Python sklearn库实现PCA教程(以鸢尾花分类为例)
PCA简介
主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。
基本步骤:

具体实现
我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布。样本数据结构如下图:
其中样本总数为150,鸢尾花的类别有三种,分别标记为0,1,2
代码
import matplotlib.pyplot as plt #加载matplotlib用于数据的可视化 from sklearn.decomposition import PCA #加载PCA算法包 from sklearn.datasets import load_iris data=load_iris() y=data.target x=data.data pca=PCA(n_components=2) #加载PCA算法,设置降维后主成分数目为2 reduced_x=pca.fit_transform(x)#对样本进行降维 red_x,red_y=[],[] blue_x,blue_y=[],[] green_x,green_y=[],[] for i in range(len(reduced_x)): if y[i] ==0: red_x.append(reduced_x[i][0]) red_y.append(reduced_x[i][1]) elif y[i]==1: blue_x.append(reduced_x[i][0]) blue_y.append(reduced_x[i][1]) else: green_x.append(reduced_x[i][0]) green_y.append(reduced_x[i][1]) #可视化 plt.scatter(red_x,red_y,c='r',marker='x') plt.scatter(blue_x,blue_y,c='b',marker='D') plt.scatter(green_x,green_y,c='g',marker='.') plt.show()
结果图
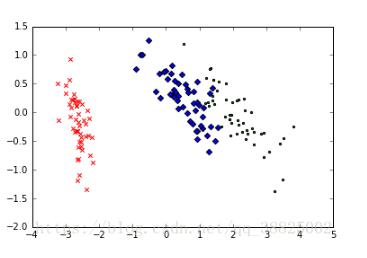
知识拓展:python sklearn PCA 实例代码-主成分分析
python sklearn decomposition PCA 主成分分析
主成分分析(PCA)
1、主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,
通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理
2、PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。
主成分能够尽可能保留原始数据的信息
3、概念
方差:用来度量一组数据的分散程度
协方差:用来度量两个变量之间的线性相关性程度,若两个变量的协议差为0,二者线性无关
协方差矩阵:矩阵的特征向量是描述数据集结构的非零向量,?? ⃗=?? ⃗
特征向量和特征值:? ⃗ 特征向量,?是特征值
4、提取:
矩阵的主成分是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分
5、原理:
1、对所有样本进行中心化:xi-(x1+x2…xm)/m
2、计算样本的协方差矩阵X(X.T)
3、对协方差矩阵X(X.T)做特征值分解
4、取最大的d个特征值所对应的特征向量w1,w2…wd
输出投影矩阵W=(w1,w2,…,wd)
6、参数说明
sklearn.decomposition.PCA(n_components=None,copy=True,whithen=False,svd_solver=‘auto',tol=0.0,
iterated_power=‘auto',random_state=None)
n_components:指定主成分的个数,即降维后数据的维度
svd_slover:设置特征值分解的方法:‘full',‘arpack',‘randomized'
PCA实现高维度数据可视化 实例
目标:
已知鸢尾花数据是4维的,共三类样本,使用PCA实现对鸢尾花数据进行降维,实现在二维平面上的可视化
实例程序编写
import matplotlib.pyplot as plt import sklearn.decomposition as dp from sklearn.datasets.base import load_iris x,y=load_iris(return_X_y=True) #加载数据,x表示数据集中的属性数据,y表示数据标签 pca=dp.PCA(n_components=2) #加载pca算法,设置降维后主成分数目为2 reduced_x=pca.fit_transform(x) #对原始数据进行降维,保存在reduced_x中 red_x,red_y=[],[] blue_x,blue_y=[],[] green_x,green_y=[],[] for i in range(len(reduced_x)): #按鸢尾花的类别将降维后的数据点保存在不同的表表中 if y[i]==0: red_x.append(reduced_x[i][0]) red_y.append(reduced_x[i][1]) elif y[i]==1: blue_x.append(reduced_x[i][0]) blue_y.append(reduced_x[i][1]) else: green_x.append(reduced_x[i][0]) green_y.append(reduced_x[i][1]) plt.scatter(red_x,red_y,c='r',marker='x') plt.scatter(blue_x,blue_y,c='b',marker='D') plt.scatter(green_x,green_y,c='g',marker='.') plt.show()
以上这篇Python sklearn库实现PCA教程(以鸢尾花分类为例)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
sklearn+python:线性回归案例
使用一阶线性方程预测波士顿房价 载入的数据是随sklearn一起发布的,来自boston 1993年之前收集的506个房屋的数据和价格.load_boston()用于载入数据. from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import time from sklearn.linear_model import LinearRegression bosto
-
K最近邻算法(KNN)---sklearn+python实现方式
k-近邻算法概述 简单地说,k近邻算法采用测量不同特征值之间的距离方法进行分类. k-近邻算法 优点:精度高.对异常值不敏感.无数据输入假定. 缺点:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. k-近邻算法(kNN),它的工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标
-
使用sklearn进行对数据标准化、归一化以及将数据还原的方法
在对模型训练时,为了让模型尽快收敛,一件常做的事情就是对数据进行预处理. 这里通过使用sklearn.preprocess模块进行处理. 一.标准化和归一化的区别 归一化其实就是标准化的一种方式,只不过归一化是将数据映射到了[0,1]这个区间中. 标准化则是将数据按照比例缩放,使之放到一个特定区间中.标准化后的数据的均值=0,标准差=1,因而标准化的数据可正可负. 二.使用sklearn进行标准化和标准化还原 原理: 即先求出全部数据的均值和方差,再进行计算. 最后的结果均值为0,方差是1,从公
-
Python sklearn库实现PCA教程(以鸢尾花分类为例)
PCA简介 主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等.矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推. 基本步骤: 具体实现 我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布.样本数据结构如下图: 其中样本总数为150
-

一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
python扩展库numpy入门教程
目录 一.numpy是什么? 二.numpy数组 2.1 数组使用 2.2 创建数组 1. 使用empty创建空数组 2. 使用arange函数创建 3. 使用zeros函数生成数组 4. ones函数生成数组 5. diag函数生成对角矩阵 6. N维数组 2.3 访问数组元素 三.了解矩阵 3.1 广播 一.numpy是什么? 扩展库numpy是Python支持科学计算的重要扩展库,是数据分析和科学计算领域如scipy.pandas.sklearn 等众多扩展库中的必备扩展库之一,提供了强大
-
Python 机器学习库 NumPy入门教程
NumPy是一个Python语言的软件包,它非常适合于科学计算.在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础库. 本文是对它的一个入门教程. 介绍 NumPy是一个用于科技计算的基础软件包,它是Python语言实现的.它包含了: 强大的N维数组结构 精密复杂的函数 可集成到C/C++和Fortran代码的工具 线性代数,傅里叶变换以及随机数能力 除了科学计算的用途以外,NumPy也可被用作高效的通用数据的多维容器.由于它适用于任意类型的数据,这使得NumPy可以无缝和
-
Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Python 数据处理库 pandas进阶教程
前言 本文紧接着前一篇的入门教程,会介绍一些关于pandas的进阶知识.建议读者在阅读本文之前先看完pandas入门教程. 同样的,本文的测试数据和源码可以在这里获取: Github:pandas_tutorial. 数据访问 在入门教程中,我们已经使用过访问数据的方法.这里我们再集中看一下. 注:这里的数据访问方法既适用于Series,也适用于DataFrame. 基础方法:[]和. 这是两种最直观的方法,任何有面向对象编程经验的人应该都很容易理解.下面是一个代码示例: # select_da
-
python sklearn库实现简单逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Reduction).分类(Classfication).聚类(Clustering)等方法.当我们面临机器学习问题时,便可根据下图来选择相应的方法. Sklearn具有以下特点: 简单高效的数据挖掘和数据分析工具 让每个人能够在复杂环境中重复使用 建立NumPy.Scipy.MatPlotLib之上 代
-
音频处理 windows10下python三方库librosa安装教程
librosa是处理音频库里的opencv,使用python脚本研究音频,先安装三方库librosa. 如下通过清华镜像源安装librosa: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple librosa D:\D00_Python3\D00A2_python3.7.3\install>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple librosa Looking
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
Python sklearn库三种常用编码格式实例
目录 OneHotEncoder独热编码实例 LabelEncoder标签编码实例 OrdinalEncoder特征编码实例 OneHotEncoder独热编码实例 class sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error') 目的:将分类要素编码为one-hot数字数组