Python数据预处理常用的5个技巧
目录
- 前言
- 数据集
- 示例 1
- 示例 2
- 示例 3
- 示例 4
- 示例 5
- 总结
前言
我们知道数据是一项宝贵的资产,近年来经历了指数级增长。但是原始数据通常不能立即使用,它需要进行大量清理和转换。
Pandas 是 Python 的数据分析和操作库,它有多种清理数据的方法和函数。在本文中,我将做5个示例来帮助大家掌握数据清理技能。
数据集
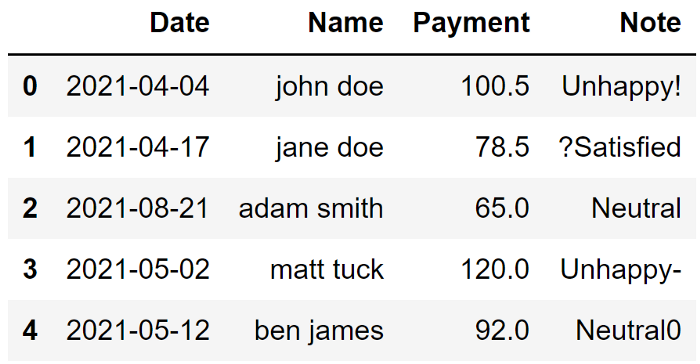
这是一个包含脏数据的示例数据框
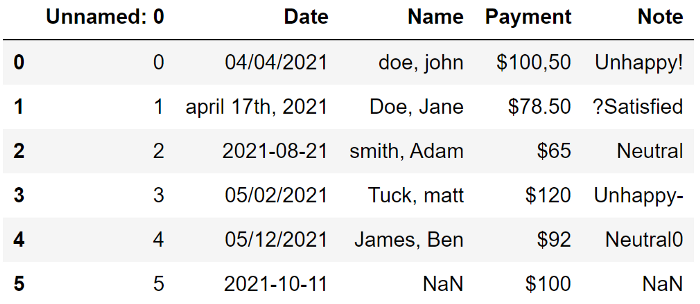
让我们看看可以做些什么来使这个数据集变得干净。
第一列是多余的,应该删除;
Date 没有标准;
Name 写成姓氏、名字,并有大写和小写字母;
Payment 代表一个数量,但它们显示为字符串,需要处理;
在 Note 中,有一些非字母数字应该被删除;
示例 1
删除列是使用 drop 函数的简单操作。除了写列名外,我们还需要指定轴参数的值,因为 drop 函数用于删除行和列。 最后,我们可以使用 inplace 参数来保存更改。
import pandas as pd
df.drop("Unnamed: 0", axis=1, inplace=True)
示例 2
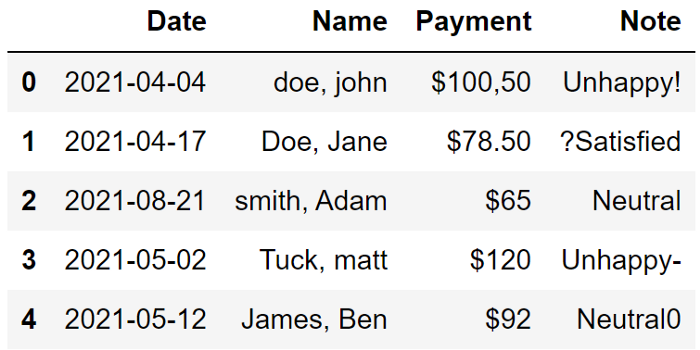
我们有多种选择将日期值转换为适当的格式。一种更简单的方法是使用 astype 函数来更改列的数据类型。
它能够处理范围广泛的值并将它们转换为整洁、标准的日期格式。
df["Date"] = df["Date"].astype("datetime64[ns]")
示例 3
关于名称列,我们首先需要解决如下问题:
首先我们应该用所有大写或小写字母来表示它们。另一种选择是将它们大写(即只有首字母是大写的);
切换姓氏和名字的顺序;
df["Name"].str.split(",", expand=True)
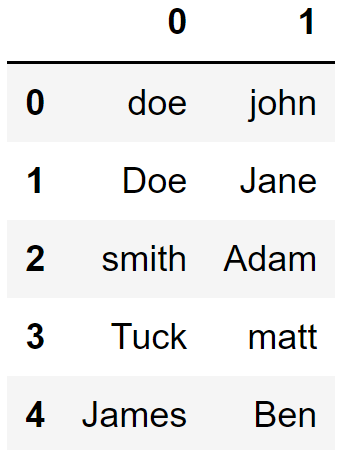
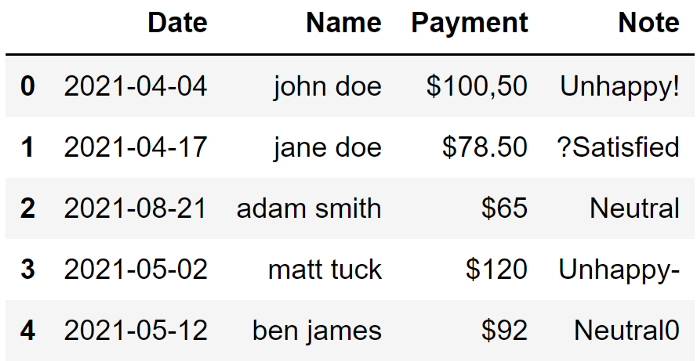
然后,我将取第二列与第一列结合起来,中间有一个空格。最后一步是使用 lower 函数将字母转换为小写。
df["Name"] = (df["Name"].str.split(",", expand=True)[1] + " " + df["Name"].str.split(",", expand=True)[0]).str.lower()
示例 4
支付Payment的数据类型是不能用于数值分析的。在将其转换为数字数据类型(即整数或浮点数)之前,我们需要删除美元符号并将第一行中的逗号替换为点。
我们可以使用 Pandas 在一行代码中完成所有这些操作
df["Payment"] = df["Payment"].str[1:].str.replace(",", ".").astype("float")
示例 5
Note 列中的一些字符也需要删除。在处理大型数据集时,可能很难手动替换它们。
我们可以做的是删除非字母数字字符(例如?、!、-、. 等)。在这种情况下也可以使用 replace 函数,因为它接受正则表达式。
如果我们只想要字母字符,下面是我们如何使用替换函数:
df["Note"].str.replace('[^a-zA-Z]', '')
0 Unhappy
1 Satisfied
2 Neutral
3 Unhappy
4 Neutral
Name: Note, dtype: object
如果我们想要字母和数字(即字母数字),我们需要在我们的正则表达式中添加数字:
df["Note"].str.replace('[^a-zA-Z0-9]', '')
0 Unhappy
1 Satisfied
2 Neutral
3 Unhappy
4 Neutral0
Name: Note, dtype: object
请注意,这次没有删除最后一行中的 0,我只需选择第一个选项。如果我还想在删除非字母数字字符后将字母转换为小写
df["Note"] = df["Note"].str.replace('[^a-zA-Z]', '').str.lower()
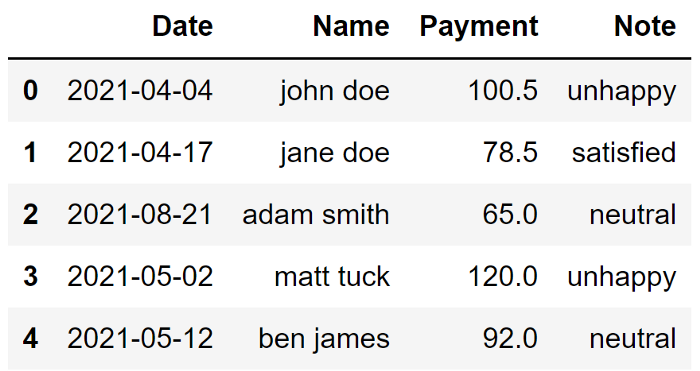
与初始形式相比,数据集看起来要好得多。当然,它是一个简单的数据集,但这些清理操作在处理大型数据集时肯定会对你有所帮助。
总结
到此这篇关于Python数据预处理常用的5个技巧的文章就介绍到这了,更多相关Python数据预处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python----数据预处理代码实例
本文实例为大家分享了Python数据预处理的具体代码,供大家参考,具体内容如下 1.导入标准库 import numpy as np import matplotlib.pyplot as plt import pandas as pd 2.导入数据集 dataset = pd.read_csv('data (1).csv') # read_csv:读取csv文件 #创建一个包含所有自变量的矩阵,及因变量的向量 #iloc表示选取数据集的某行某列:逗号之前的表示行,之后的表示列:冒号表示选取全部
-

python优化数据预处理方法Pandas pipe详解
我们知道现实中的数据通常是杂乱无章的,需要大量的预处理才能使用.Pandas 是应用最广泛的数据分析和处理库之一,它提供了多种对原始数据进行预处理的方法. import numpy as np import pandas as pd df = pd.DataFrame({ "id": [100, 100, 101, 102, 103, 104, 105, 106], "A": [1, 2, 3, 4, 5, 2, np.nan, 5], "B":
-
使用Python制作一个数据预处理小工具(多种操作一键完成)
在我们平常使用Python进行数据处理与分析时,在import完一大堆库之后,就是对数据进行预览,查看数据是否出现了缺失值.重复值等异常情况,并进行处理. 本文将结合GUI工具PySimpleGUI,来讲解如何制作一款属于自己的数据预处理小工具,让这个过程也能够自动化!最终效果如下 本文将分为三部分讲解: 制作GUI界面 数据处理讲解 打包与测试 主要涉及将涉及以下模块: PySimpleGUI pandas matplotlib 一.GUI界面制作 思路 老规矩,先讲思路再上代码,首先还是说一
-
Python数据预处理常用的5个技巧
目录 前言 数据集 示例 1 示例 2 示例 3 示例 4 示例 5 总结 前言 我们知道数据是一项宝贵的资产,近年来经历了指数级增长.但是原始数据通常不能立即使用,它需要进行大量清理和转换. Pandas 是 Python 的数据分析和操作库,它有多种清理数据的方法和函数.在本文中,我将做5个示例来帮助大家掌握数据清理技能. 数据集 这是一个包含脏数据的示例数据框 让我们看看可以做些什么来使这个数据集变得干净. 第一列是多余的,应该删除: Date 没有标准: Name 写成姓氏.名字,并有大
-
Python数据预处理之数据规范化(归一化)示例
本文实例讲述了Python数据预处理之数据规范化.分享给大家供大家参考,具体如下: 数据规范化 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析. 数据规范化方法主要有: - 最小-最大规范化 - 零-均值规范化 数据示例 代码实现 #-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normali
-
python数据预处理方式 :数据降维
数据为何要降维 数据降维可以降低模型的计算量并减少模型运行时间.降低噪音变量信息对于模型结果的影响.便于通过可视化方式展示归约后的维度信息并减少数据存储空间.因此,大多数情况下,当我们面临高维数据时,都需要对数据做降维处理. 数据降维有两种方式:特征选择,维度转换 特征选择 特征选择指根据一定的规则和经验,直接在原有的维度中挑选一部分参与到计算和建模过程,用选择的特征代替所有特征,不改变原有特征,也不产生新的特征值. 特征选择的降维方式好处是可以保留原有维度特征的基础上进行降维,既能满足后续数据
-
python数据预处理 :数据共线性处理详解
何为共线性: 共线性问题指的是输入的自变量之间存在较高的线性相关度.共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间 共线性产生原因: 变量出现共线性的原因: 数据样本不够,导致共线性存在偶然性,这其实反映了缺少数据对于数据建模的影响,共线性仅仅是影响的一部分 多个变量都给予时间有共同或相反的演变趋势,例如春节期间的网络销售量和销售额都相对与正常时间有下降趋势. 多个变量存在一定的推移关系,但总体上变量间的趋势一致,只是发生的时间点不一致,例如广告费用和销售
-
python数据预处理之将类别数据转换为数值的方法
在进行python数据分析的时候,首先要进行数据预处理. 有时候不得不处理一些非数值类别的数据,嗯, 今天要说的就是面对这些数据该如何处理. 目前了解到的大概有三种方法: 1,通过LabelEncoder来进行快速的转换: 2,通过mapping方式,将类别映射为数值.不过这种方法适用范围有限: 3,通过get_dummies方法来转换. import pandas as pd from io import StringIO csv_data = '''A,B,C,D 1,2,3,4 5,6,,
-
python数据预处理 :数据抽样解析
何为数据抽样: 抽样是数据处理的一种基本方法,常常伴随着计算资源不足.获取全部数据困难.时效性要求等情况使用. 抽样方法: 一般有四种方法: 随机抽样 直接从整体数据中等概率抽取n个样本.这种方法优势是,简单.好操作.适用于分布均匀的场景:缺点是总体大时无法一一编号 系统抽样 又称机械.等距抽样,将总体中个体按顺序进行编号,然后计算出间隔,再按照抽样间隔抽取个体.优势,易于理解.简便易行.缺点是,如有明显分布规律时容易产生偏差. 群体抽样 总体分群,在随机抽取几个小群代表总体.优点是简单易行.便
-
python数据预处理 :样本分布不均的解决(过采样和欠采样)
何为样本分布不均: 样本分布不均衡就是指样本差异非常大,例如共1000条数据样本的数据集中,其中占有10条样本分类,其特征无论如何你和也无法实现完整特征值的覆盖,此时属于严重的样本分布不均衡. 为何要解决样本分布不均: 样本分部不均衡的数据集也是很常见的:比如恶意刷单.黄牛订单.信用卡欺诈.电力窃电.设备故障.大企业客户流失等. 样本不均衡将导致样本量少的分类所包含的特征过少,很难从中提取规律,即使得到分类模型,也容易产生过度依赖于有限的数量样本而导致过拟合问题,当模型应用到新的数据上时,模型的
-
python数据预处理之数据标准化的几种处理方式
何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析.数据标准化也就是统计数据的指数化.数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面.数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果.数据无量纲化处理主要解决数据的可比性. 几种标准化方法: 归一化Max-Min min-max标准化方
-
Python数据可视化常用4大绘图库原理详解
今天我们就用一篇文章,带大家梳理matplotlib.seaborn.plotly.pyecharts的绘图原理,让大家学起来不再那么费劲! 1. matplotlib绘图原理 关于matplotlib更详细的绘图说明,大家可以参考下面这篇文章,相信你看了以后一定学得会. matplotlib绘图原理:http://suo.im/678FCo 1)绘图原理说明 通过我自己的学习和理解,我将matplotlib绘图原理高度总结为如下几步: 导库;创建figure画布对象;获取对应位置的axes坐标