Spring Boot实战解决高并发数据入库之 Redis 缓存+MySQL 批量入库问题
目录
- 前言
- 架构设计
- 代码实现
- 测试
- 总结
前言
最近在做阅读类的业务,需要记录用户的PV,UV;
项目状况:前期尝试业务阶段;
特点:
快速实现(不需要做太重,满足初期推广运营即可)快速投入市场去运营
收集用户的原始数据,三要素:
谁在什么时间阅读哪篇文章
提到PV,UV脑海中首先浮现特点:
需要考虑性能(每个客户每打开一篇文章进行记录)允许数据有较小误差(少部分数据丢失)
架构设计
架构图:

时序图

记录基础数据MySQL表结构
CREATE TABLE `zh_article_count` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `bu_no` varchar(32) DEFAULT NULL COMMENT '业务编码', `customer_id` varchar(32) DEFAULT NULL COMMENT '用户编码', `type` int(2) DEFAULT '0' COMMENT '统计类型:0APP内文章阅读', `article_no` varchar(32) DEFAULT NULL COMMENT '文章编码', `read_time` datetime DEFAULT NULL COMMENT '阅读时间', `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间', `param1` int(2) DEFAULT NULL COMMENT '预留字段1', `param2` int(4) DEFAULT NULL COMMENT '预留字段2', `param3` int(11) DEFAULT NULL COMMENT '预留字段3', `param4` varchar(20) DEFAULT NULL COMMENT '预留字段4', `param5` varchar(32) DEFAULT NULL COMMENT '预留字段5', `param6` varchar(64) DEFAULT NULL COMMENT '预留字段6', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `uk_zh_article_count_buno` (`bu_no`), KEY `key_zh_article_count_csign` (`customer_id`), KEY `key_zh_article_count_ano` (`article_no`), KEY `key_zh_article_count_rtime` (`read_time`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章阅读统计表';
技术实现方案
SpringBoot
Redis
MySQL
代码实现
完整代码(GitHub,欢迎大家Star,Fork,Watch)
https://github.com/dangnianchuntian/springboot
主要代码展示
Controller
/*
* Copyright (c) 2020. zhanghan_java@163.com All Rights Reserved.
* 项目名称:Spring Boot实战解决高并发数据入库: Redis 缓存+MySQL 批量入库
* 类名称:ArticleCountController.java
* 创建人:张晗
* 联系方式:zhanghan_java@163.com
* 开源地址: https://github.com/dangnianchuntian/springboot
* 博客地址: https://zhanghan.blog.csdn.net
*/
package com.zhanghan.zhredistodb.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import com.zhanghan.zhredistodb.controller.request.PostArticleViewsRequest;
import com.zhanghan.zhredistodb.service.ArticleCountService;
@RestController
public class ArticleCountController {
@Autowired
private ArticleCountService articleCountService;
/**
* 记录用户访问记录
*/
@RequestMapping(value = "/post/article/views", method = RequestMethod.POST)
public Object postArticleViews(@RequestBody @Validated PostArticleViewsRequest postArticleViewsRequest) {
return articleCountService.postArticleViews(postArticleViewsRequest);
}
/**
* 批量将缓存中的数据同步到MySQL(模拟定时任务操作)
*/
@RequestMapping(value = "/post/batch", method = RequestMethod.POST)
public Object postBatch() {
return articleCountService.postBatchRedisToDb();
}
Service
/*
* Copyright (c) 2020. zhanghan_java@163.com All Rights Reserved.
* 项目名称:Spring Boot实战解决高并发数据入库: Redis 缓存+MySQL 批量入库
* 类名称:ArticleCountServiceImpl.java
* 创建人:张晗
* 联系方式:zhanghan_java@163.com
* 开源地址: https://github.com/dangnianchuntian/springboot
* 博客地址: https://zhanghan.blog.csdn.net
*/
package com.zhanghan.zhredistodb.service.impl;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Collectors;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.CollectionUtils;
import com.alibaba.fastjson.JSON;
import com.zhanghan.zhredistodb.controller.request.PostArticleViewsRequest;
import com.zhanghan.zhredistodb.dto.ArticleCountDto;
import com.zhanghan.zhredistodb.mybatis.mapper.XArticleCountMapper;
import com.zhanghan.zhredistodb.service.ArticleCountService;
import com.zhanghan.zhredistodb.util.wrapper.WrapMapper;
import cn.hutool.core.util.IdUtil;
@Service
public class ArticleCountServiceImpl implements ArticleCountService {
private static Logger logger = LoggerFactory.getLogger(ArticleCountServiceImpl.class);
@Autowired
private RedisTemplate<String, String> strRedisTemplate;
private XArticleCountMapper xArticleCountMapper;
@Value("${zh.article.count.redis.key:zh}")
private String zhArticleCountRedisKey;
@Value("#{T(java.lang.Integer).parseInt('${zh..article.read.num:3}')}")
private Integer articleReadNum;
/**
* 记录用户访问记录
*/
@Override
public Object postArticleViews(PostArticleViewsRequest postArticleViewsRequest) {
ArticleCountDto articleCountDto = new ArticleCountDto();
articleCountDto.setBuNo(IdUtil.simpleUUID());
articleCountDto.setCustomerId(postArticleViewsRequest.getCustomerId());
articleCountDto.setArticleNo(postArticleViewsRequest.getArticleNo());
articleCountDto.setReadTime(new Date());
String strArticleCountDto = JSON.toJSONString(articleCountDto);
strRedisTemplate.opsForList().rightPush(zhArticleCountRedisKey, strArticleCountDto);
return WrapMapper.ok();
}
* 批量将缓存中的数据同步到MySQL
public Object postBatchRedisToDb() {
Date now = new Date();
while (true) {
List<String> strArticleCountList =
strRedisTemplate.opsForList().range(zhArticleCountRedisKey, 0, articleReadNum);
if (CollectionUtils.isEmpty(strArticleCountList)) {
return WrapMapper.ok();
}
List<ArticleCountDto> articleCountDtoList = new ArrayList<>();
strArticleCountList.stream().forEach(x -> {
ArticleCountDto articleCountDto = JSON.parseObject(x, ArticleCountDto.class);
articleCountDtoList.add(articleCountDto);
});
//过滤出本次定时任务之前的缓存中数据,防止死循环
List<ArticleCountDto> beforeArticleCountDtoList = articleCountDtoList.stream().filter(x -> x.getReadTime()
.before(now)).collect(Collectors.toList());
if (CollectionUtils.isEmpty(beforeArticleCountDtoList)) {
xArticleCountMapper.batchAdd(beforeArticleCountDtoList);
Integer delSize = beforeArticleCountDtoList.size();
strRedisTemplate.opsForList().trim(zhArticleCountRedisKey, delSize, -1L);
}
}
测试
模拟用户请求访问后台(多次请求)

查看缓存中访问数据
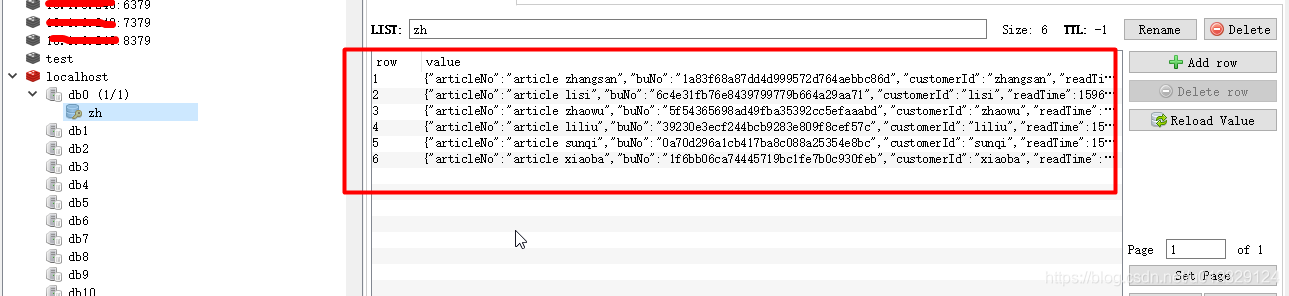
模拟定时任务将缓存中数据同步到DB中
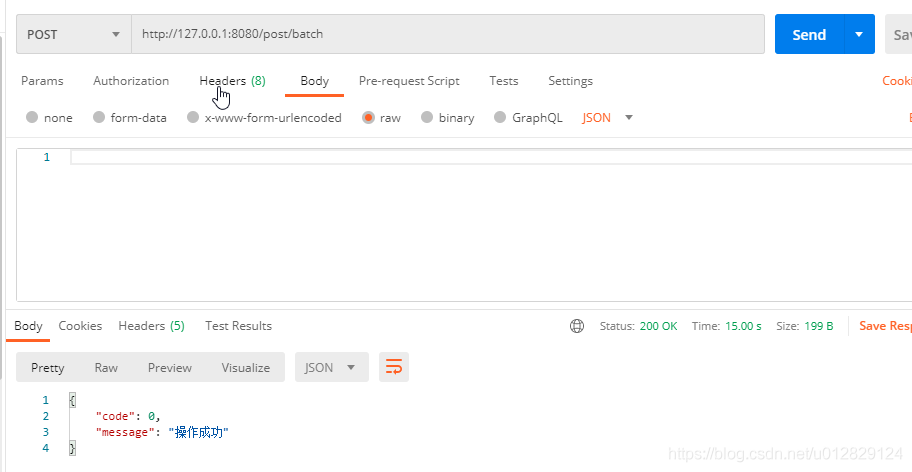
这时查看缓存中的数据已经没了

查看数据库表结构

总结
- 项目中定时任务
- 问演示方便用http代替定时任务调度;实际项目中用XXL-job,参考:定时任务的选型及改造
- 定时任务项目中用redis锁防止并发(定时任务调度端多次调度等),参考:Redis实现计数器—接口防刷—升级版(Redis+Lua)
- 后期运营数据可以从阅读记录表中拉数据进行相关分析
- 访问量大:可以将MySQL中的阅读记录表定时迁移走(MySQL建历史表,MongoDB等)
到此这篇关于Spring Boot实战解决高并发数据入库之 Redis 缓存+MySQL 批量入库的文章就介绍到这了,更多相关Spring Boot高并发数据入库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
spring boot高并发下耗时操作的实现方法
高并发下的耗时操作 高并发下,就是请求在一个时间点比较多时,很多写的请求打过来时,你的服务器承受很大的压力,当你的一个请求处理时间长时,这些请求将会把你的服务器线程耗尽,即你的主线程池里的线程将不会再有空闲状态的,再打过来的请求,将会是502了. 请求流程图 http1 http2 http3 thread1 thread2 thread3 解决方案 使用DeferredResult来实现异步的操作,当一个请求打过来时,先把它放到一个队列时,然后在后台有一个订阅者,有相关主题的消息发过来时,这个
-
Springboot实现高吞吐量异步处理详解(适用于高并发场景)
技术要点 org.springframework.web.context.request.async.DeferredResult<T> 示例如下: 1. 新建Maven项目 async 2. pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaL
-
springboot高并发下提高吞吐量的实现
公司让做一个全文检索的项目,我使用的是elasticsearch.但是对性能有很高的要求,为了解决性能问题,我简直是寝食难安. es(elasticsearch)没有使用分布式,单台的. 开发完测试的时候,查询慢,吞吐量低. 网友们建议用异步--使用Callable来实现.webAsyncTask.Deferred方式等,我一一尝试了之后也没有明显效果,使用压测工具发现使用前后没有一点提升. 尝试这些方法花费了我两天的时间! 在不想使用redis缓存的情况下,我想到了多线程抱着试一试的心态. 没
-

Spring Boot实战解决高并发数据入库之 Redis 缓存+MySQL 批量入库问题
目录 前言 架构设计 代码实现 测试 总结 前言 最近在做阅读类的业务,需要记录用户的PV,UV: 项目状况:前期尝试业务阶段: 特点: 快速实现(不需要做太重,满足初期推广运营即可)快速投入市场去运营 收集用户的原始数据,三要素: 谁在什么时间阅读哪篇文章 提到PV,UV脑海中首先浮现特点: 需要考虑性能(每个客户每打开一篇文章进行记录)允许数据有较小误差(少部分数据丢失) 架构设计 架构图: 时序图 记录基础数据MySQL表结构 CREATE TABLE `zh_article_count`
-
详解Mysql数据库平滑扩容解决高并发和大数据量问题
目录 1 停机方案 2 停写方案 3 平滑扩容之双写方案(中小型数据) 4 平滑扩容之2N方案大数据量问题解决 4.1 扩容问题 4.2 解决方案 4.3 双主架构思想 4.4 环境部署 5 数据库秒级平滑2N扩容实践 5.1 新增数据库VIP 5.2 应用服务增加动态数据源 5.3 解除原双主同步 5.4 安装MariaDB扩容服务器 5.5 增加KeepAlived服务实现高可用 5.6 清理数据并验证 1 停机方案 发布公告 停止服务 离线数据迁移(拆分,重新分配数据) 数据校验 更改配置
-
详解Spring Boot实战之单元测试
本文介绍使用Spring测试框架提供的MockMvc对象,对Restful API进行单元测试 Spring测试框架提供MockMvc对象,可以在不需要客户端-服务端请求的情况下进行MVC测试,完全在服务端这边就可以执行Controller的请求,跟启动了测试服务器一样. 测试开始之前需要建立测试环境,setup方法被@Before修饰.通过MockMvcBuilders工具,使用WebApplicationContext对象作为参数,创建一个MockMvc对象. MockMvc对象提供一组工具
-
实例详解Spring Boot实战之Redis缓存登录验证码
本章简单介绍redis的配置及使用方法,本文示例代码在前面代码的基础上进行修改添加,实现了使用redis进行缓存验证码,以及校验验证码的过程. 1.添加依赖库(添加redis库,以及第三方的验证码库) <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-redis</artifactId> </dependency&
-
详解Spring Boot实战之Rest接口开发及数据库基本操作
本文介绍了Spring Boot实战之Rest接口开发及数据库基本操作,分享给大家 1.修改pom.xml,添加依赖库,本文使用的是mysql <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <
-
如何利用Redis锁解决高并发问题详解
redis技术的使用: redis真的是一个很好的技术,它可以很好的在一定程度上解决网站一瞬间的并发量,例如商品抢购秒杀等活动... redis之所以能解决高并发的原因是它可以直接访问内存,而以往我们用的是数据库(硬盘),提高了访问效率,解决了数据库服务器压力. 为什么redis的地位越来越高,我们为何不选择memcache,这是因为memcache只能存储字符串,而redis存储类型很丰富(例如有字符串.LIST.SET等),memcache每个值最大只能存储1M,存储资源非常有限,十分消耗内
-
PHP解决高并发的优化方案实例
我们通常衡量一个Web系统的吞吐率的指标是QPS(Query Per Second,每秒处理请求数),解决每秒数万次的高并发场景,这个指标非常关键.举个例子,我们假设处理一个业务请求平均响应时间为100ms,同时,系统内有20台Apache的Web服务器,配置MaxClients为500个(表示Apache的最大连接数目). 那么,我们的Web系统的理论峰值QPS为(理想化的计算方式): 20*500/0.1 = 100000 (10万QPS) 咦?我们的系统似乎很强大,1秒钟可以处理完10万的
-
axios解决高并发的方法:axios.all()与axios.spread()的操作
前言: 很多时候,我们可能需要同时调用多个后台接口,就会高并发的问题,一般解决这个问题方法: axios.all和axios.spread ***注意这里的$get是封装的axios方法 //方法一: searchTopic() { return this.$axios({ url:'地址1', method:'方式',//get/post/patch/put/deleted params:{//参数get所以用params.post.put用data } }) } //方法二: searchs
-
Java Spring Boot实战练习之单元测试篇
一.关于JUnit的一些东西 在我们开发Web应用时,经常会直接去观察结果进行测试.虽然也是一种方式,但是并不严谨.作为开发者编写测试代码来测试自己所写的业务逻辑是,以提高代码的质量.降低错误方法的概率以及进行性能测试等.经常作为开发这写的最多就是单元测试.引入spring-boot-starter-testSpringBoot的测试依赖.该依赖会引入JUnit的测试包,也是我们用的做多的单元测试包.而Spring Boot在此基础上做了很多增强,支持很多方面的测试,例如JPA,Mo
-
PHP解决高并发问题(opcache)
php高并发之opcache 今天工作的时候接触到客户的一台服务器,业务逻辑比较简单 .估算pv在120w左右吧,用的是阿里云2c4g的服务器.一大早就开始卡顿了,登陆服务器后查看负载到了八九十. 之后就想办法调整一下吧.突然想起某位前辈说过的:开启opcache吧,真的会变快的. 于是我马上就开始整,过程很简单 1.进入php,ini 搜索opcache . 2,修改对应参数(如下) zend_extension=opcache.so #引入扩展 php7中默认已经装好了 可能是鼓励大家用吧