滑版L1损失 SmoothL1Loss
也被称为 Huber 损失函数。
torch.nn.SmoothL1Loss(reduction='mean')

其中
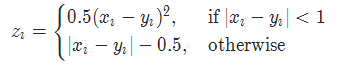
2-11 2分类的logistic损失 SoftMarginLoss
torch.nn.SoftMarginLoss(reduction='mean')
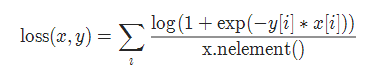
2-12 多标签 one-versus-all 损失 MultiLabelSoftMarginLoss
torch.nn.MultiLabelSoftMarginLoss(weight=None, reduction='mean')

2-13 cosine 损失 CosineEmbeddingLoss
torch.nn.CosineEmbeddingLoss(margin=0.0, reduction='mean')

参数:
margin:默认值0
2-14 多类别分类的hinge损失 MultiMarginLoss
torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, reduction='mean')

参数:
p=1或者2 默认值:1
margin:默认值1
2-15 三元组损失 TripletMarginLoss
torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, reduction='mean')

其中:
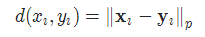
2-16 连接时序分类损失 CTCLoss
CTC连接时序分类损失,可以对没有对齐的数据进行自动对齐,主要用在没有事先对齐的序列化数据训练上。比如语音识别、ocr识别等等。
torch.nn.CTCLoss(blank=0, reduction='mean')
参数:
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-17 负对数似然损失 NLLLoss
负对数似然损失. 用于训练 C 个类别的分类问题.
torch.nn.NLLLoss(weight=None, ignore_index=-100, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor
ignore_index (int, optional) – 设置一个目标值, 该目标值会被忽略, 从而不会影响到 输入的梯度.
2-18 NLLLoss2d
对于图片输入的负对数似然损失. 它计算每个像素的负对数似然损失.
torch.nn.NLLLoss2d(weight=None, ignore_index=-100, reduction='mean')
参数:
weight (Tensor, optional) – 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor
reduction-三个值,none: 不使用约简;mean:返回loss和的平均值; sum:返回loss的和。默认:mean。
2-19 PoissonNLLLoss
目标值为泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, eps=1e-08, reduction='mean')
参数:
log_input (bool, optional) – 如果设置为 True , loss 将会按照公 式 exp(input) - target * input 来计算, 如果设置为 False , loss 将会按照 input - target * log(input+eps) 计算.
full (bool, optional) – 是否计算全部的 loss, i. e. 加上 Stirling 近似项 target * log(target) - target + 0.5 * log(2 * pi * target).
eps (float, optional) – 默认值: 1e-8
参考资料
到此这篇关于Pytorch十九种损失函数的使用详解的文章就介绍到这了,更多相关Pytorch 损失函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch 实现cross entropy损失函数计算方式
均方损失函数: 这里 loss, x, y 的维度是一样的,可以是向量或者矩阵,i 是下标. 很多的 loss 函数都有 size_average 和 reduce 两个布尔类型的参数.因为一般损失函数都是直接计算 batch 的数据,因此返回的 loss 结果都是维度为 (batch_size, ) 的向量. (1)如果 reduce = False,那么 size_average 参数失效,直接返回向量形式的 loss (2)如果 reduce = True,那么 loss 返回的是标量 a
-
Pytorch 的损失函数Loss function使用详解
1.损失函数 损失函数,又叫目标函数,是编译一个神经网络模型必须的两个要素之一.另一个必不可少的要素是优化器. 损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等. 损失Loss必须是标量,因为向量无法比较大小(向量本身需要通过范数等标量来比较). 损失函数一般分为4种,平方损失函数,对数损失函数,HingeLoss 0-1 损失函数,绝对值损失函数. 我们先定义两个二维数组,然后用不同的损失函数计算其损失值. import
-
Pytorch十九种损失函数的使用详解
损失函数通过torch.nn包实现, 1 基本用法 criterion = LossCriterion() #构造函数有自己的参数 loss = criterion(x, y) #调用标准时也有参数 2 损失函数 2-1 L1范数损失 L1Loss 计算 output 和 target 之差的绝对值. torch.nn.L1Loss(reduction='mean') 参数: reduction-三个值,none: 不使用约简:mean:返回loss和的平均值: sum:返回loss的和.默认:
-
C语言 数据结构链表的实例(十九种操作)
C语言 数据结构链表的实例(十九种操作) #include <stdio.h> #include <string.h> #include <stdlib.h> /*************************************************************************************/ /* 第一版博主 原文地址 http://www.cnblogs.com/renyuan/archive/2013/05/21/30915
-
Pytorch 实现sobel算子的卷积操作详解
卷积在pytorch中有两种实现,一种是torch.nn.Conv2d(),一种是torch.nn.functional.conv2d(),这两种方式本质都是执行卷积操作,对输入的要求也是一样的,首先需要输入的是一个torch.autograd.Variable()的类型,大小是(batch,channel, H,W),其中batch表示输入的一批数据的数目,channel表示输入的通道数. 一般一张彩色的图片是3,灰度图片是1,而卷积网络过程中的通道数比较大,会出现几十到几百的通道数.H和W表
-

PyTorch快速搭建神经网络及其保存提取方法详解
有时候我们训练了一个模型, 希望保存它下次直接使用,不需要下次再花时间去训练 ,本节我们来讲解一下PyTorch快速搭建神经网络及其保存提取方法详解 一.PyTorch快速搭建神经网络方法 先看实验代码: import torch import torch.nn.functional as F # 方法1,通过定义一个Net类来建立神经网络 class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output):
-
Pytorch在NLP中的简单应用详解
因为之前在项目中一直使用Tensorflow,最近需要处理NLP问题,对Pytorch框架还比较陌生,所以特地再学习一下pytorch在自然语言处理问题中的简单使用,这里做一个记录. 一.Pytorch基础 首先,第一步是导入pytorch的一系列包 import torch import torch.autograd as autograd #Autograd为Tensor所有操作提供自动求导方法 import torch.nn as nn import torch.nn.functional
-
PyTorch加载自己的数据集实例详解
数据预处理在解决深度学习问题的过程中,往往需要花费大量的时间和精力. 数据处理的质量对训练神经网络来说十分重要,良好的数据处理不仅会加速模型训练, 更会提高模型性能.为解决这一问题,PyTorch提供了几个高效便捷的工具, 以便使用者进行数据处理或增强等操作,同时可通过并行化加速数据加载. 数据集存放大致有以下两种方式: (1)所有数据集放在一个目录下,文件名上附有标签名,数据集存放格式如下: root/cat_dog/cat.01.jpg root/cat_dog/cat.02.jpg ...
-
Python 十大经典排序算法实现详解
目录 关于时间复杂度 关于稳定性 名词解释 1.冒泡排序 (1)算法步骤 (2)动图演示 (3)Python代码 2.选择排序 (1)算法步骤 (2)动图演示 (3)Python代码 3.插入排序 (1)算法步骤 (2)动图演示 (3)Python代码 4.希尔排序 (1)算法步骤 (2)Python代码 5.归并排序 (1)算法步骤 (2)动图演示 (3)Python代码 6.快速排序 (1)算法步骤 (2)动图演示 (3)Python代码 7.堆排序 (1)算法步骤 (2)动图演示 (3)P
-
Pytorch图像处理注意力机制解析及代码详解
什么是注意力机制 注意力机制是一个非常有效的trick,注意力机制的实现方式有许多,我们一起来学习一下 注意力机制是深度学习常用的一个小技巧,它有多种多样的实现形式,尽管实现方式多样,但是每一种注意力机制的实现的核心都是类似的,就是注意力. 注意力机制的核心重点就是让网络关注到它更需要关注的地方. 当我们使用卷积神经网络去处理图片的时候,我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为
-
利用Pytorch实现获取特征图的方法详解
目录 简单加载官方预训练模型 图片预处理 提取单个特征图 提取多个特征图 简单加载官方预训练模型 torchvision.models预定义了很多公开的模型结构 如果pretrained参数设置为False,那么仅仅设定模型结构:如果设置为True,那么会启动一个下载流程,下载预训练参数 如果只想调用模型,不想训练,那么设置model.eval()和model.requires_grad_(False) 想查看模型参数可以使用modules和named_modules,其中named_modul
-
pytorch从头开始搭建UNet++的过程详解
目录 Unet++代码 网络架构 Backbone 上采样 下采样 深度监督 网络架构代码 Unet是一个最近比较火的网络结构.它的理论已经有很多大佬在讨论了.本文主要从实际操作的层面,讲解pytorch从头开始搭建UNet++的过程. Unet++代码 网络架构 黑色部分是Backbone,是原先的UNet. 绿色箭头为上采样,蓝色箭头为密集跳跃连接. 绿色的模块为密集连接块,是经过左边两个部分拼接操作后组成的 Backbone 2个3x3的卷积,padding=1. class VGGBlo