python爬虫今日热榜数据到txt文件的源码
今日热榜:https://tophub.today/

爬取数据及保存格式:

爬取后保存为.txt文件:

部分内容:
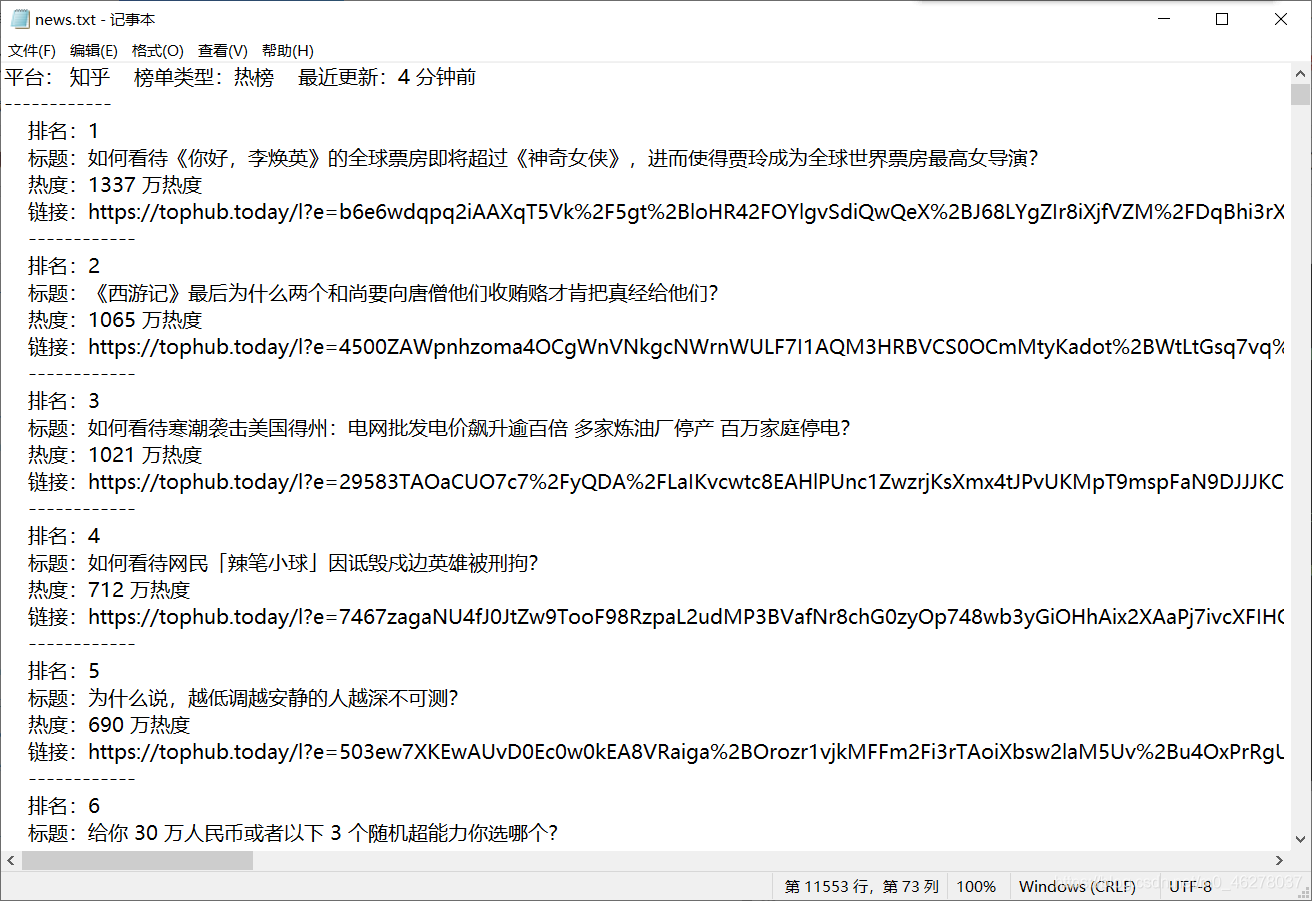

源码及注释:
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
try:
r = requests.get(url,timeout = 30,headers=headers)
return r.text
except:
return "please inspect your url or setup"
def get_content(html,tag):
output = """ 排名:{}\n 标题:{} \n 热度:{}\n 链接:{}\n ------------\n"""
output2 = """平台:{} 榜单类型:{} 最近更新:{}\n------------\n"""
num=[]
title=[]
hot=[]
href=[]
soup = BeautifulSoup(html, 'html.parser')
con = soup.find('div',attrs={'class':'bc-cc'})
con_list = con.find_all('div', class_="cc-cd")
for i in con_list:
author = i.find('div', class_='cc-cd-lb').get_text() # 获取平台名字
time = i.find('div', class_='i-h').get_text() # 获取最近更新
link = i.find('div', class_='cc-cd-cb-l').find_all('a') # 获取所有链接
gender = i.find('span', class_='cc-cd-sb-st').get_text() # 获取类型
save_txt(tag,output2.format(author, gender,time))
for k in link:
href.append(k['href'])
num.append(k.find('span', class_='s').get_text())
title.append(str(k.find('span', class_='t').get_text()))
hot.append(str(k.find('span', class_='e').get_text()))
for h in range(len(num)):
save_txt(tag,output.format(num[h], title[h], hot[h], href[h]))
def save_txt(tag,*args):
for i in args:
with open(tag+'.txt', 'a', encoding='utf-8') as f:
f.write(i)
def main():
# 综合 科技 娱乐 社区 购物 财经
page=['news','tech','ent','community','shopping','finance']
for tag in page:
url = 'https://tophub.today/c/{}'.format(tag)
html = download_page(url)
get_content(html,tag)
if __name__ == '__main__':
main()
到此这篇关于python爬虫今日热榜数据到txt文件的源码的文章就介绍到这了,更多相关python爬虫今日热榜数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现数据可视化看如何监控你的爬虫状态【推荐】
今天主要是来说一下怎么可视化来监控你的爬虫的状态. 相信大家在跑爬虫的过程中,也会好奇自己养的爬虫一分钟可以爬多少页面,多大的数据量,当然查询的方式多种多样.今天我来讲一种可视化的方法. 关于爬虫数据在mongodb里的版本我写了一个可以热更新配置的版本,即添加了新的爬虫配置以后,不用重启程序,即可获取刚刚添加的爬虫的状态数据. 1.成品图 这个是监控服务器网速的最后成果,显示的是下载与上传的网速,单位为M.爬虫的原理都是一样的,只不过将数据存到InfluxDB的方式不一样而已, 如下图. 可以
-

Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息,包含公交.地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集.闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交.地铁站点和数据. 首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线.可以通过图吧公交.公交网.8684.本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称.Pyth
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
python2.7实现爬虫网页数据
最近刚学习Python,做了个简单的爬虫,作为一个简单的demo希望帮助和我一样的初学者. 代码使用python2.7做的爬虫 抓取51job上面的职位名,公司名,薪资,发布时间等等. 直接上代码,代码中注释还算比较清楚 ,没有安装mysql需要屏蔽掉相关代码: #!/usr/bin/python # -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import urllib import urllib2 import codecs im
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
python爬虫今日热榜数据到txt文件的源码
今日热榜:https://tophub.today/ 爬取数据及保存格式: 爬取后保存为.txt文件: 部分内容: 源码及注释: import requests from bs4 import BeautifulSoup def download_page(url): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko
-
Python爬虫实战之网易云音乐加密解析附源码
目录 环境 知识点 第一步 第二步 开始代码 先导入所需模块 请求数据 提取我们真正想要的 音乐的名称 id 导入js文件 保存文件 完整代码 环境 python3.8 pycharm2021.2 知识点 requests >>> pip install requests execjs >>> pip install PyExecJS 第一步 打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id 去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
-
Python编写一个验证码图片数据标注GUI程序附源码
做验证码图片的识别,不论是使用传统的ORC技术,还是使用统计机器学习或者是使用深度学习神经网络,都少不了从网络上采集大量相关的验证码图片做数据集样本来进行训练. 采集验证码图片,可以直接使用Python进行批量下载,下载完之后,就需要对下载下来的验证码图片进行标注.一般情况下,一个验证码图片的文件名就是图片中验证码的实际字符串. 在不借助工具的情况下,我们对验证码图片进行上述标注的流程是: 1.打开图片所在的文件夹: 2.选择一个图片: 3.鼠标右键重命名: 4.输入正确的字符串: 5.保存 州
-
Python爬虫爬取微博热搜保存为 Markdown 文件的源码
什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫. 其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据 爬虫可以做什么? 你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到. 爬虫的本质是什么? 上面关于爬虫可以做什么,定义了一个前提
-
python获取百度热榜链接的实例方法
目标网址: https://www.baidu.com/ 要获取的内容: 链接分析: 从下图可以看出只需要获取关键字,再构建就可以了. 完整代码: import requests import pprint import re import urllib.parse url = 'https://www.baidu.com/' headers = { 'Host': 'www.baidu.com', 'Referer': 'https://www.baidu.com/',
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别
-
Python爬虫采集微博视频数据
目录 前言 知识点 开发环境 爬虫原理 案例实现 前言 随时随地发现新鲜事!微博带你欣赏世界上每一个精彩瞬间,了解每一个幕后故事.分享你想表达的,让全世界都能听到你的心声!今天我们通过python去采集微博当中好看的视频! 没错,今天的目标是微博数据采集,爬的是那些好看的小姐姐视频 知识点 requests pprint 开发环境 版 本:python 3.8 -编辑器:pycharm 2021.2 爬虫原理 作用:批量获取互联网数据(文本, 图片, 音频, 视频) 本质:一次次的请求与响应
-
Python爬虫爬取疫情数据并可视化展示
目录 知识点 开发环境 爬虫完整代码 导入模块 分析网站 发送请求 获取数据 解析数据 保存数据 数据可视化 导入模块 读取数据 死亡率与治愈率 各地区确诊人数与死亡人数情况 知识点 爬虫基本流程 json requests 爬虫当中 发送网络请求 pandas 表格处理 / 保存数据 pyecharts 可视化 开发环境 python 3.8 比较稳定版本 解释器发行版 anaconda jupyter notebook 里面写数据分析代码 专业性 pycharm 专业代码编辑器 按照年份与月
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
Python从数据库读取大量数据批量写入文件的方法
使用机器学习训练数据时,如果数据量较大可能我们不能够一次性将数据加载进内存,这时我们需要将数据进行预处理,分批次加载进内存. 下面是代码作用是将数据从数据库读取出来分批次写入txt文本文件,方便我们做数据的预处理和训练机器学习模型. #%% import pymssql as MySQLdb #这里是python3 如果你是python2.x的话,import MySQLdb #数据库连接属性 hst = '188.10.34.18' usr = 'sa' passwd = 'p@ssw0rd'