python docx的超链接网址和链接文本操作
我就废话不多说了,大家还是直接看代码吧~
from docx import Document
from docx import RT
import re
d=Document("./liu2.docx")
for p in d.paragraphs:
rels = d.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
print("\n 超链接文本为", rels[rel], " 超链接网址为: ", rels[rel]._target)
补充:Python输出“test.docx“文档正文中的所有红色的文字、输出文档中所有的超链接地址和文本
一、题目:
1、查阅资料了解.docx文档结构,然后编写程序,输出"test.docx"文档正文中的所有红色的文字。
2、查阅资料了解.docx文档结构,然后查阅资料,编写程序,输出"测试.docx"文档中所有的超链接地址和文本。
3、已知文件“超市营业额1.xlsx”中记录了某超市2019年3月1日至5日各员工在不同时段、不同柜台的销售额。部分数据如图,要求编写程序,读取该文件的数据,并统计每个员工的销售总额、每个时段的销售总额、每个柜台的销售总额。
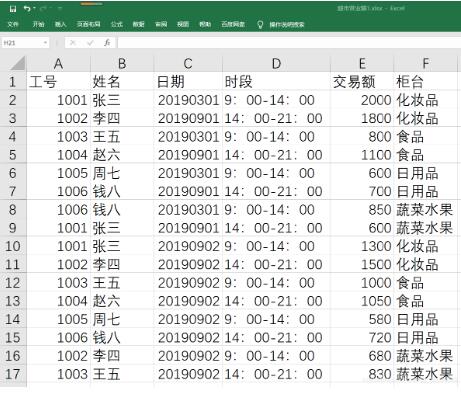
超市营业额1.xlsx文件图
二、代码展示:
# -*- coding: utf-8 -*-
""""
@Author : Jackma
@Time : 2020/11/7 21:26
@File : 2020_11_7.py
@Software: PyCharm
@URL : www.jackmark.top
@Version :
"""
# 1、查阅资料了解.docx文档结构,然后编写程序,输出"test.docx"文档正文中的所有红色的文字。
# 2、查阅资料了解.docx文档结构,然后查阅资料,编写程序,输出"测试.docx"文档中所有的超链接地址和文本。
# 3、已知文件“超市营业额1.xlsx”中记录了某超市2019年3月1日至5日各员工在不同时段、不同柜台的销售额。
# 部分数据如图,要求编写程序,读取该文件的数据,并统计每个员工的销售总额、每个时段的销售总额、每个
# 柜台的销售总额。
# 4、查阅资料,编写程序操作Excel文件。已知当前文件夹中的文件“每个人的爱好.xlsx”的内容如图中A到H列所
# 示,要求追加一列,并如图中方框所示进行汇总。
from docx import Document
from docx.shared import RGBColor
from docx.opc.constants import RELATIONSHIP_TYPE as RT
from openpyxl import load_workbook
# 1
def find_bold_red():
'''
输出文档中的所有红色的、加粗的文字
:return:
'''
# 定义两个列表
boldText = [] # 存储加粗的文字
redText = [] # 存储红色字体的文字
name1 = input('输入你要查询的文件名(without .docx):')
# doc1 = Document('test.docx') # 打开文档
doc1 = Document(name1 + '.docx') # 打开文档
for p in doc1.paragraphs: # 遍历里面的每个段落
for r in p.runs: # 找每段中所有的run, run指连续的相同格式的字体
if r.bold: # 找到加粗字体
boldText.append(r.text) # 把run的文本放到boldText文本中
if r.font.color.rgb == RGBColor(255,0,0): # rgb(255,0,0)代表红色,找到红色字体
redText.append(r.text)
result = {'red text': redText,
'bold text': boldText,
'both': set(redText) & set(boldText) # 集合的交集
}
# 输出结果
for title in result.keys():
print(title.center(30, '=')) # 长度为30,center指居中,效果如下
# ===========red text============
for text in result[title]:
print(text)
find_bold_red()
# 2
# def find_Hyperlink():
# '''
# 只适用于WPS创建的文档
# 输出"test.docx"文档中所有的超链接地址和文本
# :return:
# '''
# doc2 = Document('test.docx')
# for p in doc2.paragraphs:
# for index, run in enumerate(p.runs):
# if run.style.name == 'Hyperlink':
# print(run.text, end =':')
# for child in p.runs[index-2].element.getchildren():
# text = child.text
# if text and text.stratswith('HYPERLINK'):
# print(text[12:-2])
#
# find_Hyperlink()
def find_Hyperlink():
'''
输出"test.docx"文档中所有的超链接地址和文本
:return:
'''
docx_file=input(" 输入你要查询的文件名(without .docx): ")
document = Document(docx_file + ".docx")
rels = document.part.rels
for rel in rels:
if rels[rel].reltype == RT.HYPERLINK:
# print("\n 超链接文本为", rels[rel], " 超链接网址为: ", rels[rel]._target)
print(" 超链接网址为: ", rels[rel]._target)
find_Hyperlink()
# 3
def money():
'''
统计每个员工的销售总额、每个时段的销售总额、每个柜台的销售总额。
:return:
'''
# 3个字典分别存储按员工、按时段、按柜台的销售总额
persons = dict()
periods = dict()
goods = dict()
ws = load_workbook('超市营业额1.xlsx').worksheets[0]
for index, row in enumerate(ws.rows):
# 跳过第一行的表头
if index == 0:
continue
# 获取每行的相关信息
_, name, _, time, num, good = map(lambda cell: cell.value, row)
# 根据每行的值更新三个字典
persons[name] = persons.get(name, 0) + num
periods[time] = periods.get(time, 0) + num
goods[good] = goods.get(good, 0) + num
print(persons)
print(periods)
print(goods)
money()
三、结果展示:
首先是测试文档test.docx内容

图1 test.docx文件图
程序1、
输出"test.docx"文档正文中的所有红色的文字。

程序2、
输出"test.docx"文档中所有的超链接地址和文本。
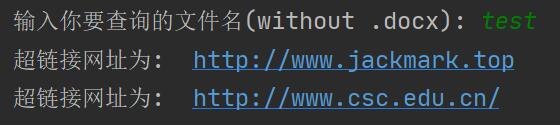
程序3、
统计每个员工的销售总额、每个时段的销售总额、每个柜台的销售总额。

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python中docx2txt库的使用说明
docx2txt的Github地址 docx2txt是基于python的从docx文件中提取文本和图片的库. 代码是从python-docx中获取的.它也可以从页眉,页脚和超链接中提取文本.它现在也可以提取图像. 安装 pip install docx2txt 运行 1.命令行运行 # extract text docx2txt file.docx # extract text and images docx2txt -i /tmp/img_dir file.docx 2.在python中调用
-

解决python 出现unknown encoding: idna 的问题
这个问题是编码的问题在开头导入个包就行了,简答粗暴 import encodings.idna 补充:执行Python出现LookupError: unknown encoding: cp65001解决办法 在执行fetch v8时出现 E:\GitProject\svn_v8>fetch v8 Running: 'E:\GitProject\libcef\depot_tools\python276_bin\python.exe' 'E:\GitProj ect\libcef\depot_too
-
使用pycallgraph分析python代码函数调用流程以及框架解析
技术背景 在上一篇博客中,我们介绍了使用量子计算模拟器ProjectQ去生成一个随机数,也介绍了随机数的应用场景等.但是有些时候我们希望可以打开这里面实现的原理,去看看在产生随机数的过程中经历了哪些运算,调用了哪些模块.只有梳理清楚这些相关的内容,我们才能够更好的使用这个产生随机数的功能.这里我们就引入一个工具pycallgraph,可以根据执行的代码,给出这些代码背后所封装和调用的所有函数.类的关系图,让我们一起来了解下这个工具的安装和使用方法. Manjaro Linux平台安装graphv
-
使用python模块plotdigitizer抠取论文图片中的数据实例详解
技术背景 对于各行各业的研究人员来说,经常会面临这样的一个问题:有一篇不错的文章里面有很好的数据,但是这个数据在文章中仅以图片的形式出现.而假如我们希望可以从该图片中提取出数据,这样就可以用我们自己的形式重新来展现这些数据,还可以额外再附上自己优化后的数据.因此从论文图片中提取数据,是一个非常实际的需求.这里以前面写的量子退火的博客为例,博客中有这样的一张图片: 在这篇文章中,我们将介绍如何使用python从图片上把数据抠取出来. plotdigitizer的安装 这里我们使用pip来安装pyt
-
python encode和decode的妙用
>>> "hello".encode("hex") '68656c6c6f' 相应的还可以 >>> '68656c6c6f'.decode("hex") 'hello' 查了一下手册,还有这些codec可用 Codec Aliases Operand type Purpose base64_codec base64, base-64 byte string Convert operand to MIME bas
-
python flask框架详解
Flask是一个Python编写的Web 微框架,让我们可以使用Python语言快速实现一个网站或Web服务.本文参考自Flask官方文档, 英文不好的同学也可以参考中文文档 1.安装flask pip install flask 2.简单上手 一个最小的 Flask 应用如下: from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World' if __na
-
python docx的超链接网址和链接文本操作
我就废话不多说了,大家还是直接看代码吧~ from docx import Document from docx import RT import re d=Document("./liu2.docx") for p in d.paragraphs: rels = d.part.rels for rel in rels: if rels[rel].reltype == RT.HYPERLINK: print("\n 超链接文本为", rels[rel], "
-
Python读取word文本操作详解
本文研究的主要问题时Python读取word文本操作,分享了相关概念和实现代码,具体如下. 一,docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的.也就是说python-docx模块会把word文档,文档中的段落.文本.字体等都看做对象,对对象进行处理就是对word文档的内容处理. 二,相关概念 如果需要读取word文档中的文字(一般来说,程序也只需要认识word文档中的文字信息),需要先了解python-docx模块的几个概念. 1,Docume
-
Python docx库用法示例分析
本文实例分析了Python docx库用法.分享给大家供大家参考,具体如下: 打开及保存文件: from docx import Document document = Document('test.docx') document.save('test.docx') 添加文本: document.add_paragraph('test text') 调整文本位置格式为居中: from docx import Document from docx.enum.text import WD_ALIGN
-
python使用urlparse分析网址中域名的方法
本文实例讲述了python使用urlparse分析网址中域名的方法.分享给大家供大家参考.具体如下: 这里给定网址,通过下面这段python代码可以很容易获取域名信息 import urlparse url = "http://www.jb51.net" domain = urlparse.urlsplit(url)[1].split(':')[0] print "The domain name of the url is: ", domain 输出结果如下: Th
-
php自动给网址加上链接的方法
本文实例讲述了php自动给网址加上链接的方法.分享给大家供大家参考.具体实现方法如下: 这里自动匹配页面里的网址,包含http,ftp等,自动给网址加上链接 function text2links($str='') { if($str=='' or !preg_match('/(http|www\.|@)/i', $str)) { return $str; } $lines = explode("\n", $str); $new_text = ''; while (list($k,$l
-
python 链接和操作 memcache方法
1,打开memcached服务 memcached -m 10 -p 12000 2,使用python-memcached模块,进行简单的链接和存取数据 import memcache mc = memcache.Client(['127.0.0.1:12000'], debug=0) mc.set("foo", "bar") mc.get("foo") mc.disconnect_all() 3,其它方法请参考: help(mc) 以上这篇py
-
Python 爬虫之超链接 url中含有中文出错及解决办法
Python 爬虫之超链接 url中含有中文出错及解决办法 python3.5 爬虫错误: UnicodeEncodeError: 'ascii' codec can't encode characters 这个错误是由于超链接中含有中文引起的,超链接默认是用ascii编码的,所以不能直接出现中文,若要出现中文, 解决方法如下: import urllib from urllib.request import urlopen link="http://list.jd.com/list.html?
-
Python获取当前页面内所有链接的四种方法对比分析
本文实例讲述了Python获取当前页面内所有链接的四种方法.分享给大家供大家参考,具体如下: ''' 得到当前页面所有连接 ''' import requests import re from bs4 import BeautifulSoup from lxml import etree from selenium import webdriver url = 'http://www.testweb.com' r = requests.get(url) r.encoding = 'gb2312'
-
详解Python文本操作相关模块
详解Python文本操作相关模块 linecache--通过使用缓存在内部尝试优化以达到高效从任何文件中读出任何行. 主要方法: linecache.getline(filename, lineno[, module_globals]):获取指定行的内容 linecache.clearcache():清除缓存 linecache.checkcache([filename]):检查缓存的有效性 dircache--定义了一个函数,使用缓存读取目录列表.使用目录的mtime来实现缓存失效.此外还定义
-
python实现下载指定网址所有图片的方法
本文实例讲述了python实现下载指定网址所有图片的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 #download pictures of the url #useage: python downpicture.py www.baidu.com import os import sys from html.parser import HTMLParser from urllib.request import urlopen from urllib.parse im