使用tensorflow进行音乐类型的分类
音乐流媒体服务的兴起使得音乐无处不在。我们在上下班的时候听音乐,锻炼身体,工作或者只是放松一下。
这些服务的一个关键特性是播放列表,通常按流派分组。这些数据可能来自出版歌曲的人手工标注。但这并不是一个很好的划分,因为可能是一些艺人想利用一个特定流派的流行趋势。更好的选择是依靠自动音乐类型分类。与我的两位合作者张伟信(Wilson Cheung)和顾长乐(Joy Gu)一起,我们试图比较不同的音乐样本分类方法。特别是,我们评估了标准机器学习和深度学习方法的性能。我们发现特征工程是至关重要的,而领域知识可以真正提高性能。
在描述了所使用的数据源之后,我对我们使用的方法及其结果进行了简要概述。在本文的最后一部分,我将花更多的时间来解释googlecolab中的TensorFlow框架如何通过TFRecord格式在GPU或TPU运行时高效地执行这些任务。所有代码都在这里,我们很高兴与感兴趣的人分享我们更详细的报告。
数据源
预测一个音频样本的类型是一个监督学习问题。换句话说,我们需要包含标记示例的数据。FreeMusicArchive是一个包含相关标签和元数据的音频片段库,最初是在2017年的国际音乐信息检索会议(ISMIR)上为论文而收集的。
我们将分析重点放在所提供数据的一小部分上。它包含8000个音频片段,每段长度为30秒,分为八种不同类型之一:
- Hip-Hop
- Pop
- Folk
- Experimental
- Rock
- International
- Electronic
- Instrumental
每种类型都有1000个代表性的音频片段。采样率为44100hz,这意味着每个音频样本有超过100万个数据点,或者总共超过10个数据点。在分类器中使用所有这些数据是一个挑战,我们将在接下来的章节中详细讨论。
有关如何下载数据的说明,请参阅存储库中包含的自述文件。我们非常感谢Michaël Defferrard、Kirell Benzi、Pierre Vandergheynst、Xavier Bresson将这些数据整合在一起并免费提供,但我们只能想象Spotify或Pandora Radio拥有的数据规模所能提供的见解。有了这些数据,我们可以描述各种模型来执行手头的任务。
模型说明
我会尽量减少理论上的细节,但会尽可能地链接到相关资源。另外,我们的报告包含的信息比我在这里能包含的要多得多,尤其是关于功能工程的信息。
标准机器学习
我们使用了Logistic回归、k-近邻(kNN)、高斯朴素贝叶斯和支持向量机(SVM):
支持向量机(SVM)通过最大化训练数据的裕度来寻找最佳决策边界。核技巧通过将数据投影到高维空间来定义非线性边界
kNN根据k个最近的训练样本的多数票分配一个标签
naivebayes根据特征预测不同类的概率。条件独立性假设大大简化了计算
Logistic回归还利用Logistic函数,通过对概率的直接建模来预测不同类别的概率
深度学习
对于深入学习,我们利用TensorFlow框架。我们根据输入的类型建立了不同的模型。
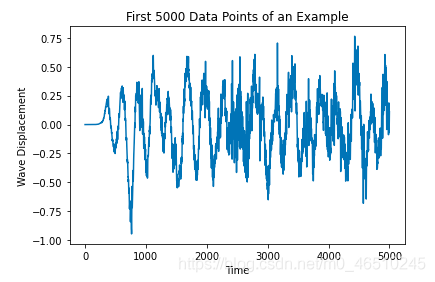
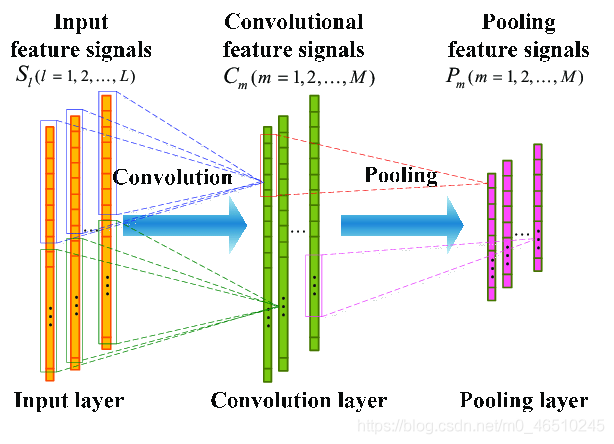
对于原始音频,每个示例是一个30秒的音频样本,或者大约130万个数据点。这些浮点值(正或负)表示在某一时刻的波位移。为了管理计算资源,只能使用不到1%的数据。有了这些特征和相关的标签(一个热点编码),我们可以建立一个卷积神经网络。总体架构如下:
一维卷积层,其中过滤器结合来自偶然数据的信息MaxPooling层,它结合了来自卷积层的信息全连接层,创建提取的卷积特征的线性组合,并执行最终的分类Dropout层,它帮助模型泛化到不可见的数据
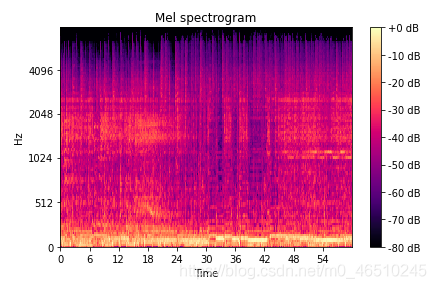
另一方面,光谱图作为音频样本的视觉表示。这启发了将训练数据视为图像,并通过迁移学习利用预先训练的模型。对于每个例子,我们可以形成一个矩阵的Mel谱图。如果我们正确计算尺寸,这个矩阵可以表示为224x224x3图像。这些都是利用MobileNetV2的正确维度,MobileNetV2在图像分类任务上有着出色的性能。转移学习的思想是使用预先训练的模型的基本层来提取特征,并用一个定制的分类器(在我们的例子中是稠密层)代替最后一层。这是因为基本层通常可以很好地泛化到所有图像,即使它们没有经过训练。
模型结果
我们使用20%的测试集来评估我们模型的性能。我们可以将结果汇总到下表中:
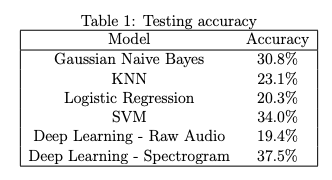
在谱图中应用迁移学习的卷积神经网络是性能最好的,尽管SVM和Gaussian naivebayes在性能上相似(考虑到后者的简化假设,这本身就很有趣)。我们在报告中描述了最好的超参数和模型体系结构。
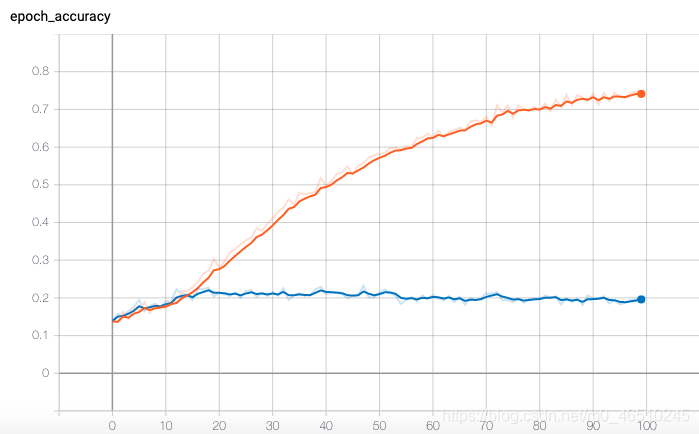
我们对训练和验证曲线的分析突出了过度拟合的问题,如下图所示(我们的大多数模型都有类似的图表)。目前的特征模式有助于我们确定这一问题。我们为此设计了一些解决方案,可以在本项目的未来迭代中实现:
- 降低数据的维数:PCA等技术可用于将提取的特征组合在一起,并限制每个示例的特征向量的大小
- 增加训练数据的大小:数据源提供更大的数据子集。我们将探索范围限制在整个数据集的10%以下。如果有更多的计算资源可用,或者成功地降低数据的维数,我们可以考虑使用完整的数据集。这很可能使我们的方法能够隔离更多的模式,并大大提高性能
- 在我们的搜索功能时请多加注意:FreeMusicChive包含一系列功能。当我们使用这些特性而不是我们自己的特性时,我们确实看到了性能的提高,这使我们相信我们可以希望通过领域知识和扩展的特征集获得更好的结果
TensorFlow实现
TensorFlow是一个非常强大的工具,可以在规模上构建神经网络,尤其是与googlecolab的免费GPU/TPU运行时结合使用。这个项目的主要观点是找出瓶颈:我最初的实现非常缓慢,甚至使用GPU。我发现问题出在I/O过程(从磁盘读取数据,这是非常慢的)而不是训练过程。使用TFrecord格式可以通过并行化来加快速度,这使得模型的训练和开发更快。
在我开始之前,有一个重要的注意事项:虽然数据集中的所有歌曲都是MP3格式,但我将它们转换成wav文件,因为TensorFlow有更好的内置支持。请参考GitHub上的库以查看与此项目相关的所有代码。代码还假设您有一个Google云存储桶,其中所有wav文件都可用,一个上载元数据的Google驱动器,并且您正在使用googlecolab。尽管如此,将所有代码调整到另一个系统(基于云的或本地的)应该相对简单。
初始设置
这个项目需要大量的库。这个requirements.txt存储库中的文件为您处理安装,但您也可以找到下面的详细列表。
# import libraries import pandas as pd import tensorflow as tf from IPython.display import Audio import os import matplotlib.pyplot as plt import numpy as np import math import sys from datetime import datetime import pickle import librosa import ast import scipy import librosa.display from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow import keras from google.colab import files keras.backend.clear_session() tf.random.set_seed(42) np.random.seed(42)
第一步是挂载驱动器(数据已上传的位置),并使用存储音频文件的GCS存储桶进行身份验证。从技术上讲,数据也可以上传到GCS,这样就不需要安装驱动器了,但我自己的项目就是这样构建的。
# mount the drive
# adapted from https://colab.sandbox.google.com/notebooks/io.ipynb#scrollTo=S7c8WYyQdh5i
from google.colab import drive
drive.mount('/content/drive')
# load the metadata to Colab from Drive, will greatly speed up the I/O process
zip_path_metadata = "/content/drive/My Drive/master_degree/machine_learning/Project/fma_metadata.zip"
!cp "{zip_path_metadata}" .
!unzip -q fma_metadata.zip
!rm fma_metadata.zip
# authenticate for GCS access
if 'google.colab' in sys.modules:
from google.colab import auth
auth.authenticate_user()
我们还存储了一些变量以备将来使用,例如。
# set some variables for creating the dataset AUTO = tf.data.experimental.AUTOTUNE # used in tf.data.Dataset API GCS_PATTERN = 'gs://music-genre-classification-project-isye6740/fma_small_wav/*/*.wav' GCS_OUTPUT_1D = 'gs://music-genre-classification-project-isye6740/tfrecords-wav-1D/songs' # prefix for output file names, first type of model GCS_OUTPUT_2D = 'gs://music-genre-classification-project-isye6740/tfrecords-wav-2D/songs' # prefix for output file names, second type of model GCS_OUTPUT_FEATURES = 'gs://music-genre-classification-project-isye6740/tfrecords-features/songs' # prefix for output file names, models built with extracted features SHARDS = 16 window_size = 10000 # number of raw audio samples length_size_2d = 50176 # number of data points to form the Mel spectrogram feature_size = 85210 # size of the feature vector N_CLASSES = 8 DATA_SIZE = (224,224,3) # required data size for transfer learning
创建TensorFlow数据集
下一步就是设置函数读入数据时所需的必要信息。我没有写这段代码,只是把它改编自FreeMusicArchive。这一部分很可能在您自己的项目中发生变化,这取决于您使用的数据集。
# function to load metadata
# adapted from https://github.com/mdeff/fma/blob/master/utils.py
def metadata_load(filepath):
filename = os.path.basename(filepath)
if 'features' in filename:
return pd.read_csv(filepath, index_col=0, header=[0, 1, 2])
if 'echonest' in filename:
return pd.read_csv(filepath, index_col=0, header=[0, 1, 2])
if 'genres' in filename:
return pd.read_csv(filepath, index_col=0)
if 'tracks' in filename:
tracks = pd.read_csv(filepath, index_col=0, header=[0, 1])
COLUMNS = [('track', 'tags'), ('album', 'tags'), ('artist', 'tags'),
('track', 'genres'), ('track', 'genres_all')]
for column in COLUMNS:
tracks[column] = tracks[column].map(ast.literal_eval)
COLUMNS = [('track', 'date_created'), ('track', 'date_recorded'),
('album', 'date_created'), ('album', 'date_released'),
('artist', 'date_created'), ('artist', 'active_year_begin'),
('artist', 'active_year_end')]
for column in COLUMNS:
tracks[column] = pd.to_datetime(tracks[column])
SUBSETS = ('small', 'medium', 'large')
try:
tracks['set', 'subset'] = tracks['set', 'subset'].astype(
pd.CategoricalDtype(categories=SUBSETS, ordered=True))
except ValueError:
# the categories and ordered arguments were removed in pandas 0.25
tracks['set', 'subset'] = tracks['set', 'subset'].astype(
pd.CategoricalDtype(categories=SUBSETS, ordered=True))
COLUMNS = [('track', 'genre_top'), ('track', 'license'),
('album', 'type'), ('album', 'information'),
('artist', 'bio')]
for column in COLUMNS:
tracks[column] = tracks[column].astype('category')
return tracks
# function to get genre information for each track ID
def track_genre_information(GENRE_PATH, TRACKS_PATH, subset):
"""
GENRE_PATH (str): path to the csv with the genre metadata
TRACKS_PATH (str): path to the csv with the track metadata
FILE_PATHS (list): list of paths to the mp3 files
subset (str): the subset of the data desired
"""
# get the genre information
genres = pd.read_csv(GENRE_PATH)
# load metadata on all the tracks
tracks = metadata_load(TRACKS_PATH)
# focus on the specific subset tracks
subset_tracks = tracks[tracks['set', 'subset'] <= subset]
# extract track ID and genre information for each track
subset_tracks_genre = np.array([np.array(subset_tracks.index),
np.array(subset_tracks['track', 'genre_top'])]).T
# combine the information in a dataframe
tracks_genre_df = pd.DataFrame({'track_id': subset_tracks_genre[:,0], 'genre': subset_tracks_genre[:,1]})
# label classes with numbers
encoder = LabelEncoder()
tracks_genre_df['genre_nb'] = encoder.fit_transform(tracks_genre_df.genre)
return tracks_genre_df
# get genre information for all tracks from the small subset
GENRE_PATH = "fma_metadata/genres.csv"
TRACKS_PATH = "fma_metadata/tracks.csv"
subset = 'small'
small_tracks_genre = track_genre_information(GENRE_PATH, TRACKS_PATH, subset)
然后我们需要函数来创建一个TensorFlow数据集。其思想是在文件名列表上循环,在管道中应用一系列操作,这些操作返回批处理数据集,其中包含一个特征张量和一个标签张量。我们使用TensorFlow内置函数和Python函数(与tf.py_函数,对于在数据管道中使用Python函数非常有用)。这里我只包含从原始音频数据创建数据集的函数,但过程与以频谱图作为特性创建数据集的过程极为相似。
# check the number of songs which are stored in GCS
nb_songs = len(tf.io.gfile.glob(GCS_PATTERN))
shard_size = math.ceil(1.0 * nb_songs / SHARDS)
print("Pattern matches {} songs which will be rewritten as {} .tfrec files containing {} songs each.".format(nb_songs, SHARDS, shard_size))
# functions to create the dataset from raw audio
# define a function to get the label associated with a file path
def get_label(file_path, genre_df=small_tracks_genre):
path = file_path.numpy()
path = path.decode("utf-8")
track_id = int(path.split('/')[-1].split('.')[0].lstrip('0'))
label = genre_df.loc[genre_df.track_id == track_id,'genre_nb'].values[0]
return tf.constant([label])
# define a function that extracts the desired features from a file path
def get_audio(file_path, window_size=window_size):
wav = tf.io.read_file(file_path)
audio = tf.audio.decode_wav(wav, desired_channels=1).audio
filtered_audio = audio[:window_size,:]
return filtered_audio
# process the path
def process_path(file_path, window_size=window_size):
label = get_label(file_path)
audio = get_audio(file_path, window_size)
return audio, label
# parser, wrap around the processing function and specify output shape
def parser(file_path, window_size=window_size):
audio, label = tf.py_function(process_path, [file_path], (tf.float32, tf.int32))
audio.set_shape((window_size,1))
label.set_shape((1,))
return audio, label
filenames = tf.data.Dataset.list_files(GCS_PATTERN, seed=35155) # This also shuffles the images
dataset_1d = filenames.map(parser, num_parallel_calls=AUTO)
dataset_1d = dataset_1d.batch(shard_size)
在GCS上使用TFRecord格式
现在我们有了数据集,我们使用TFRecord格式将其存储在GCS上。这是GPU和TPU推荐使用的格式,因为并行化带来了快速的I/O。其主要思想是tf.Features和tf.Example. 我们将数据集写入这些示例,存储在GCS上。这部分代码应该需要对其他项目进行最少的编辑,除了更改特性类型之外。如果数据已经上传到记录格式一次,则可以跳过此部分。本节中的大部分代码都改编自TensorFlow官方文档以及本教程中有关音频管道的内容。
# write to TFRecord
# need to TFRecord to greatly speed up the I/O process, previously a bottleneck
# functions to create various features
# adapted from https://codelabs.developers.google.com/codelabs/keras-flowers-data/#4
# and https://www.tensorflow.org/tutorials/load_data/tfrecord
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
# writer function
def to_tfrecord(tfrec_filewriter, song, label):
one_hot_class = np.eye(N_CLASSES)[label][0]
feature = {
"song": _float_feature(song.flatten().tolist()), # one song in the list
"class": _int_feature([label]), # one class in the list
"one_hot_class": _float_feature(one_hot_class.tolist()) # variable length list of floats, n=len(CLASSES)
}
return tf.train.Example(features=tf.train.Features(feature=feature))
def write_tfrecord(dataset, GCS_OUTPUT):
print("Writing TFRecords")
for shard, (song, label) in enumerate(dataset):
# batch size used as shard size here
shard_size = song.numpy().shape[0]
# good practice to have the number of records in the filename
filename = GCS_OUTPUT + "{:02d}-{}.tfrec".format(shard, shard_size)
with tf.io.TFRecordWriter(filename) as out_file:
for i in range(shard_size):
example = to_tfrecord(out_file,
song.numpy()[i],
label.numpy()[i])
out_file.write(example.SerializeToString())
print("Wrote file {} containing {} records".format(filename, shard_size))s
一旦这些记录被存储,我们需要其他函数来读取它们。依次处理每个示例,从TFRecord中提取相关信息并重新构造tf.数据集. 这看起来像是一个循环过程(创建一个tf.数据集→作为TFRecord上传到GCS→将TFRecord读入tf.数据集),但这实际上通过简化I/O过程提供了巨大的速度效率。如果I/O是瓶颈,使用GPU或TPU是没有帮助的,这种方法允许我们通过优化数据加载来充分利用它们在训练期间的速度增益。
# function to parse an example and return the song feature and the one-hot class
# adapted from https://codelabs.developers.google.com/codelabs/keras-flowers-data/#4
# and https://www.tensorflow.org/tutorials/load_data/tfrecord
def read_tfrecord_1d(example):
features = {
"song": tf.io.FixedLenFeature([window_size], tf.float32), # tf.string means bytestring
"class": tf.io.FixedLenFeature([1], tf.int64), # shape [] means scalar
"one_hot_class": tf.io.VarLenFeature(tf.float32),
}
example = tf.io.parse_single_example(example, features)
song = example['song']
# song = tf.audio.decode_wav(example['song'], desired_channels=1).audio
song = tf.cast(example['song'], tf.float32)
song = tf.reshape(song, [window_size, 1])
label = tf.reshape(example['class'], [1])
one_hot_class = tf.sparse.to_dense(example['one_hot_class'])
one_hot_class = tf.reshape(one_hot_class, [N_CLASSES])
return song, one_hot_class
# function to load the dataset from TFRecords
def load_dataset_1d(filenames):
# read from TFRecords. For optimal performance, read from multiple
# TFRecord files at once and set the option experimental_deterministic = False
# to allow order-altering optimizations.
option_no_order = tf.data.Options()
option_no_order.experimental_deterministic = False
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTO)
dataset = dataset.with_options(option_no_order)
dataset = dataset.map(read_tfrecord_1d, num_parallel_calls=AUTO)
# ignore potentially corrupted records
dataset = dataset.apply(tf.data.experimental.ignore_errors())
return dataset
准备训练、验证和测试集
重要的是,将数据适当地分割成训练验证测试集(64%-16%-20%),前两个测试集用于优化模型体系结构,后者用于评估模型性能。拆分发生在文件名级别。
# function to create training, validation and testing sets
# adapted from https://colab.sandbox.google.com/notebooks/tpu.ipynb
# and https://codelabs.developers.google.com/codelabs/keras-flowers-data/#4
def create_train_validation_testing_sets(TFREC_PATTERN,
VALIDATION_SPLIT=0.2,
TESTING_SPLIT=0.2):
"""
TFREC_PATTERN: string pattern for the TFREC bucket on GCS
"""
# see which accelerator is available
try: # detect TPUs
tpu = None
tpu = tf.distribute.cluster_resolver.TPUClusterResolver() # TPU detection
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for GPU or multi-GPU machines
print("Number of accelerators: ", strategy.num_replicas_in_sync)
# Configuration
# adapted from https://codelabs.developers.google.com/codelabs/keras-flowers-data/#4
if tpu:
BATCH_SIZE = 16*strategy.num_replicas_in_sync # A TPU has 8 cores so this will be 128
else:
BATCH_SIZE = 32 # On Colab/GPU, a higher batch size does not help and sometimes does not fit on the GPU (OOM)
# splitting data files between training and validation
filenames = tf.io.gfile.glob(TFREC_PATTERN)
testing_split = int(len(filenames) * TESTING_SPLIT)
training_filenames = filenames[testing_split:]
testing_filenames = filenames[:testing_split]
validation_split = int(len(filenames) * VALIDATION_SPLIT)
validation_filenames = training_filenames[:validation_split]
training_filenames = training_filenames[validation_split:]
validation_steps = int(3670 // len(filenames) * len(validation_filenames)) // BATCH_SIZE
steps_per_epoch = int(3670 // len(filenames) * len(training_filenames)) // BATCH_SIZE
return tpu, BATCH_SIZE, strategy, training_filenames, validation_filenames, testing_filenames, steps_per_epoch
# get the batched dataset, optimizing for I/O performance
# follow best practice for shuffling and repeating data
def get_batched_dataset(filenames, load_func, train=False):
"""
filenames: filenames to load
load_func: specific loading function to use
train: Boolean, whether this is a training set
"""
dataset = load_func(filenames)
dataset = dataset.cache() # This dataset fits in RAM
if train:
# Best practices for Keras:
# Training dataset: repeat then batch
# Evaluation dataset: do not repeat
dataset = dataset.repeat()
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.prefetch(AUTO) # prefetch next batch while training (autotune prefetch buffer size)
# should shuffle too but this dataset was well shuffled on disk already
return dataset
# source: Dataset performance guide: https://www.tensorflow.org/guide/performance/datasets
# instantiate the datasets
training_dataset_1d = get_batched_dataset(training_filenames_1d, load_dataset_1d,
train=True)
validation_dataset_1d = get_batched_dataset(validation_filenames_1d, load_dataset_1d,
train=False)
testing_dataset_1d = get_batched_dataset(testing_filenames_1d, load_dataset_1d,
train=False)
模型和训练
最后,我们可以使用kerasapi来构建和测试模型。网上有大量关于如何使用Keras构建模型的信息,所以我不会深入讨论细节,但是这里是使用1D卷积层与池层相结合来从原始音频中提取特征。
# create a CNN model
with strategy.scope():
# create the model
model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=128,
kernel_size=3,
activation='relu',
input_shape=[window_size,1],
name = 'conv1'),
tf.keras.layers.MaxPooling1D(name='max1'),
tf.keras.layers.Conv1D(filters=64,
kernel_size=3,
activation='relu',
name='conv2'),
tf.keras.layers.MaxPooling1D(name='max2'),
tf.keras.layers.Flatten(name='flatten'),
tf.keras.layers.Dense(100, activation='relu', name='dense1'),
tf.keras.layers.Dropout(0.5, name='dropout2'),
tf.keras.layers.Dense(20, activation='relu', name='dense2'),
tf.keras.layers.Dropout(0.5, name='dropout3'),
tf.keras.layers.Dense(8, name='dense3')
])
#compile
model.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
# train the model
logdir = "logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
EPOCHS = 100
raw_audio_history = model.fit(training_dataset_1d, steps_per_epoch=steps_per_epoch,
validation_data=validation_dataset_1d, epochs=EPOCHS,
callbacks=tensorboard_callback)
# evaluate on the test data
model.evaluate(testing_dataset_1d)
最后一点相关信息是关于使用TensorBoard绘制训练和验证曲线。
%load_ext tensorboard %tensorboard --logdir logs/scalars
总结
总之,对同一个机器学习任务进行不同机器学习方法的基准测试是很有启发性的。该项目强调了领域知识和特征工程的重要性,以及标准的、相对容易的机器学习技术(如naivebayes)的威力。过拟合是一个问题,因为与示例数量相比,特性的规模很大,但我相信未来的努力可以帮助缓解这个问题。
我很高兴地看到了在谱图上进行迁移学习的强大表现,并认为我们可以通过使用更多的音乐理论特征来做得更好。然而,如果有更多的数据可用于提取模式,原始音频的深度学习技术确实显示出希望。我们可以设想一个应用程序,其中分类可以直接发生在音频样本上,而不需要特征工程。
作者:Célestin Hermez
本文代码 https://github.com/celestinhermez/music-genre-classification
deephub 翻译组
相关推荐
-

详解tensorflow训练自己的数据集实现CNN图像分类
利用卷积神经网络训练图像数据分为以下几个步骤 1.读取图片文件 2.产生用于训练的批次 3.定义训练的模型(包括初始化参数,卷积.池化层等参数.网络) 4.训练 1 读取图片文件 def get_files(filename): class_train = [] label_train = [] for train_class in os.listdir(filename): for pic in os.listdir(filename+train_class): class_train.app
-
tensorflow 分类损失函数使用小记
多分类损失函数 label.shape:[batch_size]; pred.shape: [batch_size, num_classes] 使用 tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1) - y_true 真实值, y_pred 预测值 - from_logits,我的理解是,如果预测结果经过了softmax(单次预测结果满足和为1)就使用设为`Fal
-
tensorflow 1.0用CNN进行图像分类
tensorflow升级到1.0之后,增加了一些高级模块: 如tf.layers, tf.metrics, 和tf.losses,使得代码稍微有些简化. 任务:花卉分类 版本:tensorflow 1.0 数据:flower-photos 花总共有五类,分别放在5个文件夹下. 闲话不多说,直接上代码,希望大家能看懂:) 复制代码 # -*- coding: utf-8 -*- from skimage import io,transform import glob import os impor
-
详解如何用TensorFlow训练和识别/分类自定义图片
很多正在入门或刚入门TensorFlow机器学习的同学希望能够通过自己指定图片源对模型进行训练,然后识别和分类自己指定的图片.但是,在TensorFlow官方入门教程中,并无明确给出如何把自定义数据输入训练模型的方法.现在,我们就参考官方入门课程<Deep MNIST for Experts>一节的内容(传送门:https://www.tensorflow.org/get_started/mnist/pros),介绍如何将自定义图片输入到TensorFlow的训练模型. 在<Deep M
-
利用TensorFlow训练简单的二分类神经网络模型的方法
利用TensorFlow实现<神经网络与机器学习>一书中4.7模式分类练习 具体问题是将如下图所示双月牙数据集分类. 使用到的工具: python3.5 tensorflow1.2.1 numpy matplotlib 1.产生双月环数据集 def produceData(r,w,d,num): r1 = r-w/2 r2 = r+w/2 #上半圆 theta1 = np.random.uniform(0, np.pi ,num) X_Col1 = np.random.unifo
-
使用TensorFlow实现二分类的方法示例
使用TensorFlow构建一个神经网络来实现二分类,主要包括输入数据格式.隐藏层数的定义.损失函数的选择.优化函数的选择.输出层.下面通过numpy来随机生成一组数据,通过定义一种正负样本的区别,通过TensorFlow来构造一个神经网络来实现二分类. 一.神经网络结构 输入数据:定义输入一个二维数组(x1,x2),数据通过numpy来随机产生,将输出定义为0或1,如果x1+x2<1,则y为1,否则y为0. 隐藏层:定义两层隐藏层,隐藏层的参数为(2,3),两行三列的矩阵,输入数据通过隐藏层之
-
使用tensorflow进行音乐类型的分类
音乐流媒体服务的兴起使得音乐无处不在.我们在上下班的时候听音乐,锻炼身体,工作或者只是放松一下. 这些服务的一个关键特性是播放列表,通常按流派分组.这些数据可能来自出版歌曲的人手工标注.但这并不是一个很好的划分,因为可能是一些艺人想利用一个特定流派的流行趋势.更好的选择是依靠自动音乐类型分类.与我的两位合作者张伟信(Wilson Cheung)和顾长乐(Joy Gu)一起,我们试图比较不同的音乐样本分类方法.特别是,我们评估了标准机器学习和深度学习方法的性能.我们发现特征工程是至关重要的,而领域
-
Tensorflow深度学习使用CNN分类英文文本
目录 前言 源码与数据 源码 数据 train.py 源码及分析 data_helpers.py 源码及分析 text_cnn.py 源码及分析 前言 Github源码地址 本文同时也是学习唐宇迪老师深度学习课程的一些理解与记录. 文中代码是实现在TensorFlow下使用卷积神经网络(CNN)做英文文本的分类任务(本次是垃圾邮件的二分类任务),当然垃圾邮件分类是一种应用环境,模型方法也可以推广到其它应用场景,如电商商品好评差评分类.正负面新闻等. 源码与数据 源码 - data_helpers
-
tensorflow使用神经网络实现mnist分类
本文实例为大家分享了tensorflow神经网络实现mnist分类的具体代码,供大家参考,具体内容如下 只有两层的神经网络,直接上代码 #引入包 import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #引入input_data文件 from tensorflow.examples.tutorials.mnist import input_data #读取文件 mnist = input_data.re
-
tensorflow学习教程之文本分类详析
前言 这几天caffe2发布了,支持移动端,我理解是类似单片机的物联网吧应该不是手机之类的,试想iphone7跑CNN,画面太美~ 作为一个刚入坑的,甚至还没入坑的人,咱们还是老实研究下tensorflow吧,虽然它没有caffe好上手.tensorflow的特点我就不介绍了: 基于Python,写的很快并且具有可读性. 支持CPU和GPU,在多GPU系统上的运行更为顺畅. 代码编译效率较高. 社区发展的非常迅速并且活跃. 能够生成显示网络拓扑结构和性能的可视化图. tensorflow(tf)
-
tensorflow基本操作小白快速构建线性回归和分类模型
目录 tensorflow是非常强的工具,生态庞大 tensorflow提供了Keras的分支 Define tensor constants. Linear Regression 分类模型 本例使用MNIST手写数字 Model prediction: 7 Model prediction: 2 Model prediction: 1 Model prediction: 0 Model prediction: 4 TF 目前发布2.5 版本,之前阅读1.X官方文档,最近查看2.X的文档. te
-
TensorFlow实现随机训练和批量训练的方法
TensorFlow更新模型变量.它能一次操作一个数据点,也可以一次操作大量数据.一个训练例子上的操作可能导致比较"古怪"的学习过程,但使用大批量的训练会造成计算成本昂贵.到底选用哪种训练类型对机器学习算法的收敛非常关键. 为了TensorFlow计算变量梯度来让反向传播工作,我们必须度量一个或者多个样本的损失. 随机训练会一次随机抽样训练数据和目标数据对完成训练.另外一个可选项是,一次大批量训练取平均损失来进行梯度计算,批量训练大小可以一次上扩到整个数据集.这里将显示如何扩展前面的回
-
iOS实现播放远程网络音乐的核心技术点总结
一.前言 这两天做了个小项目涉及到了远程音乐播放,因为第一次做这种音乐项目,边查资料边做,其中涉及到主要技术点有: 如何播放远程网络音乐 如何切换当前正在播放中的音乐资源 如何监听音乐播放的各种状态(播放器状态.播放的进度.缓冲的进度,播放完成) 如何手动操控播放进度 如何在后台模式或者锁屏情况下正常播放音乐 如何在锁屏模式下显示音乐播放信息和远程操控音乐 如果您对一块技术点有兴趣或者正在寻找相关资料,那么本篇或许能提供一些参考或启发. 二. 网络音乐播放的核心技术点 根据自己的经验和查了一些音
-
Mysql支持的数据类型(列类型总结)
一.数值类型 Mysql支持所有标准SQL中的数值类型,其中包括严格数据类型(INTEGER,SMALLINT,DECIMAL,NUMBERIC),以及近似数值数据类型(FLOAT,REAL,DOUBLE PRESISION),并在此基础上进行扩展. 扩展后增加了TINYINT,MEDIUMINT,BIGINT这3种长度不同的整形,并增加了BIT类型,用来存放位数据. 整数类型 字节 范围(有符号) 范围(无符号) 用途 TINYINT
-
网络分类基础
什么是网络? 什么是Internet? 简单的来讲,网络就是在一定的区域内两个或两个以上的计算机以一定的方式连接,以供用户共享文件.程序.数据等资源. Internet,即全球信息网(World Wide Web,简称WWW),是基于超文本(Hypertext)的信息检索工具,它通过超链接把世界各地不同Internet节点上的相关的信息有机地组织在一起,用户只需发出检索请求,它就能自动地进行相应的定位,找到相应的检索信息. 下面就几种常见的网络类型及分类方法作简单的介绍. 按网络的地理位置分类