js通过正则匹配没有内容的空标签
js 如何正则匹配没有内容的空标签并移除掉?
例如
<span></span>
<p></p>
等等
正则
/<([a-z]+?)(?:\s+?[^>]*?)?>\s*?<\/\1>/ig
html='<div id="fixedTools" class="hidden-xs hidden-sm">'+ '\n <a id="backtop" class="hidden border-bottom" href="#" rel="external nofollow" ></a>'+ '\n'+ '\n <div class="qrcodeWraper">'+ '\n <a href="/app#qrcode" rel="external nofollow" ><span class="glyphicon glyphicon-qrcode"></span></a>'+ '\n <img id="qrcode" class="border" alt="sf-wechat" src="https://sf-static.b0.upaiyun.com/v-581fe7b0/page/img/app/appQrcode.png">'+ '\n'+ '\n <p class="qrcode-text"></p>'+ '\n </div>'+ '\n</div>' ptn=/<([a-z]+?)(?:\s+?[^>]*?)?>\s*?<\/\1>/ig s = html.replace(ptn,'') console.log(s)
通过在线测试工具

如果考虑将没有style的span去掉
有span的就留下来
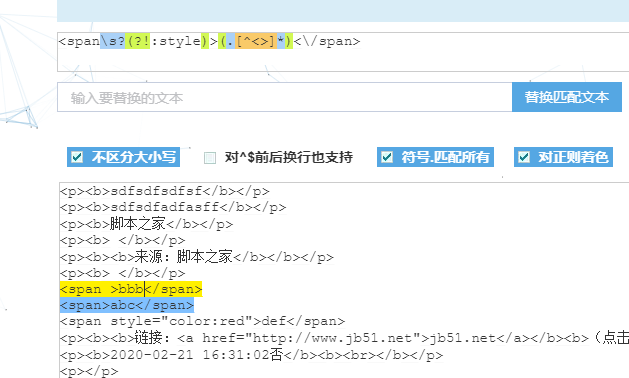
因为默认编辑器中,span没有样式的没有必要
str=str.replace(/<span\s*?(?!:style)>(.[^<>]*)<\/span>/ig,"$1");
先看下面的位置
零宽断言
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧:
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\d)\d{3})+\b,用它对1234567890进行查找时结果是234567890。
下面这个例子同时使用了这两种断言:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
负向零宽断言
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?例如,如果我们想查找这样的单词--它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:
\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的单词。但是如果多做测试(或者你思维足够敏锐,直接就观察出来了),你会发现,如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错。这是因为[^u]总要匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的\w*\b将会匹配下一个单词,于是\b\w*q[^u]\w*\b就能匹配整个Iraq fighting。负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:\b\w*q(?!u)\w*\b。
零宽度负预测先行断言(?!exp),断言此位置的后面不能匹配表达式exp。例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b匹配不包含连续字符串abc的单词。
同理,我们可以用(?<!exp),零宽度负回顾后发断言来断言此位置的前面不能匹配表达式exp:(?<![a-z])\d{7}匹配前面不是小写字母的七位数字。
一个更复杂的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(?<=<(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。
这个解读
1、<span后面的/s*? 主要是考虑<span >与<span>都考虑在内
\s匹配空字符*表示多个空字符都可以,?是表示前面的可有可无。
2、(?!:style) 表示右侧不能有style的才可以匹配,因为有的肯定有用。而且不获取,所以这个括号不是$1
3、(.[^<>]*) 就是匹配<span></span>中间的数据了。
这两天刚开始研究这个,写了好几个正则,先分享出来,看大家能看懂吗
//加强替换主要是考虑多个br的问题
function doRepAdvance(s){
var str=s.replace(/<p><br type="_moz">\s*?<\/p>/ig,"");
str=str.replace(/<p>\s*<br type="_moz">\s*<\/p>/ig, "");
str=str.replace(/<p>\s*?<br\s?\/?>\s*?<\/p>/ig, "");
str=str.replace(/<p>(\s|\ \;| | |\xc2\xa0)*<\/p>/ig, "");
str=str.replace(/<p>\s*?<\/p>/ig,"");
str=str.replace(/<p> <\/p>/ig,"");
str=str.replace(/<br type="_moz">\n <\/p>/ig, "</p>");
str=str.replace(/<br type="_moz">\s*?<\/p>/ig, "</p>");
str=str.replace(/<br\s?\/?>\s*?<\/p>/ig, "</p>");
str=str.replace(/<br \/>\n <\/p>/ig, "</p>");
str=str.replace(/<br>\n <\/p>/ig, "</p>");
//多个br
str=str.replace(/(<br type="_moz">\s*)+<\/p>/ig, "</p>");
str=str.replace(/(<br\s?\/?>\s*)+<\/p>/ig, "</p>");
//空标签
str=str.replace(/<p style=["'].[^<>]*["']>/ig, "<p>");
str=str.replace(/<span style="background-color: initial;">/ig, "<span>");
//没有style的span去掉
str=str.replace(/<span\s*?(?!:style)>(.[^<>]*)<\/span>/ig,"$1");
str=str.replace(/<([a-z]+?)(?:\s+?[^>]*)?>(\s| )*?<\/\1>/ig, "");
//str=str.replace(/<([a-z]+?)(?:\s+?[^>]*)?>\s*?<\/\1>/ig, "");
return str;
}
上面都是一些好东西,具体的自己研究吧。
相关推荐
-
js通过正则匹配没有内容的空标签
js 如何正则匹配没有内容的空标签并移除掉? 例如 <span></span> <p></p> 等等 正则 /<([a-z]+?)(?:\s+?[^>]*?)?>\s*?<\/\1>/ig html='<div id="fixedTools" class="hidden-xs hidden-sm">'+ '\n <a id="backtop" clas
-

js正则匹配markdown里的图片标签的实现
其实前端后端需要将markdown文本转换为html文本都有相应的库,几句代码就ok,但有时我们又必须获取到markdown里的某个标签来进行相应的转换,有几种办法,可以从已经转换好的html文本里获取,还有的就是直接从markdown文本里获取,这里说的是第二种. 1. 一个markdown里只有一个图片的情况 const str = "asddsadasdasddasd"; //一段markdown文本,包含一个图片""
-
JS实现仿新浪微博发布内容为空时提示功能代码
本文实例讲述了JS实现仿新浪微博发布内容为空时提示功能.分享给大家供大家参考.具体如下: 这里使用JavaScript模拟新浪微博的一个功能,在发布微博的内容为空时,文本框提醒用户这里没有输入内容,本功能让人感觉网页很智能,在和你对话一样,很人性化.本特效引用了一个外部了JS封装类,你可下载到本地使用. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-fsina-info-submit-empty-style-codes/ 具体代码如下:
-
js实现正则匹配中文标点符号的方法
本文实例讲述了js正则匹配中文标点符号的方法.分享给大家供大家参考,具体如下: 运行效果截图如下: 具体代码如下: <html> <head> <meta http-equiv="content-type" content="text/html;charset=utf-8"> <title>js正则匹配中文标点符号</title> <head> <body> <input ty
-
java正则匹配HTML中a标签里的中文字符示例
本文实例讲述了java正则匹配HTML中a标签里的中文字符.分享给大家供大家参考,具体如下: 今天群里一位朋友问到了一个正则表达式的问题,有如下内容: <a href='www.baidu.comds=id32434#comment'rewr>特432</a> 453543 <a guhll,,l>a1特123你好123吗?</a> <a href=id=32434#comment'ewrer>特2</a> <a>标签中的
-
MongoDB查询之高级操作详解(多条件查询、正则匹配查询等)
MongoDB查询之高级操作 语法介绍 MongoDB查询文档使用find()方法,同时find()方法以非结构化的方式来显示所有查询到的文档. -- 1.基本语法 db.collection.find(query, projection) -- 返回所有符合查询条件的文档 db.collection.findOne(query, projection) -- 返回第一个符合查询条件的文档 -- query:可选,查询条件操作符,用于指定查询条件 -- projection:可选,投影操作符,用
-
ORACLE正则匹配查询LIKE查询多个值检索数据库对象
字符串’^198[0-9]$’可以匹配‘1980-1989’,如果希望统计出公司那些员工是80年-89年入职的,就可以使用如下的SQL语句: select * from emp e where regexp_like(to_char( e.hiredate,'yyyy'),'^198[0-9]$'); 正则表达式中常用到的元数据(metacharacter)如下: ^ 匹配字符串的开头位置. $ 匹配支付传的结尾位置. * 匹配该字符前面的一个字符0次,1次或者多次出现.例如52*oracle
-
JS正则匹配中文的方法示例
本文实例讲述了JS正则匹配中文的方法.分享给大家供大家参考,具体如下: 需求:使用JS正则的方式将字符串 "[微笑][撇嘴][发呆][得意][流泪]" 中的汉字进行匹配输出. 示例代码: <script> var pattern1 = /[\u4e00-\u9fa5]+/g; var pattern2 = /\[[\u4e00-\u9fa5]+\]/g; var contents = "[微笑][撇嘴][发呆][得意][流泪]"; content = c
-
JS正则匹配URL网址的方法(可匹配www,http开头的一切网址)
本文实例讲述了JS正则匹配URL网址的方法.分享给大家供大家参考,具体如下: 最强的匹配网址-url的正则表达式:匹配www,http开头的一切网址 直接插入正则表达式: [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? 完整的js方法: function isURL(domain) { var name = /[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z
-
JS不用正则验证输入的字符串是否为空(包含空格)的实现代码
在项目中需要验证输入的字符串是否为空,包括空格,不太喜欢使用正则,所以就想到了js的indexOf函数,indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置,如果要检索的字符串值没有出现,则该方法返回 -1. 语法:stringObject.indexOf(searchvalue,fromindex),searchvalue必需,fromindex:可选参数,在字符串中开始检索的位置.它的合法取值是 0 到 stringObject.length - 1.如省略该参数,则将从